De RAG a Provenance: cómo nos dimos cuenta de que los vectores por sí solos no son memoria
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
En los artículos anteriores exploramos una observación incómoda: el SDLC realmente no tiene memoria.
No porque no escribamos documentación. No porque Jira esté vacío. No porque las notas de las reuniones desaparezcan.
Perdemos memoria porque perdemos causalidad.
Se toman decisiones, se discuten riesgos, se forman supuestos, se asignan acciones y, sin embargo, meses después, cuando algo se rompe o se produce un giro estratégico, no podemos reconstruir la cadena de razonamiento que nos llevó hasta allí. Recuperamos fragmentos, pero no podemos rastrear el linaje.
Ahí fue donde la idea de Provenance entró en la conversación. No como otra práctica de documentación, ni como un truco de IA, sino como algo más estructural: una forma de preservar el ADN causal de la entrega. Pero en cuanto decimos “necesitamos memoria”, enseguida aparece una pregunta práctica: “¿Qué tipo de modelo de datos requiere una memoria real del SDLC?”
Y precisamente aquí es donde la mayoría de los equipos se detienen demasiado pronto.
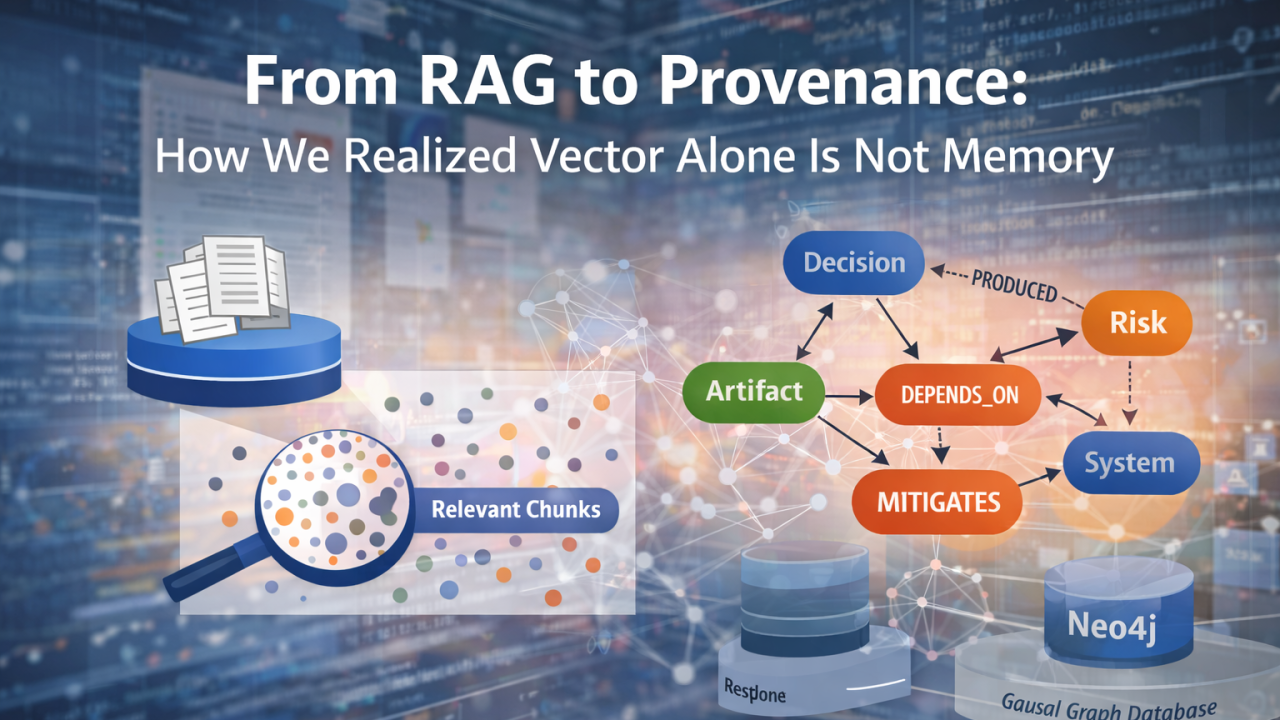
La seductora comodidad de la memoria vectorial
El instinto moderno es claro. Tomamos todo el contenido disponible — notas de reuniones, tickets de Jira, páginas de Confluence, documentos de diseño. Lo dividimos en fragmentos, lo convertimos en vectores, lo almacenamos en pgvector y luego recuperamos los fragmentos relevantes usando similitud semántica. Lo envolvemos con un LLM y, de repente, tenemos algo que parece inteligente.
Funciona. Se siente mágico. Recupera contexto más rápido de lo que cualquier humano podría hacerlo.
Pero con el tiempo, algo empieza a sentirse incompleto.
