Agentic Flow How-To Guide
Author: Yauheni Kurbayeu
Published: Mar 22, 2026
TL;DR
In the previous article, Building an Automated Translation Pipeline for a Markdown Blog with GitHub Copilot Agents, we designed a GitHub Copilot-based translation pipeline built around an orchestrator, language-specific subagents, reusable skills, and hooks.
That design was then evaluated against the real repository implementation in the assessment report, How the Current GitHub Copilot Article Translation Flow Works in This Repository, which shows what the current setup actually does today and where the responsibilities are really split across repository instructions, agents, skills, and hooks.
In this article, we go one step further and turn those ideas into a practical how-to. We walk through how this workspace models agentic inheritance, how instruction layering replaces native inheritance, and how the three execution approaches work:
- sequential
- parallel
- hierarchical
The goal is to give you a reusable design pattern for GitHub Copilot agent flows with shared instructions, specialized workers, and clear coordination rules.
Hooks are intentionally out of scope here. They can be added later to improve validation, observability, and safety around the flow.
What This Workspace Already Demonstrates
The current workspace uses an inheritance-like structure built from layered instructions rather than true class inheritance.
Main building blocks
- .github/copilot-instructions.md defines the global rules for all agents.
- .github/skills/shared-agent-contract/SKILL.md defines the common task envelope and return contract.
- .github/skills/agents-orchestration/SKILL.md defines how a parent agent delegates work.
- .github/skills/worker/SKILL.md defines the default behavior for worker agents.
- .github/agents/main-orchestrator.agent.md acts as the root coordinator.
- .github/agents/worker1.agent.md, .github/agents/worker2.agent.md, and .github/agents/worker3.agent.md act as specialized workers.
Current review summary
- The inheritance model is clear and reusable.
- Sequential mode is modeled as orchestrator-managed chaining.
- Parallel mode is modeled as orchestrator-managed fan-out and fan-in.
- Hierarchical mode is modeled as worker-to-worker delegation.
- Hierarchical mode changes the role of
worker1andworker2: in that mode they are no longer pure leaf workers, even though the shared worker skill describes workers as leaf nodes by default.
That last point is not necessarily wrong, but it is an important design choice. If you use hierarchical execution, some workers become intermediate coordinators.
Agentic Inheritance
The core idea
GitHub Copilot agents do not have native inheritance. The practical replacement is instruction composition:
- Global instructions act as the base class.
- Shared skills act as reusable role layers.
- Agent files act as thin specializations.
- Runtime task data completes the behavior.
This pattern gives you most of the benefits of inheritance:
- one shared contract
- less duplicated prompt logic
- clearer responsibility boundaries
- easier maintenance when the flow grows
Instruction precedence
The current workspace follows this order:
- .github/copilot-instructions.md
- shared skills referenced by an agent
- agent-local instructions in the
.agent.mdfile - runtime task envelope from the user or parent agent
This means a child agent should specialize the shared rules, not contradict them.
Inheritance map for this workspace
Global base
.github/copilot-instructions.md
Shared contract
.github/skills/shared-agent-contract/SKILL.md
Role-specific behavior
.github/skills/agents-orchestration/SKILL.md
.github/skills/worker/SKILL.md
Agent specializations
.github/agents/main-orchestrator.agent.md
.github/agents/worker1.agent.md
.github/agents/worker2.agent.md
.github/agents/worker3.agent.mdShared contract
The shared agent contract is the most important inheritance layer because it standardizes:
- the task envelope
- the expected input fields
- the output schema
- failure handling
In this workspace, the common task envelope contains:
task_idobjectivemodeinput_artifactconstraintsexpected_outputparent_agent
The common return contract contains:
statusagentsummaryresultnotes
This is what allows multiple agents to cooperate without inventing a new mini-protocol every time.
