From RAG to Provenance (Part 2): Cómo aprende realmente la memoria gráfica incremental
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
En el artículo anterior, describí el momento en que nos dimos cuenta de que la búsqueda vectorial por sí sola no es memoria.
Los embeddings son excelentes para encontrar texto similar. Pero la similitud no es linaje. No te dice:
- quién decidió qué,
- sobre qué suposición se basó,
- con quién estaba en conflicto,
- y cuándo esa decisión fue reemplazada.
Esta vez, quiero mostrar qué ocurre después.
¿Cómo actualiza un sistema realmente la memoria organizacional de forma incremental?
No en teoría. No en diagramas de arquitectura.
Sino paso a paso, usando un ejemplo simple del mundo real.
Step 0 — La entrada (donde empieza la memoria)
Supongamos que esta nota aparece después de una sincronización de producto:
“Yauheni decidió posponer el lanzamiento de la instancia de la UE porque la nueva aclaración sobre GDPR del equipo legal introduce riesgos adicionales de cumplimiento. Action item: preparar un plan de mitigación con el equipo de seguridad. Anton planteó la pregunta de si podemos aislar los datos por workspace en lugar de por región.”
Esto es solo texto.
Pero dentro de este párrafo hay:
- Decisiones
- Riesgos
- Preguntas
- Action items
- Personas
- Dependencias implícitas
El objetivo de negocio es simple:
No permitas que esto desaparezca en el historial de Slack. Conviértelo en memoria organizacional estructurada y trazable.
Actores involucrados
- Líder de producto (autor de la fuente)
- Legal (autoridad implícita)
- Equipo de seguridad
- Sistema de Provenance (AI + memoria gráfica)
- Revisor humano
Step 1 — Scribing: convertir texto en significado estructurado
Objetivo de negocio: Extraer artefactos explícitos para que puedan ser gobernados.
El sistema lee el texto y lo convierte en objetos estructurados.
Output (ejemplo simplificado en JSON):