Porque la búsqueda vectorial solo responde a un tipo de pregunta: “¿Qué texto se parece a mi consulta?”
La similitud, sin embargo, no es memoria.
Cuando billing falla en marzo y alguien pregunta: “¿Por qué ocurrió esto?”, la similitud semántica puede recuperar fragmentos que mencionan billing y marzo. Pero no puede decirte qué decisión cambió la lógica de billing, si esa decisión sustituyó a una anterior, qué dependencia del sistema se vio afectada o qué mitigación nunca llegó a implementarse.
Los vectores te dan relevancia. No te dan causalidad.
Y los fallos de delivery casi siempre son causales.
El momento en que nos dimos cuenta de que necesitábamos un grafo
El cambio ocurrió cuando reformulamos el problema.
En lugar de preguntar: “¿Cómo recuperamos documentos?”, preguntamos: “¿Cómo preservamos la estructura del razonamiento?”
Esa pregunta lo cambia todo.
Dejamos de pensar en párrafos y empezamos a pensar en entidades.
- Una reunión no es solo texto. Es un evento que produce decisiones.
- Una decisión no es solo una frase. Afecta a sistemas.
- Un riesgo no es solo un punto en una lista. Es algo que puede o no ser mitigado mediante acciones.
- Una acción no es solo una tarea. Modifica el estado del sistema.
De repente, el modelo de memoria dejó de parecerse a un almacén de documentos y empezó a parecerse a un grafo.
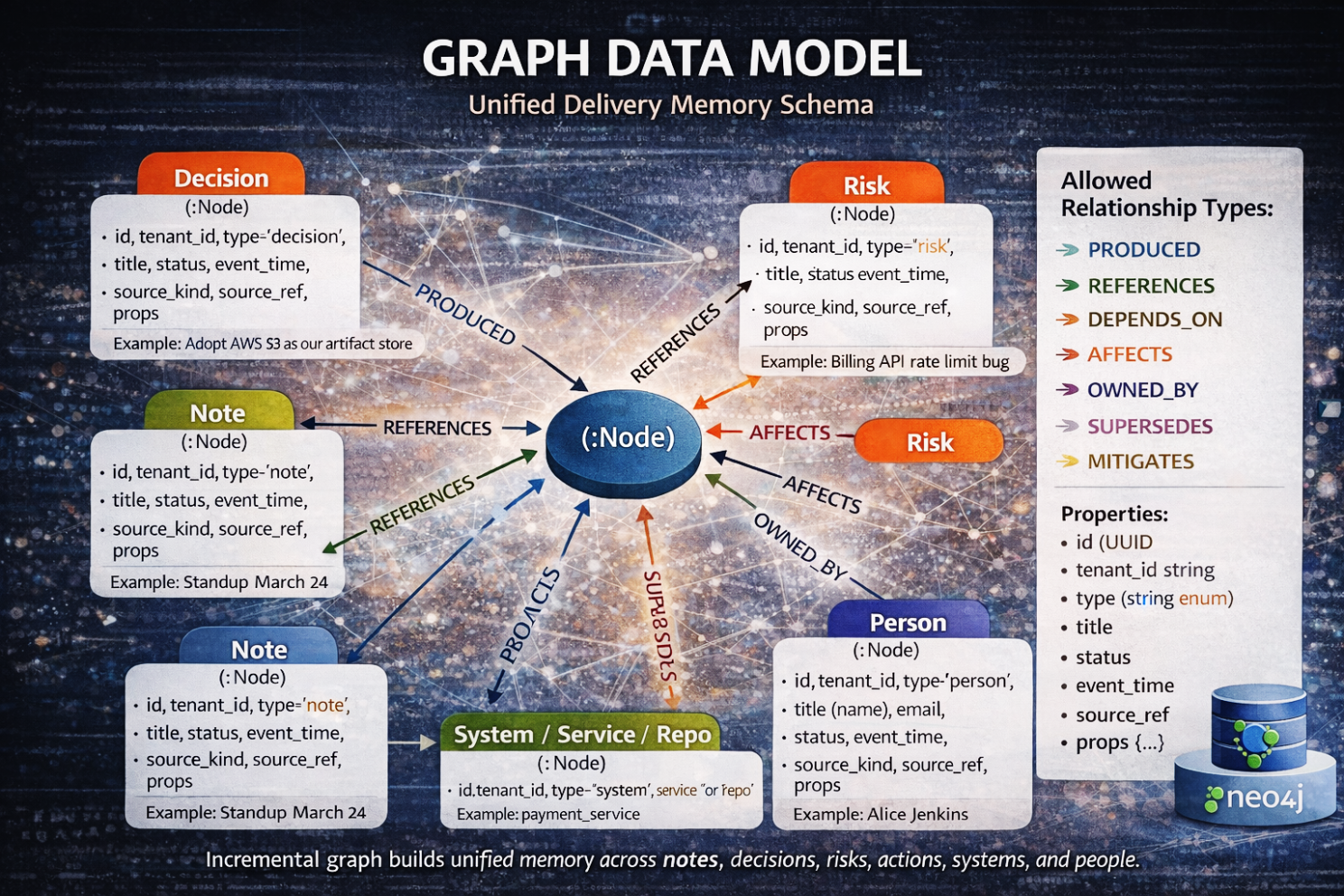
Introdujimos nodos canónicos — entidades de primera clase que existen independientemente de cualquier documento individual. Notas, decisiones, riesgos, action items, artefactos, sistemas, personas: cada uno se convirtió en un objeto estable con identidad. Se almacenan en Postgres como dm_node, no como texto embebido.