Execution Modes
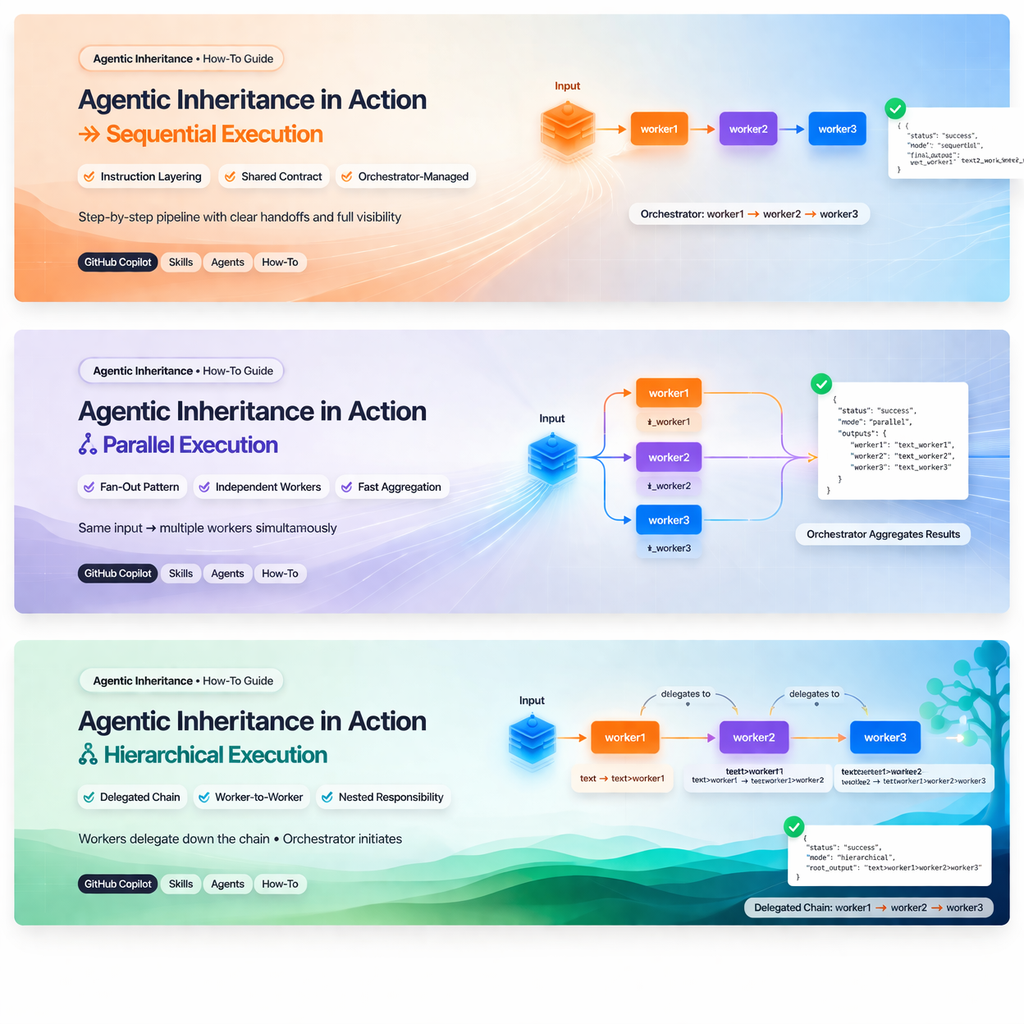
1. Sequential mode
What it means
Sequential mode is a step-by-step pipeline controlled by the orchestrator.
The orchestrator remains responsible for each handoff:
main-orchestrator -> worker1 -> main-orchestrator -> worker2 -> main-orchestrator -> worker3When to use it
- when each step depends on the previous result
- when you want centralized control and visibility
- when failure should stop the flow immediately
Benefits
- easiest mode to reason about
- strongest orchestrator control
- straightforward logging and retries
Tradeoffs
- slower than parallel mode
- the orchestrator sits on the critical path between every step
Example
status: success
agent: main-orchestrator
summary: Ran workers 1→2→3 sequentially on the input text and returned the final transformed output.
result:
mode: sequential
steps:
- worker: worker1
input: "text to transform"
output: "text to transform_worker1"
- worker: worker2
input: "text to transform_worker1"
output: "text to transform_worker1_worker2"
- worker: worker3
input: "text to transform_worker1_worker2"
output: "text to transform_worker1_worker2_worker3"
final_output: "text to transform_worker1_worker2_worker3"
notes: Each worker appended its marker in turn, with the orchestrator coordinating the handoffs and preserving the step history.How to implement it
- The orchestrator receives the original input.