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}Esto todavía no es memoria. Es una interpretación en staging.
En este punto, nada se confirma aún en el grafo central.
Step 2 — Construir un pequeño grafo temporal
Objetivo de negocio: Representar la lógica dentro de esta nota antes de mezclarla con la memoria global.
A partir de los artefactos extraídos, el sistema construye un pequeño grafo temporal.
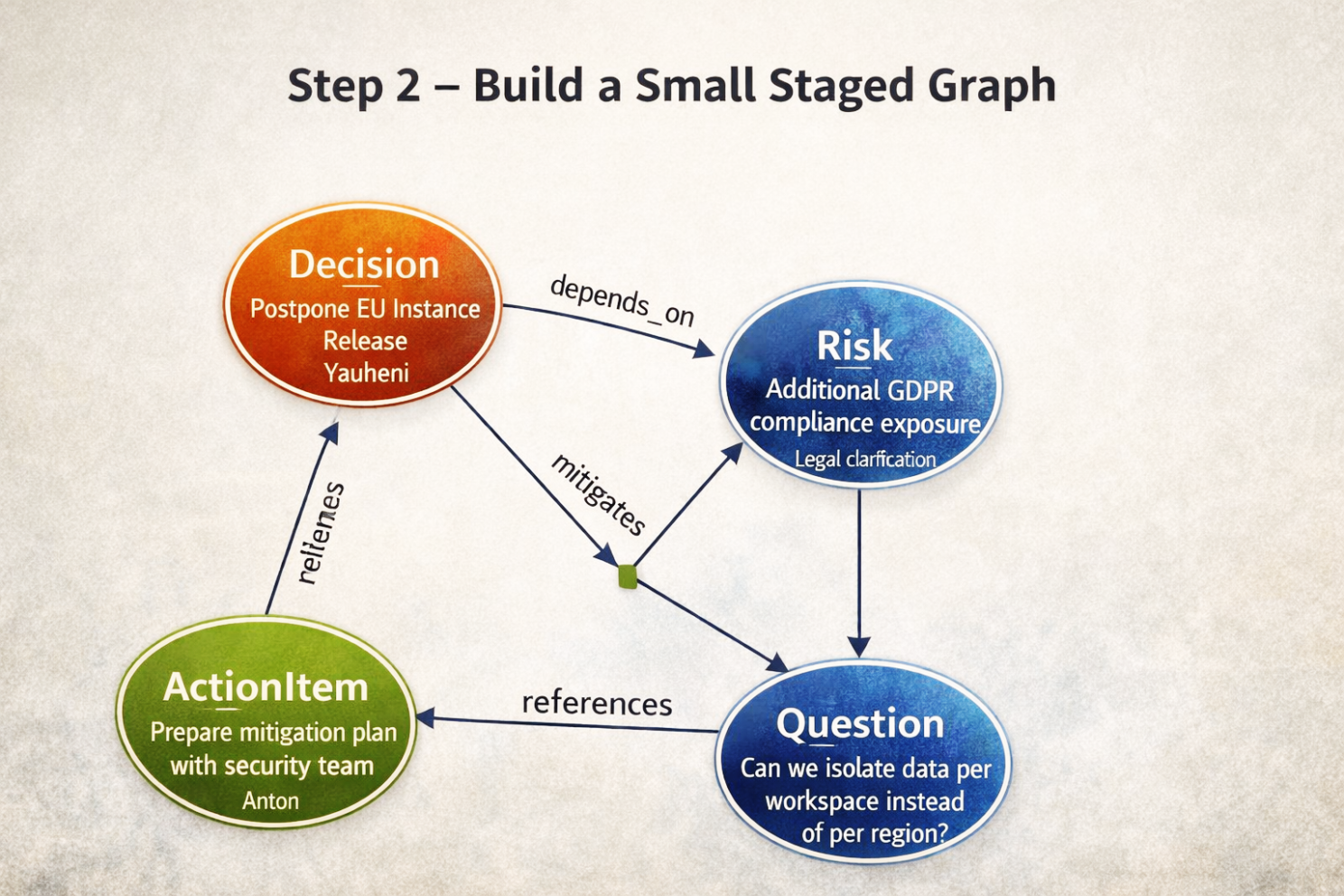
Estructura lógica creada:
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionEste grafo existe solo dentro de la transacción actual.
Todavía no forma parte de la memoria permanente de la empresa.
¿Por qué?
Porque todavía no sabemos si:
- Este riesgo ya existe.
- La decisión es una continuación de una anterior.
- Una autoridad de mayor rango decidió antes algo diferente.
Step 3 — Comparación semántica (pero no a ciegas)
Objetivo de negocio: Detectar si estos objetos ya existen en la memoria.
El sistema verifica la similitud semántica contra la memoria existente.
Supongamos que encuentra esto:

Ahora el sistema se enfrenta a una pregunta de negocio:
- ¿Son las mismas cosas?
- ¿O están relacionadas pero son distintas?
Los vectores por sí solos no pueden responder eso.
Así que el sistema recupera contexto del grafo:
- ¿Quién era el responsable de la decisión anterior?
- ¿Cuál fue la razón?
- ¿Era temporal?
- ¿Fue reemplazada?
Aquí es donde la memoria gráfica importa.
Step 4 — Resolución de identidad (¿fusionar o crear?)
Objetivo de negocio: Evitar duplicación sin destruir el matiz.
El sistema evalúa:
- La antigua “Delay EU rollout (Q1)” se debía a inestabilidad de infraestructura.
- La nueva postergación se debe a riesgo legal.
Diferente razón. Diferente alcance. Diferente momento.
Decisión:
- ✔ Crear un nuevo nodo de Decision
- ✔ Vincularlo al nodo de riesgo GDPR existente
Si el riesgo ya existe, no lo duplicamos.
