From RAG to Provenance: How We Realized Vector Alone Is Not Memory.
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
In the previous article, we explored an uncomfortable observation: SDLC does not really have memory.
Not because we fail to write documentation. Not because Jira is empty. Not because meeting notes disappear.
We lose memory because we lose causality. Decisions are made, risks are discussed, assumptions are formed, action items are assigned, and yet months later, when something breaks or a strategic pivot happens, we cannot reconstruct the chain of reasoning that brought us there. We retrieve fragments, but we cannot trace the lineage.
That is where the idea of Provenance entered the conversation. Not as another documentation practice, and not as an AI trick, but as something more structural — a way to preserve the causal DNA of delivery. But once we say “we need memory”, a practical question immediately follows: “What kind of data model does real SDLC memory require?”
And this is exactly where most teams stop too early.
The Seductive Comfort of Vector Memory
The modern instinct is clear. We take all available content — meeting notes, Jira tickets, Confluence pages, design docs. We split them into chunks, embed them into vectors, store them in pgvector, and then retrieve relevant fragments using semantic similarity. We wrap it with an LLM, and suddenly, we have something that feels intelligent.
It works. It feels magical. It retrieves context faster than any human could. But over time, something starts to feel incomplete.
Because vector search answers only one type of question: “What text looks similar to my query?”
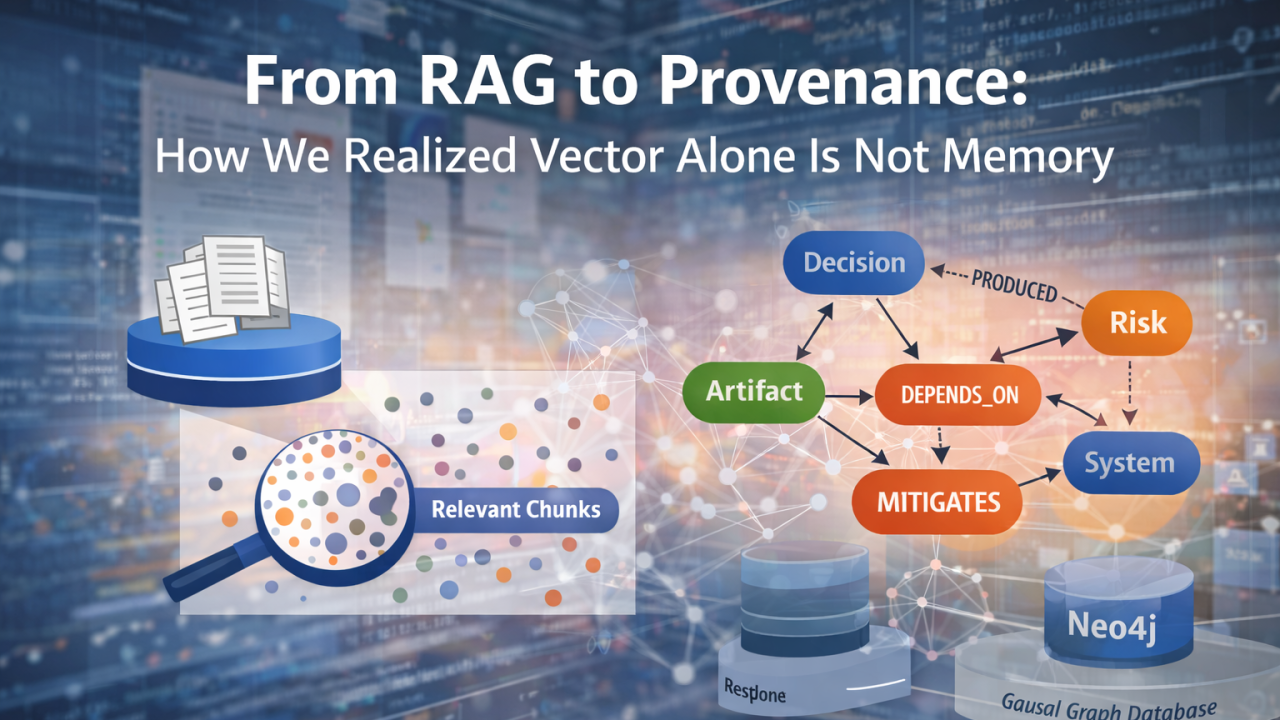
Similarity, however, is not memory. When billing fails in March, and someone asks, “Why did this happen?”, semantic similarity can retrieve fragments mentioning billing and March. But it cannot tell you which decision changed the billing logic, whether that decision superseded a previous one, which system dependency was affected, or which mitigation was never implemented.