- The orchestrator sends the input to
worker1. worker1returns a structured result.- The orchestrator takes
worker1.resultand sends it toworker2. - The orchestrator takes
worker2.resultand sends it toworker3. - The orchestrator returns the final worker output plus step history.
2. Parallel mode
What it means
Parallel mode is a fan-out pattern where the orchestrator sends the same input to multiple workers at the same time.
main-orchestrator -> worker1
main-orchestrator -> worker2
main-orchestrator -> worker3The orchestrator then aggregates the results.
When to use it
- when workers are independent
- when you want comparison outputs
- when speed matters more than step-to-step dependency
Benefits
- faster execution when tasks are independent
- good for experimentation and comparison
- simple aggregation model
Tradeoffs
- workers cannot build on one another
- results may need post-processing before they are directly comparable
Example
status: success
agent: main-orchestrator
summary: Ran three workers in parallel on the same input text and collected their outputs.
result:
mode: parallel
outputs:
worker1: "text Parallel_worker1"
worker2: "text Parallel_worker2"
worker3: "text Parallel_worker3"
notes: Each worker independently appended its own marker to the shared input, with the orchestrator coordinating the aggregation of results.How to implement it
- The orchestrator receives the original input.
- The orchestrator sends the same
input_artifactto all workers. - Each worker returns its own structured result independently.
- The orchestrator combines the outputs into a worker-keyed result object.
3. Hierarchical mode
What it means
Hierarchical mode is a delegated chain where the orchestrator starts the flow, but workers pass control down the line:
main-orchestrator -> worker1 -> worker2 -> worker3This is different from sequential mode because the orchestrator is not the handoff point between each stage.
When to use it
- when a subflow should be owned by the workers themselves
- when you want nested responsibility
- when later workers are conceptually children of earlier workers
Benefits
- supports tree-like or nested delegation patterns
- can reduce orchestration chatter
- models parent-child processing chains naturally
Tradeoffs
- harder to trace than orchestrator-managed sequential mode
- worker agents stop being pure leaf nodes
- failure handling and observability become more complex
Important design note
In this workspace, hierarchical mode is implemented by allowing workers to delegate to other workers.
That means:
worker1becomes a parent ofworker2worker2becomes a parent ofworker3- only
worker3stays a true leaf in the hierarchical path
This is the main conceptual difference from the default worker skill, which describes workers as leaf agents unless explicitly configured otherwise.
Example
status: success
agent: main-orchestrator
summary: Ran workers hierarchically (worker1 → worker2 → worker3) on the input textTree and collected each stage’s output.
result:
mode: hierarchical
hierarchy:
worker1:
input: "textTree"
output: "textTree>worker1"
worker2:
parent: "worker1"
input: "textTree>worker1"
output: "textTree>worker1>worker2"
worker3:
parent: "worker2"
input: "textTree>worker1>worker2"
output: "textTree>worker1>worker2>worker3"
root_output: "textTree>worker1>worker2>worker3"
notes: Hierarchical mode mirrors a delegated chain (each worker builds on its parent’s output); the orchestrator initiates the flow but does not manage each handoff, allowing workers to take ownership of the subflow and pass results directly to their child workers.How to implement it
- The orchestrator starts the flow by calling
worker1. worker1transforms the input and forwards the result toworker2.worker2transforms the input and forwards the result toworker3.worker3returns the terminal output.- The flow returns the final result together with stage lineage.