Luego introdujimos aristas de provenance — relaciones dirigidas que capturan significado.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
No son hipervínculos. Son afirmaciones causales.
Y en ese momento ocurrió algo sutil pero poderoso: la memoria dejó de ser textual y pasó a ser estructural.

Por qué tanto el vector como el grafo importan
Sería tentador moverlo todo a una base de datos de grafos y declarar la victoria. Pero eso estaría incompleto.
Seguimos necesitando vectores.
Porque cuando un usuario hace una pregunta, no sabemos por dónde empezar. Necesitamos una señal semántica para identificar regiones relevantes del espacio de conocimiento. Eso es lo que nos da pgvector. Nos ayuda a encontrar los fragmentos más relevantes de forma rápida y eficiente.
Pero una vez que encontramos esos fragmentos, el grafo toma el control.
A partir de los nodos semilla identificados mediante búsqueda vectorial, expandimos el grafo de provenance usando Neo4j. Recorremos relaciones sobre quién produjo esta decisión, a qué afecta, qué sustituye, qué riesgo mitiga y qué depende de ella. De repente, la respuesta ya no son solo fragmentos de texto similares, sino un vecindario causal reconstruido.
El vector nos da el punto de entrada. El grafo nos da la explicación.
Juntos forman algo mucho más cercano a la memoria organizacional que cualquiera de los dos por separado.
Construir memoria de forma incremental, como un refuerzo neuronal
Una de las decisiones arquitectónicas más importantes fue esta: el grafo debe ser global, no por documento.
Cada ingestión no crea una isla aislada. En cambio, modifica y fortalece una memoria compartida.
Cuando una nota nueva hace referencia a un sistema existente, reutilizamos ese nodo. Cuando dos reuniones producen la misma decisión con palabras ligeramente distintas, la normalizamos y la reconectamos. Cuando un action item mitiga un riesgo que ya se había discutido antes, no creamos otro riesgo; reforzamos la conexión.
Con el tiempo, el grafo se vuelve más denso. Las aristas ganan confianza. Las referencias repetidas aumentan los contadores de soporte. La memoria de delivery se vuelve más coherente.
No es aprendizaje automático en el sentido clásico, pero estructuralmente se parece al refuerzo.
Cuanto más a menudo algo se menciona, se vincula o se ejecuta, más fuerte se vuelve su presencia estructural.
Así es como la memoria del SDLC empieza a sentirse menos como documentación y más como cognición.

