Guide pratique des flux agentiques
Author: Yauheni Kurbayeu
Published: Mar 22, 2026
TL;DR
Dans l’article précédent, Construire un pipeline automatisé de traduction pour un blog Markdown avec les agents GitHub Copilot, nous avons conçu un pipeline de traduction basé sur GitHub Copilot, structuré autour d’un orchestrateur, de sous-agents spécialisés par langue, de skills réutilisables et de hooks.
Cette conception a ensuite été évaluée par rapport à l’implémentation réelle du dépôt dans le rapport d’évaluation, Comment fonctionne actuellement dans ce dépôt le flux de traduction d’articles GitHub Copilot, qui montre ce que la configuration actuelle fait réellement aujourd’hui et comment les responsabilités sont effectivement réparties entre les instructions du dépôt, les agents, les skills et les hooks.
Dans cet article, nous allons un cran plus loin et transformons ces idées en guide pratique. Nous parcourons la manière dont cet espace de travail modélise l’héritage agentique, comment la superposition d’instructions remplace l’héritage natif, et comment fonctionnent les trois approches d’exécution :
- séquentielle
- parallèle
- hiérarchique
L’objectif est de vous donner un modèle de conception réutilisable pour les flux d’agents GitHub Copilot avec des instructions partagées, des workers spécialisés et des règles de coordination explicites.
Les hooks sont volontairement hors périmètre ici. Ils pourront être ajoutés plus tard pour améliorer la validation, l’observabilité et la sécurité autour du flux.
Ce que cet espace de travail démontre déjà
L’espace de travail actuel utilise une structure proche de l’héritage, construite à partir d’instructions superposées plutôt qu’à partir d’un véritable héritage de classes.
Blocs de construction principaux
- .github/copilot-instructions.md définit les règles globales pour tous les agents.
- .github/skills/shared-agent-contract/SKILL.md définit l’enveloppe de tâche commune et le contrat de retour.
- .github/skills/agents-orchestration/SKILL.md définit la manière dont un agent parent délègue le travail.
- .github/skills/worker/SKILL.md définit le comportement par défaut des agents workers.
- .github/agents/main-orchestrator.agent.md agit comme coordinateur racine.
- .github/agents/worker1.agent.md, .github/agents/worker2.agent.md et .github/agents/worker3.agent.md agissent comme workers spécialisés.
Résumé de la revue actuelle
- Le modèle d’héritage est clair et réutilisable.
- Le mode séquentiel est modélisé comme un enchaînement géré par l’orchestrateur.
- Le mode parallèle est modélisé comme un fan-out/fan-in géré par l’orchestrateur.
- Le mode hiérarchique est modélisé comme une délégation de worker à worker.
- Le mode hiérarchique change le rôle de
worker1etworker2: dans ce mode, ils ne sont plus de simples workers feuilles, même si le skill worker partagé décrit les workers comme des nœuds feuilles par défaut.
Ce dernier point n’est pas nécessairement un problème, mais c’est un choix de conception important. Si vous utilisez une exécution hiérarchique, certains workers deviennent des coordinateurs intermédiaires.
Héritage agentique
L’idée centrale
Les agents GitHub Copilot ne disposent pas d’un héritage natif. Le remplacement pratique consiste en une composition d’instructions :
- Les instructions globales jouent le rôle de classe de base.
- Les skills partagés jouent le rôle de couches réutilisables.
- Les fichiers d’agent jouent le rôle de spécialisations légères.
- Les données de tâche à l’exécution complètent le comportement.
Ce schéma vous donne la plupart des bénéfices de l’héritage :
- un contrat partagé unique
- moins de logique de prompt dupliquée
- des frontières de responsabilité plus claires
- une maintenance plus simple à mesure que le flux grandit
Priorité des instructions
L’espace de travail actuel suit cet ordre :
- .github/copilot-instructions.md
- les skills partagés référencés par un agent
- les instructions locales à l’agent dans le fichier
.agent.md - l’enveloppe de tâche d’exécution provenant de l’utilisateur ou de l’agent parent
Cela signifie qu’un agent enfant doit spécialiser les règles partagées, et non les contredire.