Vectors give you relevance. They do not give you causality. And delivery failures are almost always causal.
The Moment We Realized We Needed a Graph
The shift happened when we reframed the problem. Instead of asking, “How do we retrieve documents?”, we asked, “How do we preserve the structure of reasoning?”
That question changes everything.
We stopped thinking in terms of paragraphs and started thinking in terms of entities.
- A meeting is not just text. It is an event that produces decisions.
- A decision is not just a sentence. It affects systems.
- A risk is not a bullet point. It is something that may or may not be mitigated by actions.
- An action is not just a task. It modifies the state of the system.
Suddenly, the memory model stopped looking like a document store and started looking like a graph.
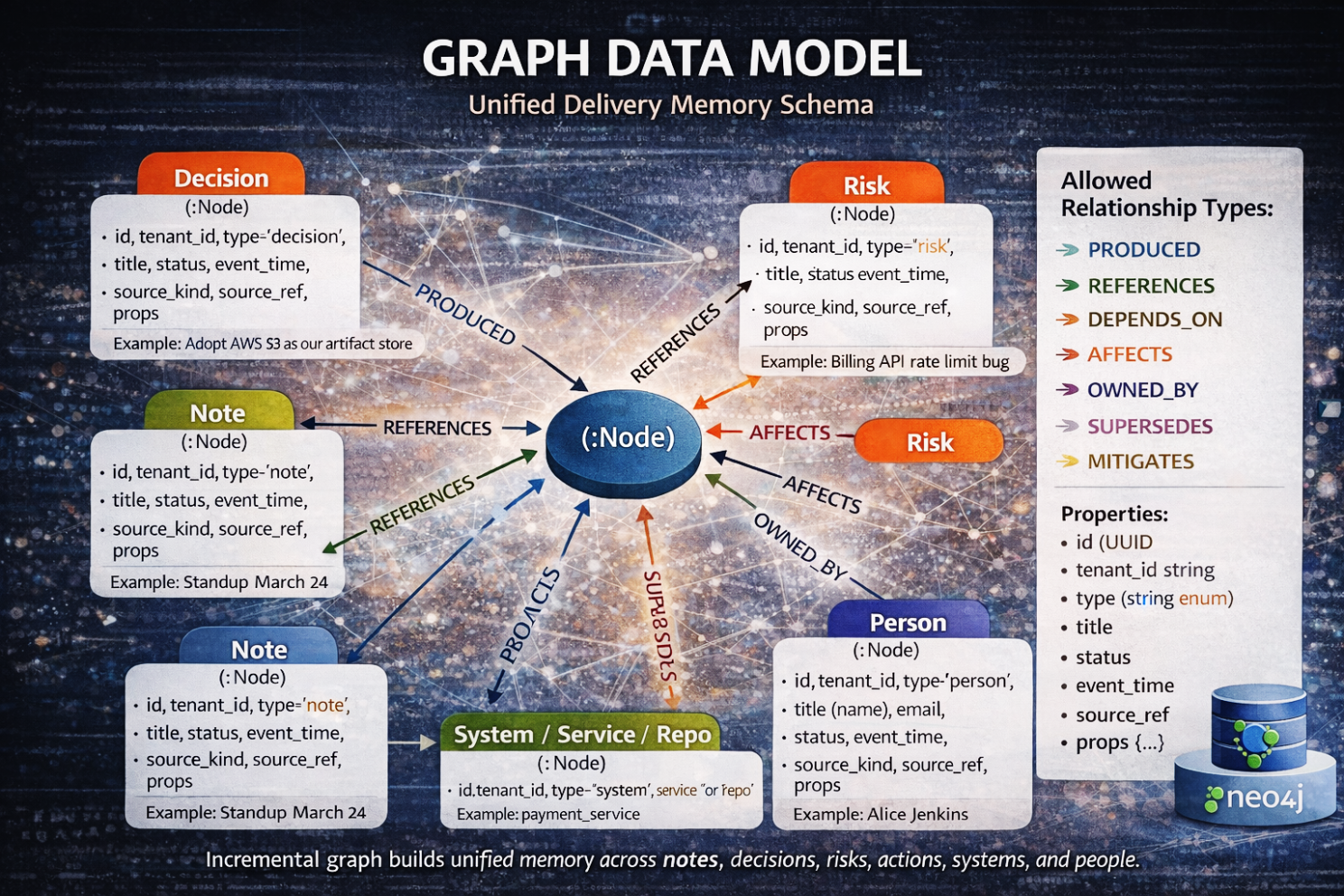
We introduced canonical nodes — first-class entities that exist independently of any single document. Notes, decisions, risks, action items, artifacts, systems, people — each became a stable object with identity. They are stored in Postgres as dm_node, not as embedded text.
