
What AI Output Testing Actually Looks Like
The QA skill that survives when AI automates the obvious tests
Author: Yauheni Kurbayeu
Published: May 26, 2026
LinkedIn
Let’s say the uncomfortable part out loud: some QA work is going to be automated.
It will not happen at the same speed in every company, and it will not erase every testing role in one dramatic wave.
The shift will be uneven, sometimes overhyped, and sometimes invisible until it is already inside the tooling.
Enough of the work will change that ignoring it is risky.
AI can already generate test cases, summarize requirements, write regression checks, compare screenshots, produce synthetic data, and explain failing builds.
The parts of QA that are mostly about repeating known checks against known expectations will keep getting cheaper.
Picture a familiar sprint review.
The team ships an AI assistant that produces a clean recommendation, the demo looks convincing, and the happy path passes.
Someone says, “QA signed off.”
But what exactly did QA sign off on?
Was it the wording of the answer?
The JSON shape?
The fact that the assistant did not crash?
Or was it the deeper question: whether the system used the right evidence, handled uncertainty honestly, and knew when it was making a decision?
That does not mean QA disappears. It means the center of gravity moves.
The QA people who stay valuable will not only ask:
Did the system produce the expected output?
They will ask:
Did this AI system make the right kind of decision, from the right evidence, with the right memory, under the right governance boundaries?
That is a much harder job to automate away, and it is exactly where AI-output testing starts to matter.
This article is not a comfort blanket.
It is a map of the testing work that appears when software stops being only deterministic execution and starts becoming reasoning, memory, delegation, and judgment.
If you work in QA, this is one of the places to look if you are trying to stay ahead of the next wave instead of waiting for it to hit your role.
A lot of people now say that testing AI systems is different. That statement is correct, but it is also almost useless until we make it concrete.
The real question is what kind of “different” we mean.
Are we talking about something slightly harder than checking a JSON schema or snapshotting a generated answer?
Or are we talking about something deeper than comparing one model response with another and asking a human reviewer whether the output “looks good”?
The uncomfortable answer is this:
AI output testing is not really about the output anymore.
At least not only about the output.
The final response is still important. The generated artifact needs to be useful, the recommendation needs to make sense, the code needs to compile, and the workflow needs to complete.
In agentic systems, the output is only the visible end of a longer reasoning episode.
That reasoning episode can be broken even when the output looks acceptable.
That is why the next version of QA needs real examples, not slogans.
So let’s make this practical.
The QA Survival Move: Stop Testing Only the Artifact
The dangerous version of the AI shift for QA is not that every tester gets replaced by a bot.
The more realistic danger is quieter: QA gets reduced to checking the easy surfaces while the valuable quality questions move somewhere else.
If QA only owns format checks, happy-path regression, generated test scripts, and “looks good” review, then AI tooling will squeeze that work hard.
If QA owns the definition of trustworthy AI behavior, the role becomes more strategic.
The old QA muscle still matters.
Teams will still need people who find defects, define acceptance criteria, build regression coverage, challenge vague requirements, and protect users from broken workflows.
AI systems, however, add a new layer of failure.
An AI system can produce a polished answer through a broken reasoning path.
It can reuse memory that should have expired, hide uncertainty behind confident prose, and make decisions without realizing those decisions need traceability.
It can also keep acting when it should escalate.
That means the new QA advantage is not simply “I can test AI output.”
It is:
I can test whether an AI system behaved responsibly while producing the output.
Here is the career translation:
| If QA only checks... | AI-era QA needs to check... |
|---|---|
| Whether the answer looks right | Whether the reasoning path is valid |
| Whether the schema is correct | Whether the decision was recognized |
| Whether the model retrieved context | Whether that context was allowed to influence the answer |
| Whether the workflow completed | Whether the system should have acted autonomously at all |
| Whether agents produced an artifact | Whether the claimed agent handoffs actually happened |
This is where QA can move from execution policing into reasoning governance.
That is the part worth learning now.
The Five QA Families That Make AI Systems Harder to Trust Blindly
Traditional QA largely focused on this question:
Did the system produce the expected result?