Lo reforzamos.
La memoria se vuelve estratificada, no fragmentada.
Step 5 — Evaluación y ponderación de relaciones
Objetivo de negocio: Cuantificar la fuerza de las relaciones.
No todas las dependencias son iguales.
Ejemplo:
- Decision depends_on Risk → vínculo causal fuerte
- Question references Decision → vínculo contextual más débil
Cada arista recibe:
- Fragmento de evidencia
- Puntuación de confianza
- Referencia de origen
- ID de transacción
Ejemplo de registro de arista:
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Ahora el sistema puede responder:
- ¿Por qué se pospuso este lanzamiento?
- ¿Qué riesgos lo justificaron?
- ¿Qué tan sólido era el razonamiento?
Step 6 — Detección de conflictos (la autoridad importa)
Ahora imagina algo importante.
Hace dos meses, el CTO decidió formalmente:
“EU instance must go live before Q2 to support enterprise pipeline.”
Autoridad superior. Dirección opuesta.
El sistema detecta:
- Mismo alcance (instancia UE)
- Decisión opuesta
- Diferente rango de propietario
Y genera:
⚠ Conflicto: existe una decisión de mayor rango.
En este punto, el sistema no bloquea la realidad.
Pide validación humana.
Esto es gobernanza, no automatización.
Step 7 — Revisión humana (capa de confianza)
Objetivo de negocio: Mantener la responsabilidad.
El revisor ve un conjunto de cambios.
Crea:
- Nueva Decision
- Nuevo ActionItem
Fusiona:
- Risk → riesgo GDPR existente
Relaciones:
- Decision depends_on Risk
- ActionItem mitigates Risk
Conflicto:
- La directiva previa del CTO requiere revisión
El revisor puede:
- Aprobar
- Modificar
- Escalar
- Reemplazar explícitamente la decisión anterior
Si se reemplaza:
Decision A → supersedes → Decision BNo hay eliminación. No se reescribe la historia.
Solo evolución.
Step 8 — Commit (actualización atómica de memoria)
