From RAG to Provenance (Part 2): How Incremental Graph Memory Actually Learns
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
In the previous article, I described the moment we realized that vector search alone is not memory.
Embeddings are excellent at finding similar text. But similarity is not lineage. It does not tell you:
- who decided what,
- based on which assumption,
- conflicting with whom,
- and when that decision was superseded.
This time, I want to show what happens next.
How does a system actually update organizational memory incrementally?
Not in theory. Not in architecture diagrams.
But step by step — using a simple real‑world example.
Step 0 — The Input (Where Memory Begins)
Let’s say this note appears after a product sync:
“Yauheni decided to postpone the EU instance release because the new GDPR clarification from legal introduces additional compliance risks. Action item: prepare mitigation plan with security team. Anton raised a question whether we can isolate data per workspace instead of per region.”
This is just text.
But inside this paragraph there are:
- Decisions
- Risks
- Questions
- Action items
- People
- Implicit dependencies
The business goal is simple:
Don’t let this disappear into Slack history. Convert it into structured, traceable organizational memory.
Actors involved
- Product lead (source author)
- Legal (implicit authority)
- Security team
- Provenance system (AI + graph memory)
- Human reviewer
Step 1 — Scribing: Turning Text into Structured Meaning
Business goal: Extract explicit artifacts so they can be governed.
The system reads the text and converts it into structured objects.
Output (simplified JSON example):
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}This is not yet memory. It’s a staged interpretation.
At this point, nothing is committed to the core graph.
Step 2 — Build a Small Staged Graph
Business goal: Represent the logic inside this one note before mixing it with global memory.
From the extracted artifacts, the system builds a small temporary graph.
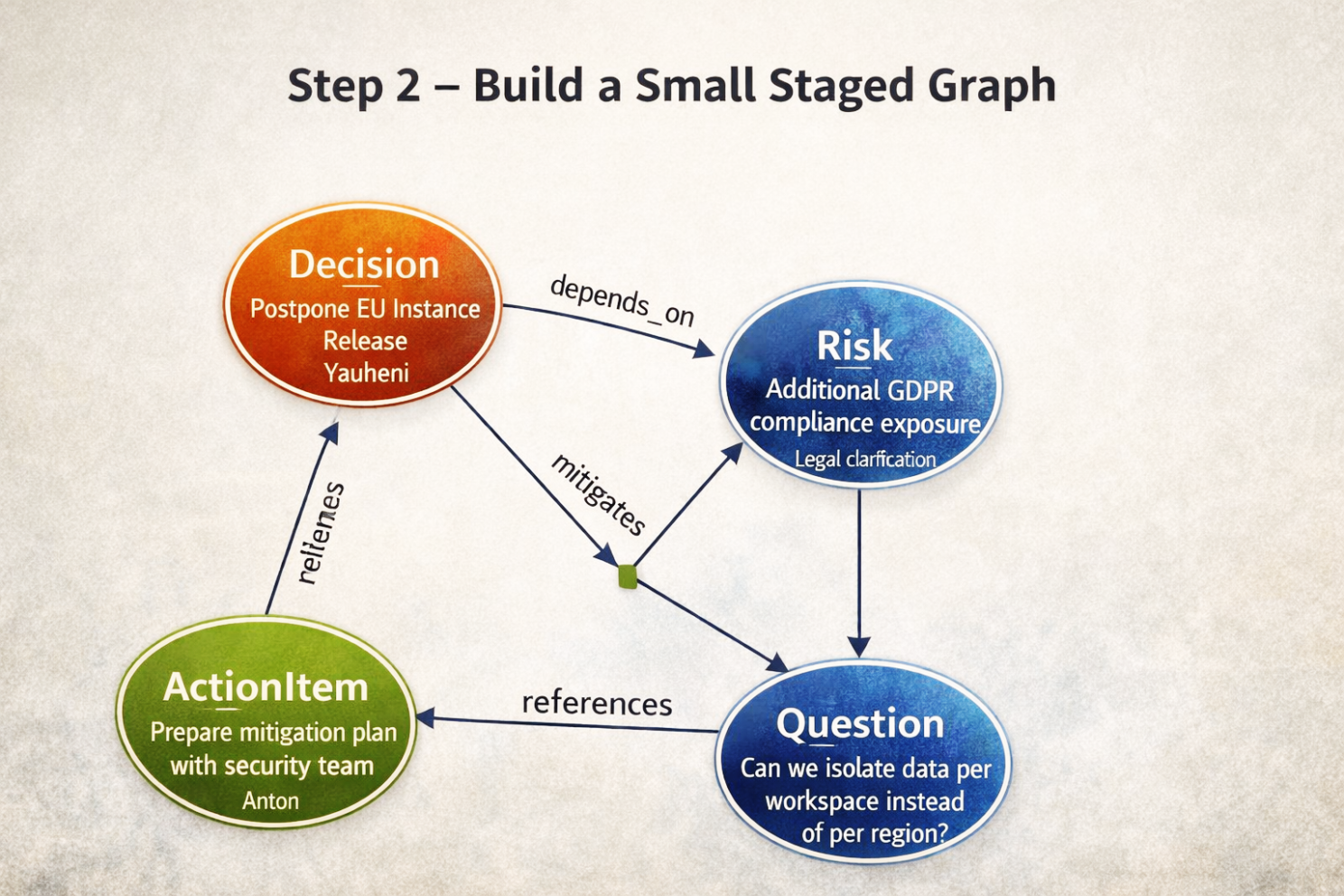
Logical structure created:
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionThis graph exists only inside the current transaction.