Sequential vs Parallel vs Hierarchical
| Approach | Control point | Dependency model | Best for |
|---|---|---|---|
| Sequential | Orchestrator between every step | Strong step dependency | Pipelines with centralized control |
| Parallel | Orchestrator fans out and aggregates | Independent workers | Speed, comparison, multi-variant outputs |
| Hierarchical | Workers delegate down the chain | Nested parent-child dependency | Tree-like subflows and delegated ownership |
How To Design a Similar Agentic Flow
Step 1. Define the base contract once
Put shared rules in .github/copilot-instructions.md and keep them generic:
- task envelope
- result schema
- failure schema
- delegation constraints
Step 2. Move reusable behavior into skills
Use one shared contract skill and then create role-specific skills such as:
- orchestration
- worker execution
- validation
- domain-specific transformation
This is how you avoid copying the same prompt logic into every agent.
Step 3. Keep agent files thin
Each agent file should answer only these questions:
- what is this agent responsible for
- which skills does it use
- which child agents may it call
- what makes it different from sibling agents
If a rule applies to many agents, it should usually move upward into a shared skill or global instruction.
Step 4. Choose the right execution mode
Use:
- sequential for orchestrator-controlled pipelines
- parallel for independent branches
- hierarchical for delegated subtrees or nested chains
Do not choose hierarchical mode only because it looks more advanced. It should be used when worker-owned delegation is actually a better model.
Step 5. Keep outputs traceable
Always return enough structure for the parent to understand:
- who ran
- what input they received
- what output they produced
- whether the step succeeded
The sample outputs in this workspace are a good pattern because they preserve both the final result and the path taken to get there.
Recommended Improvements
- Decide whether workers should truly be leaf agents by default, or whether hierarchical delegation is a first-class requirement.
- If hierarchical mode is first-class, update the worker skill language to describe internal-node workers more explicitly.
- Keep the shared contract stable so all execution modes return compatible result structures.
- Consider semantic worker names later, such as
normalize,transform, andfinalize, once the pattern is stable.
Final Takeaway
The cleanest way to build agentic inheritance in GitHub Copilot is to treat inheritance as layered prompt architecture:
- base instructions for universal policy
- shared skills for reusable behavior
- thin agents for specialization
- explicit execution modes for flow control
These three execution modes are all valuable tools in your design toolbox:
- sequential is the clearest orchestrator-led pipeline
- parallel is the clearest fan-out model
- hierarchical is the most powerful but also the most structurally opinionated
If you are introducing agentic flow to a new team, start with sequential, add parallel when tasks are independent, and introduce hierarchical only when you truly need worker-owned delegation chains.
Useful GitHub Copilot Specifications and Docs
- About customizing GitHub Copilot responses - Overview of repository-wide instructions, path-specific instructions, and related customization mechanisms.
- Adding repository custom instructions for GitHub Copilot - Practical guide for creating
.github/copilot-instructions.mdand.github/instructions/*.instructions.md. - Support for different types of custom instructions - Reference matrix for where repository-wide, path-specific, personal, and organization instructions are supported.
- About custom agents - Conceptual overview of what custom agents are, where they live, and how they fit into Copilot workflows.
- Creating custom agents for Copilot coding agent - Step-by-step guide for creating
.github/agents/*.agent.mdprofiles. - Custom agents configuration - Reference documentation for agent frontmatter, tools, model settings, and invocation behavior.
- About agent skills - Explains what skills are and how they complement instructions and custom agents.
- Creating agent skills for GitHub Copilot - Practical guide for structuring
.github/skills/<skill>/SKILL.mdand related resources. - About hooks - Conceptual explanation of hook triggers, lifecycle events, and governance use cases.
- Using hooks with GitHub Copilot agents - Implementation guide for
.github/hooks/hooks.jsonand shell-based hook actions. - Hooks configuration - Reference for the hook manifest structure, events, and configuration details.
- Copilot customization cheat sheet - Compact reference that compares instructions, agents, skills, hooks, and other customization options side by side.