Carte d’héritage pour cet espace de travail
Global base
.github/copilot-instructions.md
Shared contract
.github/skills/shared-agent-contract/SKILL.md
Role-specific behavior
.github/skills/agents-orchestration/SKILL.md
.github/skills/worker/SKILL.md
Agent specializations
.github/agents/main-orchestrator.agent.md
.github/agents/worker1.agent.md
.github/agents/worker2.agent.md
.github/agents/worker3.agent.mdContrat partagé
Le contrat partagé des agents est la couche d’héritage la plus importante, car il standardise :
- l’enveloppe de tâche
- les champs d’entrée attendus
- le schéma de sortie
- la gestion des échecs
Dans cet espace de travail, l’enveloppe de tâche commune contient :
task_idobjectivemodeinput_artifactconstraintsexpected_outputparent_agent
Le contrat de retour commun contient :
statusagentsummaryresultnotes
C’est ce qui permet à plusieurs agents de coopérer sans devoir inventer un nouveau mini-protocole à chaque fois.
Modes d’exécution
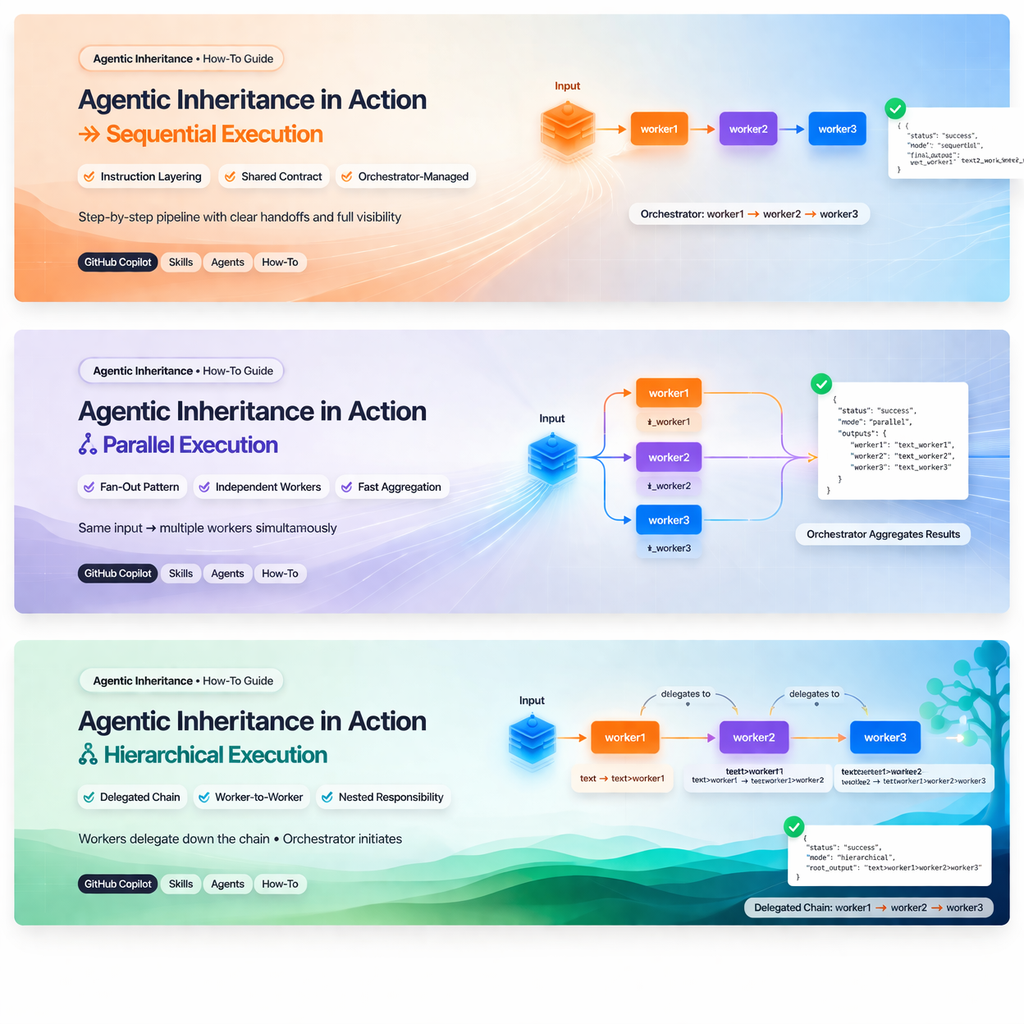
1. Mode séquentiel
Ce que cela signifie
Le mode séquentiel est un pipeline étape par étape contrôlé par l’orchestrateur.