It is not yet part of the company’s permanent memory.
Why?
Because we don’t yet know whether:
- This risk already exists.
- The decision is a continuation of an older one.
- A higher-ranking authority previously decided something else.
Step 3 — Semantic Comparison (But Not Blindly)
Business goal: Detect whether these objects already exist in memory.
The system checks semantic similarity against existing memory.
Suppose it finds:

Now the system faces a business question:
- Are these the same things?
- Or are they related but distinct?
Vectors alone cannot answer that.
So the system retrieves context from the graph:
- Who owned the earlier decision?
- What was the reason?
- Was it temporary?
- Was it superseded?
This is where graph memory matters.
Step 4 — Identity Resolution (Merge or Create?)
Business goal: Avoid duplication without destroying nuance.
The system evaluates:
- The old “Delay EU rollout (Q1)” was due to infrastructure instability.
- The new postponement is due to legal risk.
Different reason. Different scope. Different timing.
Decision:
- ✔ Create a new Decision node
- ✔ Link it to existing GDPR risk node
If the risk already exists, we don’t duplicate it.
We strengthen it.
Memory becomes layered, not fragmented.
Step 5 — Relationship Evaluation and Weighting
Business goal: Quantify the strength of relationships.
Not all dependencies are equal.
Example:
- Decision depends_on Risk → strong causal link
- Question references Decision → weaker contextual link
Each edge receives:
- Evidence excerpt
- Confidence score
- Source reference
- Transaction ID
Example edge record:
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Now the system can answer:
- Why was this release postponed?
- Which risks justified it?
- How strong was the reasoning?
Step 6 — Conflict Detection (Authority Matters)
Now imagine something important.
Two months ago, the CTO formally decided:
“EU instance must go live before Q2 to support enterprise pipeline.”
Higher authority. Opposite direction.
The system detects:
- Same scope (EU instance)
- Opposing decision
- Different owner ranking
It raises:
⚠ Conflict: Higher-ranking decision exists.
At this point the system does not block reality.
It asks for human validation.
This is governance, not automation.
Step 7 — Human Review (Trust Layer)
Business goal: Maintain accountability.
The reviewer sees a change set.
Creates:
- New Decision
- New ActionItem
Merges:
- Risk → existing GDPR risk
Relationships:
- Decision depends_on Risk
- ActionItem mitigates Risk
Conflict:
- Prior CTO directive requires review
The reviewer can:
- Approve
- Modify
- Escalate
- Explicitly supersede the prior decision
If superseded:
Decision A → supersedes → Decision BNo deletion. No rewriting history.
Only evolution.
Step 8 — Commit (Atomic Memory Update)
Once approved, the system commits everything as one transaction.
