De RAG à Provenance : comment nous avons compris que le vecteur seul n’est pas une mémoire
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
Dans les articles précédents, nous avons exploré une observation inconfortable : le SDLC n’a pas réellement de mémoire.
Non pas parce que nous n’écrivons pas de documentation. Non pas parce que Jira est vide. Non pas parce que les notes de réunion disparaissent.
Nous perdons la mémoire parce que nous perdons la causalité.
Des décisions sont prises, des risques sont discutés, des hypothèses se forment, des actions sont assignées, et pourtant, des mois plus tard, quand quelque chose se casse ou qu’un pivot stratégique se produit, nous ne pouvons plus reconstruire la chaîne de raisonnement qui nous a conduits là. Nous retrouvons des fragments, mais nous ne pouvons pas retracer la filiation.
C’est à ce moment-là que l’idée de Provenance est entrée dans la conversation. Non pas comme une pratique documentaire supplémentaire, ni comme une astuce d’IA, mais comme quelque chose de plus structurel — une manière de préserver l’ADN causal de la delivery. Mais dès que nous disons « nous avons besoin de mémoire », une question pratique suit immédiatement : « Quel type de modèle de données une véritable mémoire du SDLC exige-t-elle ? »
Et c’est précisément là que la plupart des équipes s’arrêtent trop tôt.
Le confort séduisant de la mémoire vectorielle
L’instinct moderne est clair. Nous prenons tout le contenu disponible — notes de réunion, tickets Jira, pages Confluence, documents de conception. Nous les découpons en chunks, les transformons en vecteurs, les stockons dans pgvector, puis récupérons les fragments pertinents par similarité sémantique. Nous enveloppons cela avec un LLM, et soudain, nous obtenons quelque chose qui semble intelligent.
Cela fonctionne. Cela paraît magique. Cela récupère du contexte plus vite qu’aucun humain ne pourrait le faire.
Mais avec le temps, quelque chose commence à sembler incomplet.
Car la recherche vectorielle ne répond qu’à un seul type de question : « Quel texte ressemble à ma requête ? »
Or, la similarité n’est pas la mémoire.
Quand le billing échoue en mars et que quelqu’un demande : « Pourquoi cela s’est-il produit ? », la similarité sémantique peut retrouver des fragments mentionnant billing et mars. Mais elle ne peut pas vous dire quelle décision a modifié la logique de facturation, si cette décision en a remplacé une précédente, quelle dépendance système a été affectée, ou quelle mitigation n’a jamais été mise en œuvre.
Les vecteurs vous donnent la pertinence. Ils ne vous donnent pas la causalité.
Et les échecs de delivery sont presque toujours causaux.
Le moment où nous avons compris qu’il nous fallait un graphe
Le basculement s’est produit quand nous avons reformulé le problème.
Au lieu de demander : « Comment retrouver des documents ? », nous avons demandé : « Comment préserver la structure du raisonnement ? »
Cette question change tout.
Nous avons cessé de penser en paragraphes et commencé à penser en entités.
- Une réunion n’est pas seulement du texte. C’est un événement qui produit des décisions.
- Une décision n’est pas seulement une phrase. Elle affecte des systèmes.
- Un risque n’est pas seulement un point de liste. C’est quelque chose qui peut être — ou non — atténué par des actions.
- Une action n’est pas seulement une tâche. Elle modifie l’état du système.
Soudain, le modèle de mémoire a cessé de ressembler à un magasin de documents et a commencé à ressembler à un graphe.