AI-output testing expands that question into something much deeper:
Did the system produce a valid artifact through a valid reasoning path?
That shift changes the quality surface itself.
The five broader testing families can be summarized like this:
1. Decision Recognition Testing
2. Reasoning Trace Quality Testing
3. Memory and Context Reuse Testing
4. Governance and Escalation Testing
5. Agentic Flow and Drift TestingThese are not replacements for deterministic QA.
Deterministic correctness still matters, but these families extend QA into new quality surfaces: decisions, memory, evidence, uncertainty, orchestration, governance, and reasoning drift.
That is what makes AI-output testing fundamentally different from traditional software testing.
A practical testing vocabulary sits underneath those five families:
Decision Recognition:
- decision detection testing
- decision boundary testing
- no-decision negative control testing
Reasoning Trace Quality:
- provenance completeness testing
- evidence discipline testing
- confidence-basis validation
Memory and Context Reuse:
- memory reuse testing
- stale prior rejection testing
- conflicting prior resolution testing
Governance and Escalation:
- escalation correctness testing
- refusal correctness testing
- authority-boundary testing
Agentic Flow and Drift:
- role-boundary testing
- orchestration trace testing
- reasoning drift testing
- artifact-through-valid-path testingThe pattern names matter because they turn a broad concern into specific pass/fail assertions.
For QA teams, they also turn a vague career threat into a concrete skill path.
QA teams can build test suites around these patterns and turn them into acceptance criteria for AI features.
They can also use them in model evaluation, prompt regression, agent trace review, governance audits, and release gates.
That is the point.
The future-proof QA skill is not “knowing AI.”
It is knowing how AI systems fail when they appear to be working.

1. Decision Recognition Testing
This testing family asks:
Did the AI system understand that it was making a meaningful decision?
In practice, that means decision detection testing, no-decision negative controls, and decision boundary testing.
The practical importance is enormous because many AI workflows blur the line between execution and judgment.
In deterministic systems, a workflow may simply transform input into output.
In agentic systems, the workflow may select one strategy over another, accept a risk, or reject a viable alternative.
It may also escalate uncertainty, apply a policy interpretation, or reuse historical precedent.
If the system cannot distinguish meaningful decisions from ordinary execution noise, provenance quality collapses immediately.
For QA, this is a major upgrade from checking only output correctness.
It means testing whether the system knew that a business, technical, operational, or policy decision had occurred.
That is where QA starts protecting organizational judgment, not just UI behavior.
Real-life software engineering examples
You see this pattern in product prioritization assistants, architecture recommendation agents, and release go/no-go advisors.
It also appears in incident response copilots, backlog triage agents, and modernization planning assistants.
Imagine an AI release advisor recommending delay of a production deployment.
Traditional QA may verify that the recommendation exists, the format is correct, and the explanation sounds coherent.
Decision-recognition QA asks something deeper:
Did the system recognize that a release-risk decision happened and that a business trade-off existed?
Did it notice that multiple viable options were present, escalation boundaries mattered, and the decision deserved durable traceability?
Example 1.1: The Output Is Correct, but the Decision Was Not Detected
Imagine an AI agent receives this task:
We need to choose what to prioritize next quarter: customer trust improvements, competitive feature parity, or internal platform cleanup.
A weak AI-output test says:
expected_output:
contains_recommendation: true
mentions_tradeoffs: trueA stronger AI-output test says:
expected_behavior:
decision_detected: true
decision_type: prioritization
alternatives_identified:
- customer trust improvements
- competitive feature parity
- internal platform cleanup
selected_option_present: true
rejected_options_have_rationale: true
decision_should_be_logged: trueThe difference is subtle but important.
The first test checks whether the answer looks useful.
The second test checks whether the system understood that it had made a decision.
Example 1.2: Two Decisions Were Incorrectly Merged
Imagine the task:
Recommend a rollout strategy and define the safety guardrails.