Una vez aprobado, el sistema confirma todo como una sola transacción.
Ahora el grafo canónico contiene:
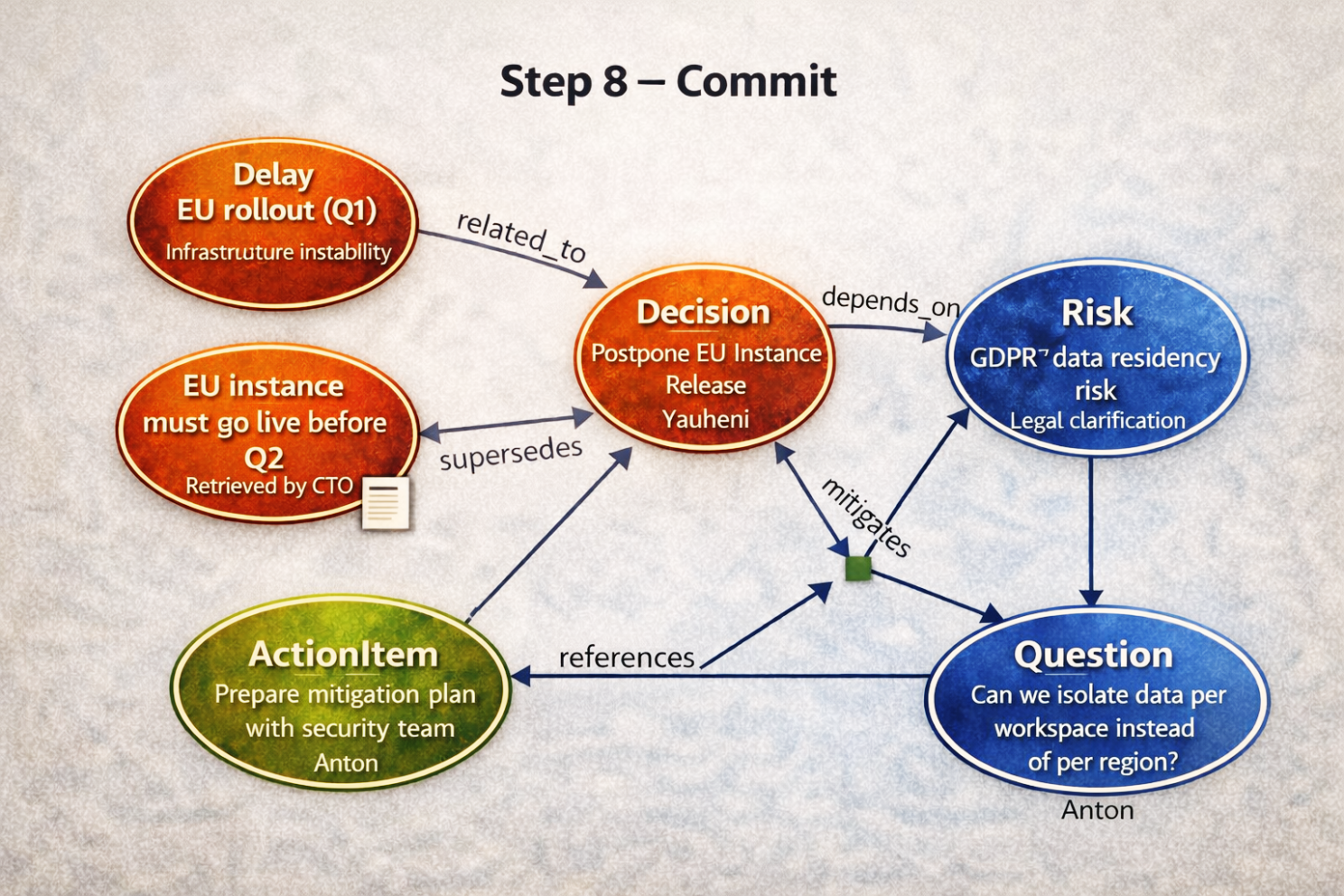
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / conflicts (si aplica)
Cada elemento registra:
- Quién lo introdujo
- Cuándo
- En qué texto se basó
- Artefactos previos vinculados
- Si anuló algo
Esto es memoria.
Por qué esto importa más allá de la arquitectura
Demos un paso atrás.
En la mayoría de las organizaciones:
- Las decisiones están dispersas
- La justificación se pierde
- La propiedad cambia
- El contexto desaparece
- La gente discute sobre la historia en lugar de resolver el problema
Con actualizaciones incrementales de provenance:
- Cada nota se convierte en gobernanza estructurada
- Cada dependencia se vuelve explícita
- Cada conflicto se hace visible
- Cada cambio se vuelve trazable
Esto no es RAG.
Esto no es solo similitud vectorial.
Esto es acumulación de capital de decisión.
El cambio mayor
Cuando el 50–80 % de la ejecución la realizan agentes de AI en lugar de ingenieros, esto se vuelve aún más crítico.
Los agentes:
- Generarán planes
- Propondrán decisiones
- Crearán action items
- Refactorizarán sistemas
- Modificarán arquitectura
Sin memoria estructurada: amplifican la entropía.
Con Provenance: operan dentro de la gobernanza.
La diferencia no es productividad.
La diferencia es supervivencia.
De retrieval a evolución
RAG responde preguntas sobre el pasado.
Provenance construye el pasado de forma incremental.
Cada ingestión:
- Extrae significado
- Resuelve identidad
- Valida autoridad
- Registra linaje
- Refuerza o actualiza la memoria previa
Con el tiempo, el grafo se convierte en:
- un historial de decisiones
- un mapa de calor de riesgos
- un libro mayor de gobernanza
- una memoria SDLC viva
Y esto sucede de forma incremental.
Una nota de reunión a la vez.