Then we introduced provenance edges — directional relationships that capture meaning.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
These are not hyperlinks. They are causal statements.
And at that point, something subtle but powerful happened: memory stopped being textual and became structural.

Why Vector and Graph Both Matter
It would be tempting to move everything into a graph database and declare victory. But that would be incomplete.
We still need vectors. Because when a user asks a question, we don’t know where to start. We need a semantic signal to identify relevant regions of the knowledge space. That is what pgvector gives us. It helps us find the most relevant chunks quickly and efficiently.
But once we find those chunks, the graph takes over. From the seed nodes identified via vector search, we expand the provenance graph using Neo4j. We traverse relationships about who produced this decision, what it affects, what it supersedes, what risk it mitigates, and what depends on it. Suddenly, the answer is not just similar text fragments, but a reconstructed causal neighborhood.
Vector gives us the entry point. The graph gives us the explanation. Together, they form something much closer to organizational memory than either could alone.
Building Memory Incrementally, Like Neural Reinforcement
One of the most important architectural decisions was this: the graph must be global, not per document.
Every ingestion does not create an isolated island. Instead, it modifies and strengthens a shared memory.
When a new note references an existing system, we reuse that node. When two meetings produce the same decision in slightly different words, we normalize and reconnect them. When an action item mitigates a risk that has already been discussed before, we don’t create another risk; we reinforce the connection.
Over time, the graph becomes denser. Edges gain confidence. Repeated references increase support counts. The delivery memory becomes more coherent.
It is not machine learning in the classical sense, but structurally it resembles reinforcement. The more often something is mentioned, linked, or acted upon, the stronger its structural presence becomes.