A weak output may collapse both into one vague decision:
decision: Use gradual rollout with monitoring.A stronger output preserves both decisions separately:
decisions:
- decision_id: rollout-scope
decision: Start with limited rollout to internal users and 5% of production traffic.
alternatives_rejected:
- full rollout
- internal-only rollout
- decision_id: safety-guardrails
decision: Require automated rollback on error-rate increase and manual review before expanding traffic.
alternatives_rejected:
- monitoring-only approach
- full automatic expansionNow QA can verify that both material decisions were captured separately:
multi_decision_assertions:
expected_decision_count: 2
rollout_decision_present: true
safety_guardrail_decision_present: true
decision_boundaries_preserved: trueThis is not just cleaner documentation.
It is better testability.
Example 1.3: The Agent Should Refuse to Create a Decision Record
Imagine this prompt:
Rewrite this paragraph for clarity without changing meaning.
The correct behavior may be:
expected_behavior:
output_artifact_created: true
decision_detected: false
decision_log_created: falseSometimes the correct output is absence of memory.

2. Reasoning Trace Quality Testing
This testing family asks:
Is the reasoning behind the output inspectable, challengeable, and reusable?
The concrete checks include provenance completeness testing, evidence discipline testing, and confidence-basis validation.
They also include assumptions visibility, rejected-alternative preservation, and evidence-gap validation.
This family matters because persuasive prose is not the same thing as trustworthy reasoning.
An AI-generated recommendation may sound highly competent while quietly hiding unsupported assumptions, missing evidence, weak confidence, collapsed alternatives, and invisible trade-offs.
Reasoning trace quality testing exists to make those hidden structures visible.
For QA, this is the difference between approving a good-looking answer and validating that the answer can survive audit, challenge, and future reuse.
This is where testers become reasoning inspectors.
Real-life software engineering examples
This shows up in architecture design reviews, compliance-sensitive workflows, security exception handling, and operational risk analysis.
It also appears in root-cause investigation summaries, AI-generated ADRs, and migration strategy recommendations.
Imagine an AI agent proposing a new caching strategy for a distributed platform.
A shallow QA check asks:
Does the proposal sound technically correct?
A reasoning-trace QA check asks whether the system explained trade-offs, preserved rejected alternatives, and identified evidence gaps.
It also asks whether the system described confidence honestly and separated assumptions from telemetry.
Example 2.1: Provenance Is Too Vague
A weak decision record says:
decision: Prioritize customer trust improvements.
reasoning: Better for customers.A stronger decision record says:
decision: Prioritize customer trust improvements over competitive feature parity and internal platform cleanup.
bounded_context:
domain: product-roadmap
scope: next-quarter-prioritization
selected_option: customer trust improvements
assumptions:
- current customer trust signals are materially affecting retention
- competitive pressure is real but not yet existential
- platform cleanup can wait one quarter without creating unacceptable delivery risk
rejected_alternatives:
- option: competitive feature parity
reason: important, but less urgent than restoring reliability and trust
- option: internal platform cleanup
reason: valuable, but can be sequenced after trust-impacting issues
risks_accepted:
- slower competitive feature delivery
- continued internal platform friction
confidence: medium
confidence_basis: based on available roadmap context, but missing quantified retention impactThe question is not only whether the recommendation sounds plausible.
The question is whether the reasoning survives future inspection.
Many AI tests are still too shallow here.
They check whether the answer says the right thing.
They do not check whether the answer carries enough context to become future memory.
Example 2.2: Evidence Discipline Testing
A strong system should distinguish evidence from assumption.
evidence_discipline_test:
missing_evidence_must_be_named: true
unsupported_claims_forbidden: true
confidence_must_match_available_evidence: true
refusal_allowed_when_evidence_insufficient: trueOne of the strongest possible outputs from an AI system may simply be:
Not enough evidence exists to support this conclusion.

3. Memory and Context Reuse Testing
This testing family asks:
Did the AI reuse prior context correctly, or did it blindly copy history?
The checks here are memory reuse testing, stale prior rejection testing, conflicting prior resolution testing, and context-transfer validation.
This family becomes critical once AI systems move from stateless prompting into organizational memory.
The dangerous failure mode is not simply hallucination.
The more dangerous failure mode is plausible misuse of historical reasoning.