L’orchestrateur reste responsable de chaque transmission :
main-orchestrator -> worker1 -> main-orchestrator -> worker2 -> main-orchestrator -> worker3Quand l’utiliser
- quand chaque étape dépend du résultat précédent
- quand vous voulez un contrôle et une visibilité centralisés
- quand un échec doit arrêter immédiatement le flux
Avantages
- mode le plus facile à raisonner
- contrôle maximal de l’orchestrateur
- journalisation et relances simples
Compromis
- plus lent que le mode parallèle
- l’orchestrateur se trouve sur le chemin critique entre chaque étape
Exemple
status: success
agent: main-orchestrator
summary: Ran workers 1→2→3 sequentially on the input text and returned the final transformed output.
result:
mode: sequential
steps:
- worker: worker1
input: "text to transform"
output: "text to transform_worker1"
- worker: worker2
input: "text to transform_worker1"
output: "text to transform_worker1_worker2"
- worker: worker3
input: "text to transform_worker1_worker2"
output: "text to transform_worker1_worker2_worker3"
final_output: "text to transform_worker1_worker2_worker3"
notes: Each worker appended its marker in turn, with the orchestrator coordinating the handoffs and preserving the step history.Comment l’implémenter
- L’orchestrateur reçoit l’entrée d’origine.
- L’orchestrateur envoie l’entrée à
worker1. worker1renvoie un résultat structuré.- L’orchestrateur prend
worker1.resultet l’envoie àworker2. - L’orchestrateur prend
worker2.resultet l’envoie àworker3. - L’orchestrateur renvoie la sortie finale du worker ainsi que l’historique des étapes.
2. Mode parallèle
Ce que cela signifie
Le mode parallèle est un schéma de fan-out dans lequel l’orchestrateur envoie la même entrée à plusieurs workers en même temps.
main-orchestrator -> worker1
main-orchestrator -> worker2
main-orchestrator -> worker3L’orchestrateur agrège ensuite les résultats.
Quand l’utiliser
- quand les workers sont indépendants
- quand vous voulez des sorties de comparaison
- quand la vitesse compte davantage que la dépendance d’une étape à l’autre
Avantages
- exécution plus rapide lorsque les tâches sont indépendantes
- utile pour l’expérimentation et la comparaison
- modèle d’agrégation simple
Compromis
- les workers ne peuvent pas s’appuyer les uns sur les autres
- les résultats peuvent nécessiter un post-traitement avant d’être directement comparables
Exemple
status: success
agent: main-orchestrator
summary: Ran three workers in parallel on the same input text and collected their outputs.
result:
mode: parallel
outputs:
worker1: "text Parallel_worker1"
worker2: "text Parallel_worker2"
worker3: "text Parallel_worker3"
notes: Each worker independently appended its own marker to the shared input, with the orchestrator coordinating the aggregation of results.Comment l’implémenter
- L’orchestrateur reçoit l’entrée d’origine.
- L’orchestrateur envoie le même
input_artifactà tous les workers. - Chaque worker renvoie indépendamment son propre résultat structuré.
- L’orchestrateur combine les sorties dans un objet de résultat indexé par worker.
3. Mode hiérarchique
Ce que cela signifie
Le mode hiérarchique est une chaîne déléguée dans laquelle l’orchestrateur démarre le flux, mais les workers transmettent ensuite le contrôle vers le bas de la chaîne :
main-orchestrator -> worker1 -> worker2 -> worker3Cela diffère du mode séquentiel, car l’orchestrateur n’est pas le point de transmission entre chaque étape.