Recuperación como conversación estructurada
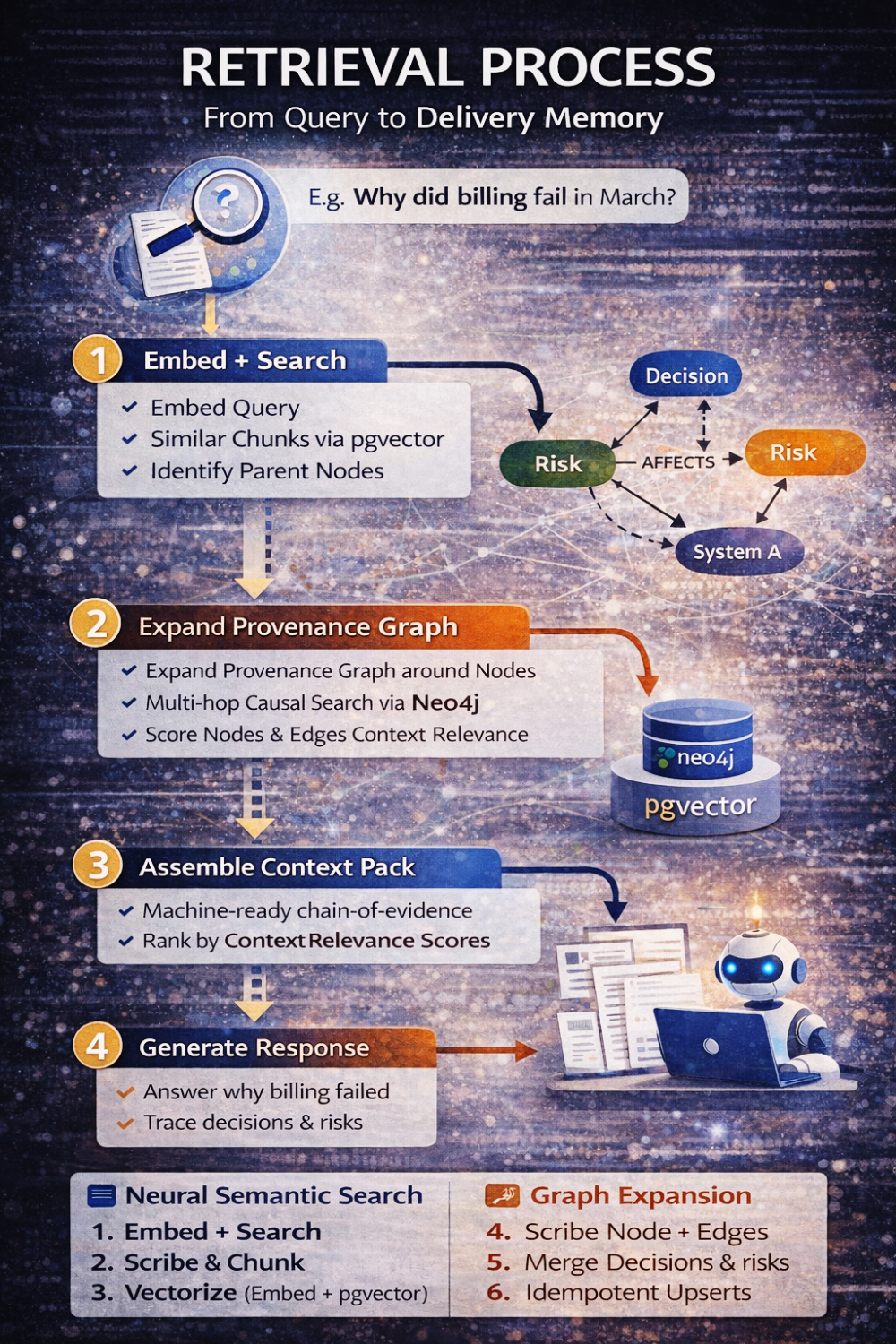
Cuando alguien pregunta ahora: “¿Por qué billing falló en marzo?”, el sistema no se limita a recuperar texto. Realiza una conversación estructurada entre dos modelos.
Primero, embebe la consulta y recupera fragmentos semánticamente relevantes. Luego identifica los nodos padre de esos fragmentos. A partir de ahí, expande el grafo de provenance hasta una profundidad definida, restringida por tipos de relación y límites de tenant. Ensamblan un paquete de contexto que incluye no solo texto relevante, sino también la estructura causal que lo rodea — decisiones, riesgos, acciones, cadenas de supersesión. Solo entonces entra en juego el LLM, e incluso entonces, está limitado a razonar únicamente sobre esa evidencia ensamblada.
El modelo no inventa explicaciones. Las reconstruye.
Volviendo a la tesis de la memoria del SDLC
Antes planteamos una pregunta estratégica: si la IA reemplaza la ejecución, ¿qué sigue siendo valioso?
La respuesta fue contexto y causalidad.
Este diseño de vector más grafo operacionaliza esa tesis.
El almacenamiento vectorial captura lo que se dijo. La estructura del grafo captura por qué importó. La combinación preserva cómo evolucionó el sistema.
Sin un vector, perdemos relevancia. Sin un grafo, perdemos linaje.
Sin ambos, perdemos memoria.
La intuición más profunda
La mayoría de los equipos construirán pipelines RAG este año. Muchos creerán que tienen “conocimiento impulsado por IA”. Pero muy pocos construirán Provenance.
Porque Provenance te obliga a enfrentarte a la estructura. Te obliga a modelar las decisiones explícitamente, a definir direccionalidad, a manejar supersesión, a imponer identidad, a evitar duplicación y a pensar en términos de sistemas causales en lugar de documentos.
Es más exigente que simplemente embeber texto.
Pero precisamente por eso se convierte en un diferenciador estratégico.
En un mundo donde la IA puede escribir código y redactar documentación, la verdadera ventaja competitiva pertenecerá a las organizaciones que puedan explicar su propia evolución, rastrear decisiones, justificar trade-offs y sacar a la luz las cadenas ocultas que moldean los resultados.
Eso no es un problema de prompt engineering.
Es un problema de arquitectura de memoria.
Y la memoria real nunca es plana. Siempre es estructurada.