A stale prior may look semantically correct while being operationally invalid.
For QA, this is one of the biggest new opportunities.
Many AI products will proudly claim they have memory.
The serious question is whether that memory is safe to reuse.
Real-life software engineering examples
The same concern appears in recurring architecture decisions, incident playbook reuse, rollout strategy selection, and customer support escalation patterns.
It also matters in fraud and risk workflows, migration planning, and release governance.
Imagine a previous rollout was approved without manual review because the feature was low-risk.
Now a new rollout touches regulated customer data.
A weak memory-enabled system may reuse the old rollout logic because the situations look similar.
A stronger system should detect the changed risk profile, policy boundaries, ownership, and admissibility conditions.
This is where QA evolves from retrieval testing into context-validity testing.
The question is no longer:
Did the agent retrieve something relevant?
The stronger question becomes:
Should this memory have been allowed to influence this decision?
Example 3.1: Prior Memory Became a Command
A weak memory-enabled agent may simply repeat history:
We previously prioritized customer trust, so we should do the same again.
That sounds consistent.
Consistency is not always quality.
A good AI-output test should verify that prior memory behaves like a soft prior, not as a hard rule.
A stronger system should behave like this:
prior_memory_behavior:
prior_decisions_reviewed: true
prior_decisions_used_as_context: true
current_context_compared_with_prior_context: true
stale_or_changed_constraints_checked: true
prior_decision_not_treated_as_binding: true
final_decision_explains_reuse_or_override: trueThe goal is not identical output.
The goal is disciplined context transfer.
Example 3.2: Stale Prior Must Be Rejected
Imagine the system retrieves this old decision:
Rollout without manual review was previously approved.
In the current task, however, the feature now touches regulated data.
stale_prior_test:
expected_behavior:
prior_retrieved: true
context_difference_detected: true
prior_reuse_rejected: true
escalation_or_review_required: trueThe output may still recommend a rollout strategy.
The real pass/fail condition is whether the system refused to reuse memory outside its valid context.
Example 3.3: Conflicting Priors Must Be Interpreted
Imagine two prior decisions supported fast rollout.
Another supported delayed rollout because of safety concerns.
A weak system counts the majority.
Decision memory is not voting.
A stronger system evaluates bounded context.
conflicting_prior_test:
conflicting_priors_detected: true
majority_vote_avoided: true
context_similarity_used_for_weighting: true
final_decision_explains_conflict_resolution: trueThe question is not:
Did it retrieve memory?
The stronger question is:
Did it understand which memory actually mattered?

4. Governance and Escalation Testing
This testing family asks:
Did the AI know when not to act autonomously?
Here the suite looks for escalation correctness, refusal correctness, authority-boundary failures, policy-boundary violations, and admissibility gaps.
This family becomes critical in production-grade AI systems because many workflows should not continue autonomously under uncertainty.
The most dangerous AI systems are often not the obviously broken ones.
They are the ones that continue confidently when escalation should have happened.
For QA, this is an important mental shift.
A blocked action can be a passing test, a refusal can be correct behavior, and an escalation can be the highest-quality output.
Real-life software engineering examples
Good candidates include production deployment decisions, access approval flows, privacy-sensitive operations, and security incident actions.
The pattern also matters in financial workflow automation, regulated operational workflows, and customer-impacting risk actions.
Imagine an AI deployment assistant working with incomplete telemetry, missing rollback ownership, and unresolved anomaly signals.
The weak system still produces a deployment recommendation because it wants to appear useful.
The stronger system escalates.
Governance QA treats escalation as a successful outcome rather than as failure to complete the task.
That is a fundamental mental shift.
Example 4.1: Escalation Is the Correct Output
Imagine the task:
Decide whether to proceed with deployment. Telemetry is incomplete.
A strong system behaves like this:
escalation_test:
input_conditions:
telemetry_complete: false
rollback_owner_available: false
expected_behavior:
final_recommendation: do_not_proceed_autonomously
escalation_required: true
escalation_reason_present: trueIn reasoning systems, refusal or escalation may be the highest-quality outcome.