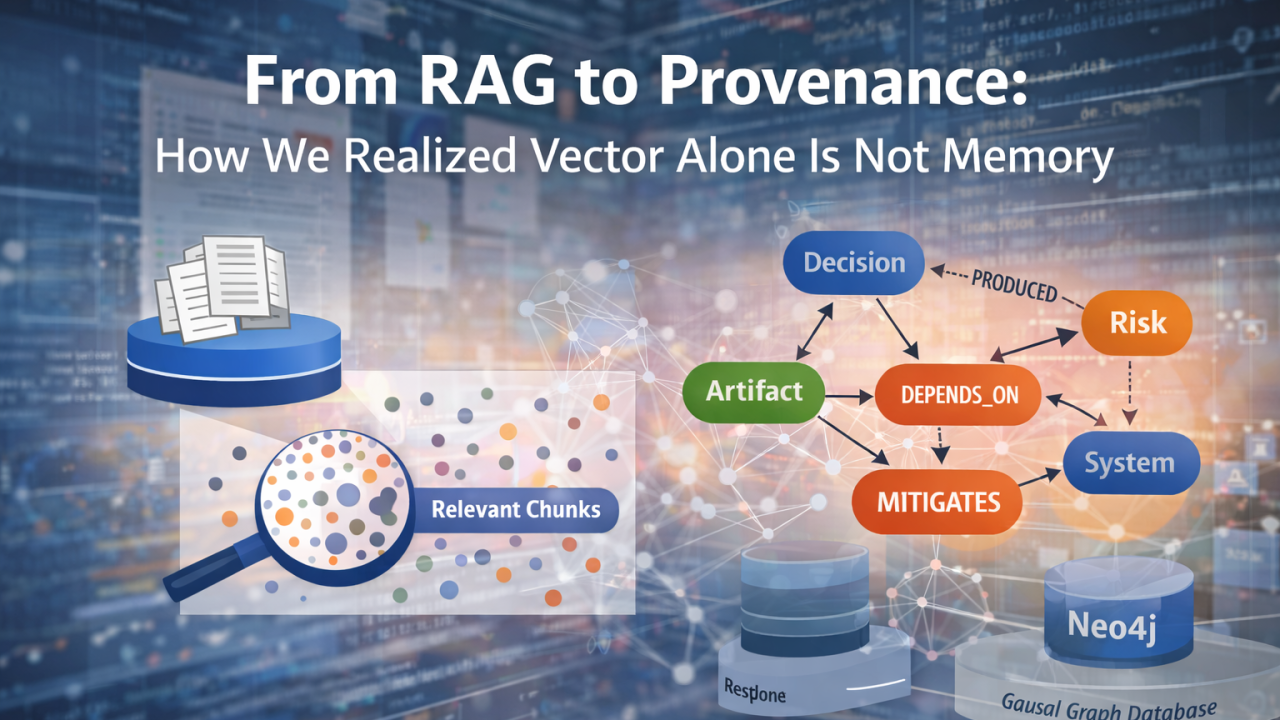
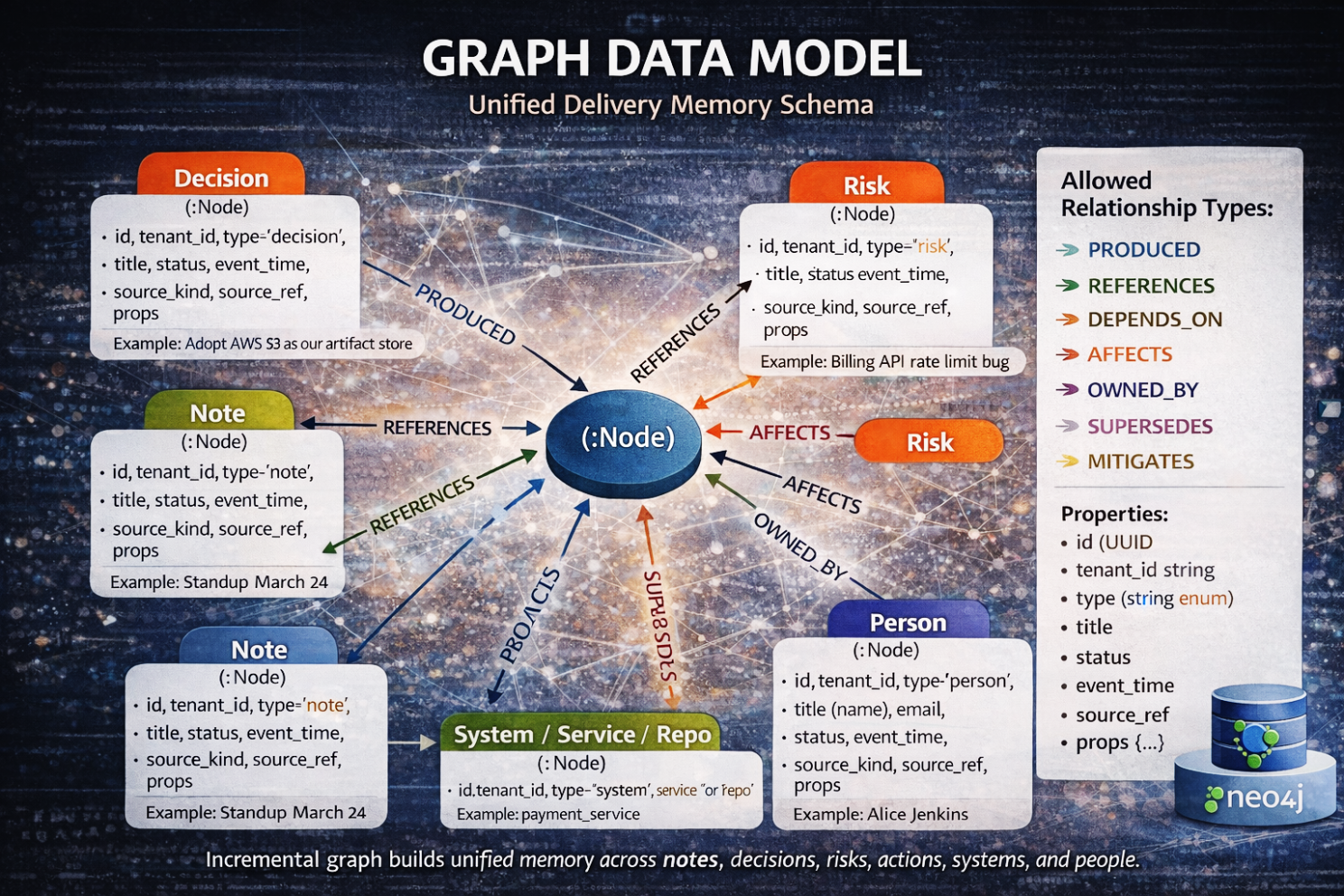
Nous avons introduit des nœuds canoniques — des entités de première classe qui existent indépendamment de tout document individuel. Notes, décisions, risques, actions, artefacts, systèmes, personnes — chacun est devenu un objet stable avec une identité. Ils sont stockés dans Postgres sous forme de dm_node, et non comme du texte embarqué.
Puis nous avons introduit des arêtes de provenance — des relations directionnelles qui capturent le sens.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
Ce ne sont pas des hyperliens. Ce sont des affirmations causales.
Et à ce moment-là, quelque chose de subtil mais puissant s’est produit : la mémoire a cessé d’être textuelle pour devenir structurelle.

Pourquoi le vecteur et le graphe comptent tous les deux
Il serait tentant de tout déplacer dans une base de données graphe et de déclarer la victoire. Mais ce serait incomplet.
Nous avons toujours besoin des vecteurs.
Parce que lorsqu’un utilisateur pose une question, nous ne savons pas par où commencer. Nous avons besoin d’un signal sémantique pour identifier les régions pertinentes de l’espace de connaissance. C’est exactement ce que pgvector nous apporte. Il nous aide à trouver rapidement et efficacement les chunks les plus pertinents.
Mais une fois ces chunks trouvés, le graphe prend le relais.
À partir des nœuds d’entrée identifiés via la recherche vectorielle, nous étendons le graphe de provenance avec Neo4j. Nous parcourons les relations pour savoir qui a produit cette décision, ce qu’elle affecte, ce qu’elle remplace, quel risque elle atténue, et ce qui dépend d’elle. Soudain, la réponse n’est plus seulement une série de fragments de texte similaires, mais un voisinage causal reconstruit.