Now the canonical graph contains:
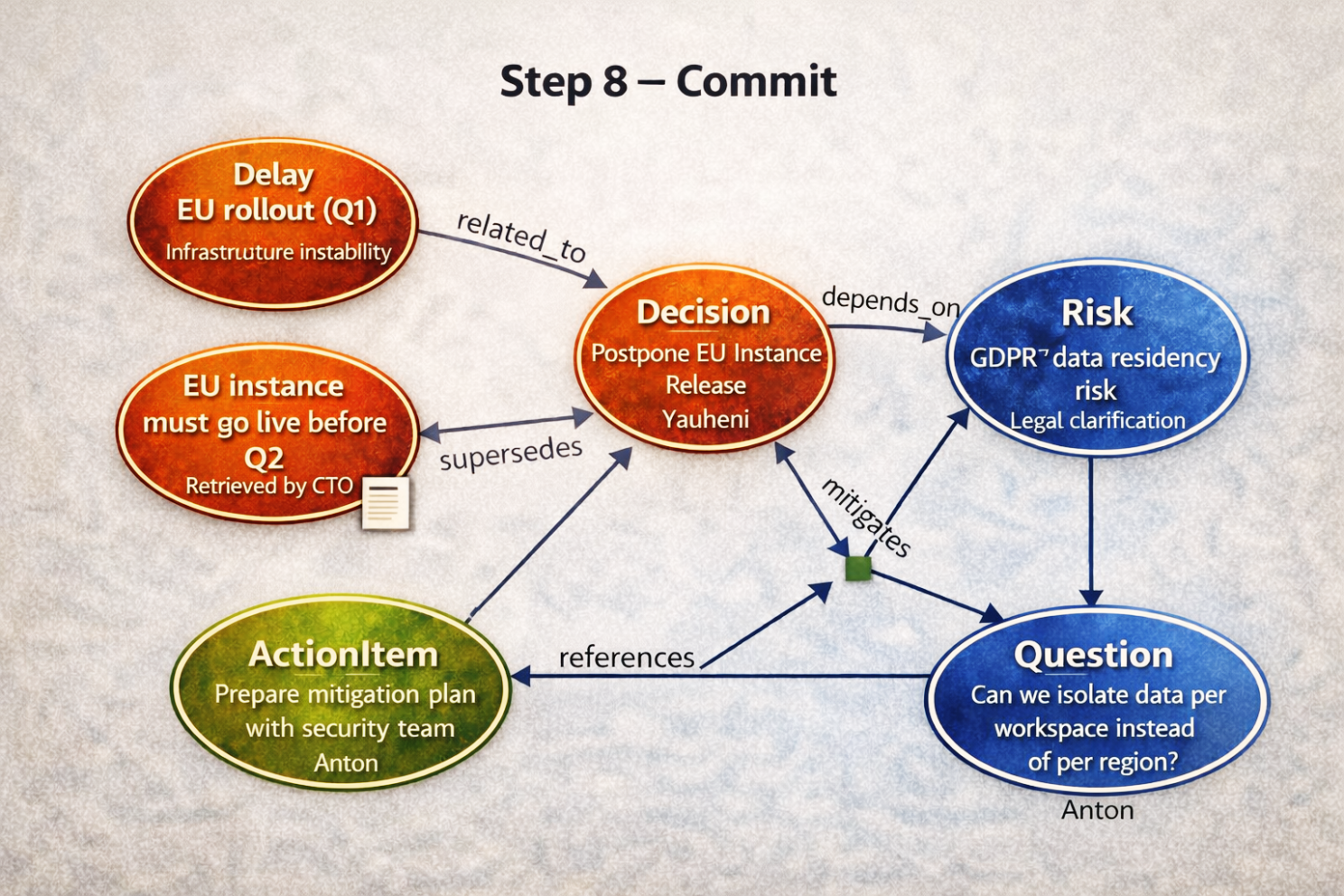
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / conflicts (if applicable)
Each element records:
- Who introduced it
- When
- Based on what text
- Linked previous artifacts
- Whether it overruled something
This is memory.
Why This Matters Beyond Architecture
Let’s step back.
In most organizations:
- Decisions are scattered
- Rationale is lost
- Ownership shifts
- Context disappears
- People argue about history instead of solving the problem.
With incremental provenance updates:
- Every note becomes structured governance
- Every dependency becomes explicit
- Every conflict becomes visible
- Every change becomes traceable
This is not RAG. This is not just vector similarity.
This is decision capital accumulation.
The Bigger Shift
When 50–80% of execution is AI agents instead of engineers, this becomes even more critical.
Agents will:
- Generate plans
- Propose decisions
- Create action items
- Refactor systems
- Modify architecture
Without structured memory: they amplify entropy.
With Provenance: they operate inside governance.
The difference is not productivity.
The difference is survivability.
From Retrieval to Evolution
RAG answers questions about the past.
Provenance builds the past incrementally.
Each ingestion:
- Extracts meaning
- Resolves identity
- Validates authority
- Records lineage
- Strengthens or updates prior memory
Over time the graph becomes:
- a decision history
- a risk heatmap
- a governance ledger
- a living SDLC memory
And this happens incrementally.
One meeting note at a time.