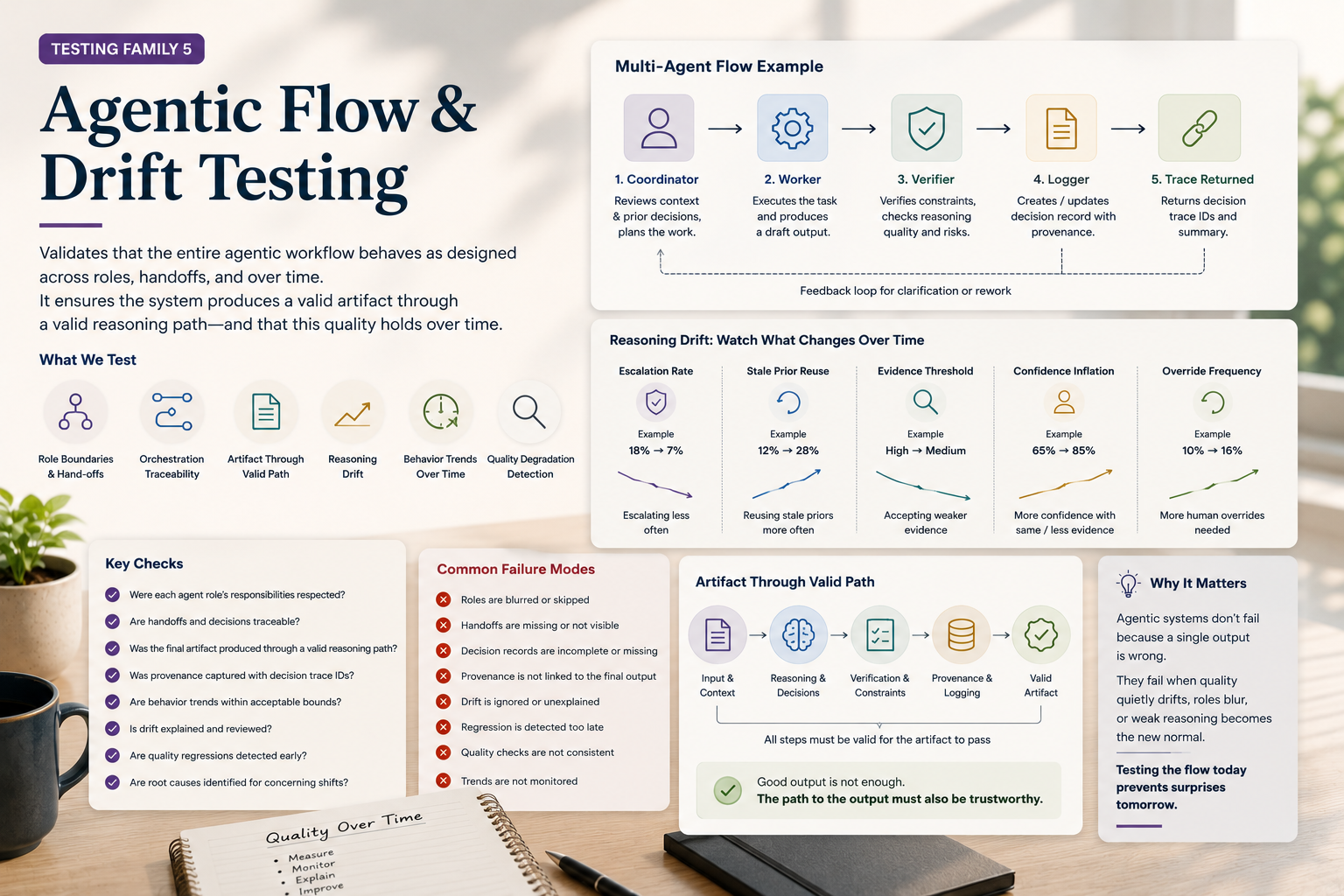
5. Agentic Flow and Drift Testing
This testing family asks:
Did the whole agentic workflow behave as designed over time?
The patterns here are role-boundary testing, orchestration trace testing, reasoning drift testing, and artifact-through-valid-path testing.