This is how SDLC memory starts to feel less like documentation and more like cognition.

Retrieval as Structured Conversation
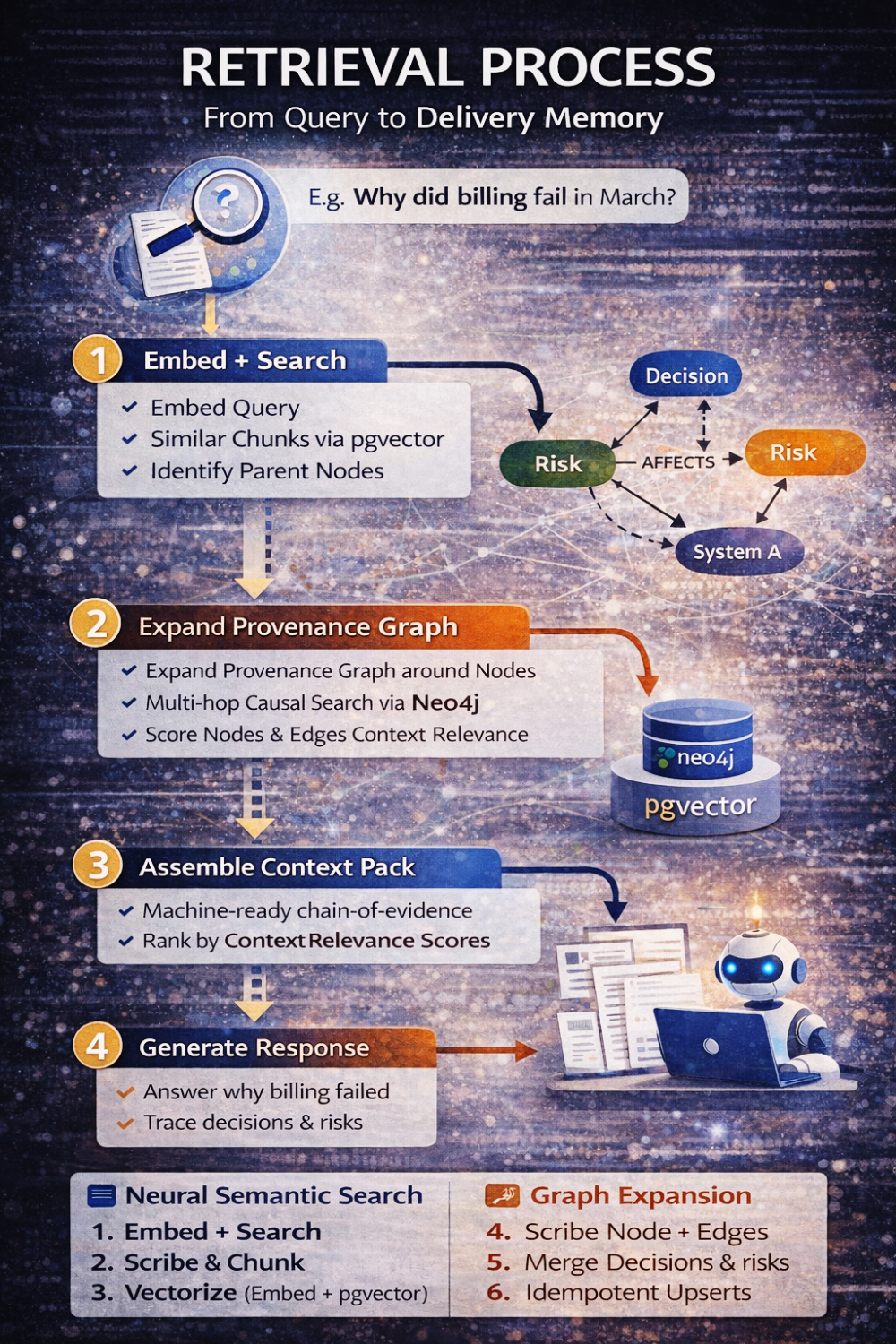
When someone now asks, “Why did billing break in March?”, the system does not simply retrieve text. It performs a structured conversation between two models.
First, it embeds the query and retrieves semantically relevant chunks. Then it identifies the parent nodes of those chunks. From there, it expands the provenance graph up to a defined depth, constrained by relationship types and tenant boundaries. It assembles a context pack that includes not only relevant text but also the causal structure around it — decisions, risks, actions, supersession chains. Only then does the LLM step in, and even then, it is constrained to reason only over that assembled evidence.
The model does not invent explanations. It reconstructs them.
Mapping Back to the SDLC Memory Thesis
Earlier, we asked a strategic question: if AI replaces execution, what remains valuable?
The answer was context and causality.
This vector-plus-graph design operationalizes that thesis.
Vector storage captures what was said. Graph structure captures why it mattered. The combination preserves how the system evolved.
Without a vector, we lose relevance. Without a graph, we lose lineage. Without both, we lose memory.
The Deeper Insight
Most teams will build RAG pipelines this year. Many will believe they have “AI-powered knowledge.” But very few will build Provenance.
Because Provenance forces you to confront structure. It forces you to model decisions explicitly, to define directionality, to handle supersession, to enforce identity, to avoid duplication, and to think in terms of causal systems rather than documents.
It is more demanding than embedding text. But that is exactly why it becomes a strategic differentiator.
In a world where AI can write code and draft documentation, the real competitive advantage will belong to organizations that can explain their own evolution, that can trace decisions, justify trade-offs, and surface the hidden chains that shape outcomes.
That is not a prompt engineering problem. It is a memory architecture problem.
And real memory is never flat. It is always structured.