Quand l’utiliser
- lorsqu’un sous-flux doit être pris en charge par les workers eux-mêmes
- lorsque vous voulez une responsabilité imbriquée
- lorsque les workers ultérieurs sont conceptuellement les enfants des workers précédents
Avantages
- prend en charge des schémas de délégation arborescents ou imbriqués
- peut réduire le bruit d’orchestration
- modélise naturellement les chaînes de traitement parent-enfant
Compromis
- plus difficile à tracer que le mode séquentiel géré par l’orchestrateur
- les agents workers cessent d’être de simples nœuds feuilles
- la gestion des échecs et l’observabilité deviennent plus complexes
Note de conception importante
Dans cet espace de travail, le mode hiérarchique est implémenté en autorisant les workers à déléguer à d’autres workers.
Cela signifie :
worker1devient le parent deworker2worker2devient le parent deworker3- seul
worker3reste une véritable feuille dans le chemin hiérarchique
C’est la principale différence conceptuelle par rapport au skill worker par défaut, qui décrit les workers comme des agents feuilles sauf configuration explicite contraire.
Exemple
status: success
agent: main-orchestrator
summary: Ran workers hierarchically (worker1 → worker2 → worker3) on the input textTree and collected each stage’s output.
result:
mode: hierarchical
hierarchy:
worker1:
input: "textTree"
output: "textTree>worker1"
worker2:
parent: "worker1"
input: "textTree>worker1"
output: "textTree>worker1>worker2"
worker3:
parent: "worker2"
input: "textTree>worker1>worker2"
output: "textTree>worker1>worker2>worker3"
root_output: "textTree>worker1>worker2>worker3"
notes: Hierarchical mode mirrors a delegated chain (each worker builds on its parent’s output); the orchestrator initiates the flow but does not manage each handoff, allowing workers to take ownership of the subflow and pass results directly to their child workers.Comment l’implémenter
- L’orchestrateur démarre le flux en appelant
worker1. worker1transforme l’entrée et transmet le résultat àworker2.worker2transforme l’entrée et transmet le résultat àworker3.worker3renvoie la sortie terminale.- Le flux renvoie le résultat final ainsi que la lignée des étapes.
Séquentiel vs parallèle vs hiérarchique
| Approche | Point de contrôle | Modèle de dépendance | Idéal pour |
|---|---|---|---|
| Séquentielle | Orchestrateur entre chaque étape | Forte dépendance entre étapes | Pipelines avec contrôle centralisé |
| Parallèle | L’orchestrateur distribue puis agrège | Workers indépendants | Vitesse, comparaison, sorties multi-variantes |
| Hiérarchique | Les workers délèguent le long de la chaîne | Dépendance parent-enfant imbriquée | Sous-flux arborescents et propriété déléguée |
Comment concevoir un flux agentique similaire
Étape 1. Définir une fois le contrat de base
Placez les règles partagées dans .github/copilot-instructions.md et gardez-les génériques :
- enveloppe de tâche
- schéma de résultat
- schéma d’échec
- contraintes de délégation
Étape 2. Déplacer le comportement réutilisable dans des skills
Utilisez un skill de contrat partagé, puis créez des skills spécifiques à chaque rôle, tels que :
- orchestration
- exécution des workers
- validation
- transformation spécifique au domaine
C’est ainsi que vous évitez de recopier la même logique de prompt dans chaque agent.
Étape 3. Garder les fichiers d’agent légers
Chaque fichier d’agent ne devrait répondre qu’aux questions suivantes :
- de quoi cet agent est-il responsable
- quels skills utilise-t-il
- quels agents enfants peut-il appeler
- ce qui le différencie des agents frères
Si une règle s’applique à de nombreux agents, elle devrait généralement être remontée vers un skill partagé ou une instruction globale.