This family matters because modern AI workflows increasingly involve multiple agents, tools, memory layers, and orchestration stages.
The final artifact alone is no longer enough to verify system behavior.
For QA, this is where “the output passed” becomes too small a statement.
The real question becomes whether the system followed the architecture it claimed to follow.
Real-life software engineering examples
It is especially relevant for multi-agent SDLC automation, AI code review pipelines, autonomous QA generation, and content migration agents.
It also fits AEM/Sitecore modernization flows, incident automation pipelines, data remediation agents, and architecture governance copilots.
Imagine a system that claims to use a provenance-aware coordinator, an execution worker, a verifier, and a strict logger.
Traditional QA may only validate the final artifact.
Agentic-flow QA asks whether the coordinator actually reviewed prior decisions and whether the worker executed the task.
It then checks whether the verifier challenged constraints, the logger preserved the decision record, and the trace proved the handoffs happened.
Without this layer, multi-agent architecture can easily become just a diagram.
Example 5.1: Split-Agent Systems Need Role-Boundary Tests
split_agent_test:
expected_roles:
- provenance_coordinator
- execution_worker
- strict_logger
expected_behavior:
coordinator_reviews_priors: true
worker_completes_task_artifact: true
logger_creates_structured_decision_record: true
role_handoff_visible: trueThe test does not care only about the final output.
It cares whether the claimed architecture actually happened.
Example 5.2: Reasoning Drift Testing
reasoning_drift_test:
comparable_episodes_available: true
escalation_rate_changed: true|false
stale_prior_reuse_increased: true|false
evidence_threshold_weakened: true|falseThe output may still look acceptable.
The reasoning behavior may already be drifting operationally.
What QA Engineers Can Do With This Now
This is where the article becomes practical for anyone worried about the future of QA work. Do not wait for someone to hand you a finished AI testing discipline; start building one.
A useful first move is to create a small AI-output test suite that does not only check final answers.
For example:
qa_ai_output_test_suite:
decision_detection_cases:
- prompt_contains_real_decision: true
- prompt_is_only_rewrite_task: false
provenance_cases:
- assumptions_must_be_visible: true
- rejected_alternatives_must_be_preserved: true
- confidence_basis_must_match_evidence: true
memory_cases:
- prior_memory_relevant_but_not_binding: true
- stale_prior_must_be_rejected: true
- conflicting_priors_must_be_explained: true
governance_cases:
- missing_telemetry_requires_escalation: true
- insufficient_authority_blocks_action: true
- refusal_can_be_expected_output: true
agentic_flow_cases:
- role_handoffs_must_be_visible: true
- verifier_must_challenge_constraints: true
- logger_must_capture_decision_record: trueThis kind of suite is not just “AI testing.”
It is a portfolio of judgment.
It shows that you understand how AI products fail in ways that normal regression testing will miss.
It also gives QA a stronger seat in product conversations.
Instead of asking only:
What should the screen show?
QA can ask:
What decisions is this agent allowed to make?
What evidence must it preserve?
When must it stop?
What prior context is unsafe to reuse?
How will we know the agentic workflow actually happened?
Those are not junior questions.
Those are system-quality questions.
In an AI-heavy organization, the people who can ask and operationalize those questions will matter.
The professional risk is not that QA has no future.
The professional risk is staying attached to the parts of QA that AI will make cheap.
The opportunity is to move toward the parts of QA that AI makes necessary.
Final Thought
The future of AI-output testing will not be won by asking whether the answer sounded good.
That is too weak.
It will be won by asking whether the output came from a trustworthy reasoning path.
That is the lane QA can own.
This is why the next generation of QA patterns will look different from traditional test automation patterns.
They will still care about schemas, artifacts, workflows, and deterministic correctness.
They will also care about decision detection, provenance completeness, memory reuse, stale prior rejection, escalation correctness, orchestration traceability, and reasoning drift.
That is what AI-output testing starts to look like in practice.
Not just:
Did it generate the expected output?
But:
Did it produce a valid artifact through a valid reasoning path?
That question is not a retreat from QA.
It is where QA becomes more important.