Étape 4. Choisir le bon mode d’exécution
Utilisez :
- le mode séquentiel pour les pipelines contrôlés par l’orchestrateur
- le mode parallèle pour les branches indépendantes
- le mode hiérarchique pour les sous-arbres délégués ou les chaînes imbriquées
Ne choisissez pas le mode hiérarchique simplement parce qu’il paraît plus avancé. Il doit être utilisé lorsque la délégation portée par les workers est réellement un meilleur modèle.
Étape 5. Garder les sorties traçables
Renvoyez toujours suffisamment de structure pour permettre au parent de comprendre :
- qui a exécuté
- quelle entrée a été reçue
- quelle sortie a été produite
- si l’étape a réussi
Les exemples de sortie de cet espace de travail constituent un bon modèle, car ils préservent à la fois le résultat final et le chemin suivi pour y parvenir.
Améliorations recommandées
- Décidez si les workers doivent réellement être des agents feuilles par défaut, ou si la délégation hiérarchique est une exigence de premier ordre.
- Si le mode hiérarchique est de premier ordre, mettez à jour le texte du skill worker pour décrire plus explicitement les workers comme nœuds internes.
- Gardez le contrat partagé stable afin que tous les modes d’exécution renvoient des structures de résultat compatibles.
- Envisagez plus tard des noms de workers sémantiques, tels que
normalize,transformetfinalize, une fois le schéma stabilisé.
Conclusion
La manière la plus propre de construire un héritage agentique dans GitHub Copilot consiste à traiter l’héritage comme une architecture de prompts en couches :
- des instructions de base pour la politique universelle
- des skills partagés pour le comportement réutilisable
- des agents légers pour la spécialisation
- des modes d’exécution explicites pour le contrôle du flux
Ces trois modes d’exécution sont tous des outils utiles dans votre boîte à outils de conception :
- le mode séquentiel est le pipeline piloté par orchestrateur le plus clair
- le mode parallèle est le modèle de fan-out le plus clair
- le mode hiérarchique est le plus puissant, mais aussi le plus fortement orienté structure
Si vous introduisez un flux agentique auprès d’une nouvelle équipe, commencez par le mode séquentiel, ajoutez le mode parallèle lorsque les tâches sont indépendantes, et n’introduisez le mode hiérarchique que lorsque vous avez réellement besoin de chaînes de délégation prises en charge par les workers.
Spécifications et documentation GitHub Copilot utiles
- À propos de la personnalisation des réponses GitHub Copilot - Vue d’ensemble des instructions à l’échelle du dépôt, des instructions spécifiques aux chemins et des mécanismes de personnalisation associés.
- Ajouter des instructions personnalisées de dépôt pour GitHub Copilot - Guide pratique pour créer
.github/copilot-instructions.mdet.github/instructions/*.instructions.md. - Prise en charge des différents types d’instructions personnalisées - Matrice de référence indiquant où sont prises en charge les instructions à l’échelle du dépôt, spécifiques aux chemins, personnelles et d’organisation.
- À propos des agents personnalisés - Vue d’ensemble conceptuelle de ce que sont les agents personnalisés, de leur emplacement et de leur place dans les workflows Copilot.
- Créer des agents personnalisés pour l’agent de développement Copilot - Guide pas à pas pour créer des profils
.github/agents/*.agent.md. - Configuration des agents personnalisés - Documentation de référence pour le frontmatter des agents, les outils, les paramètres de modèle et le comportement d’invocation.
- À propos des skills d’agent - Explique ce que sont les skills et comment ils complètent les instructions et les agents personnalisés.
- Créer des skills d’agent pour GitHub Copilot - Guide pratique pour structurer
.github/skills/<skill>/SKILL.mdet les ressources associées. - À propos des hooks - Explication conceptuelle des déclencheurs de hooks, des événements du cycle de vie et des cas d’usage de gouvernance.
- Utiliser des hooks avec les agents GitHub Copilot - Guide d’implémentation pour
.github/hooks/hooks.jsonet les actions de hooks basées sur des scripts shell. - Configuration des hooks - Référence sur la structure du manifeste des hooks, les événements et les détails de configuration.
- Aide-mémoire de personnalisation Copilot - Référence compacte comparant côte à côte instructions, agents, skills, hooks et autres options de personnalisation.