Le vecteur nous donne le point d’entrée. Le graphe nous donne l’explication.
Ensemble, ils forment quelque chose de bien plus proche d’une mémoire organisationnelle que ce que chacun pourrait offrir seul.
Construire la mémoire de manière incrémentale, comme un renforcement neuronal
L’une des décisions architecturales les plus importantes a été la suivante : le graphe doit être global, et non propre à chaque document.
Chaque ingestion ne crée pas une île isolée. Au contraire, elle modifie et renforce une mémoire partagée.
Lorsqu’une nouvelle note fait référence à un système existant, nous réutilisons ce nœud. Lorsque deux réunions produisent la même décision avec des formulations légèrement différentes, nous la normalisons et les reconnectons. Lorsqu’une action atténue un risque déjà discuté auparavant, nous ne créons pas un nouveau risque ; nous renforçons la connexion.
Avec le temps, le graphe devient plus dense. Les arêtes gagnent en confiance. Les références répétées augmentent les compteurs de support. La mémoire de delivery devient plus cohérente.
Ce n’est pas du machine learning au sens classique, mais structurellement, cela ressemble à du renforcement.
Plus quelque chose est mentionné, lié ou mis en œuvre fréquemment, plus sa présence structurelle devient forte.
C’est ainsi que la mémoire du SDLC commence à ressembler moins à de la documentation et davantage à de la cognition.

La récupération comme conversation structurée
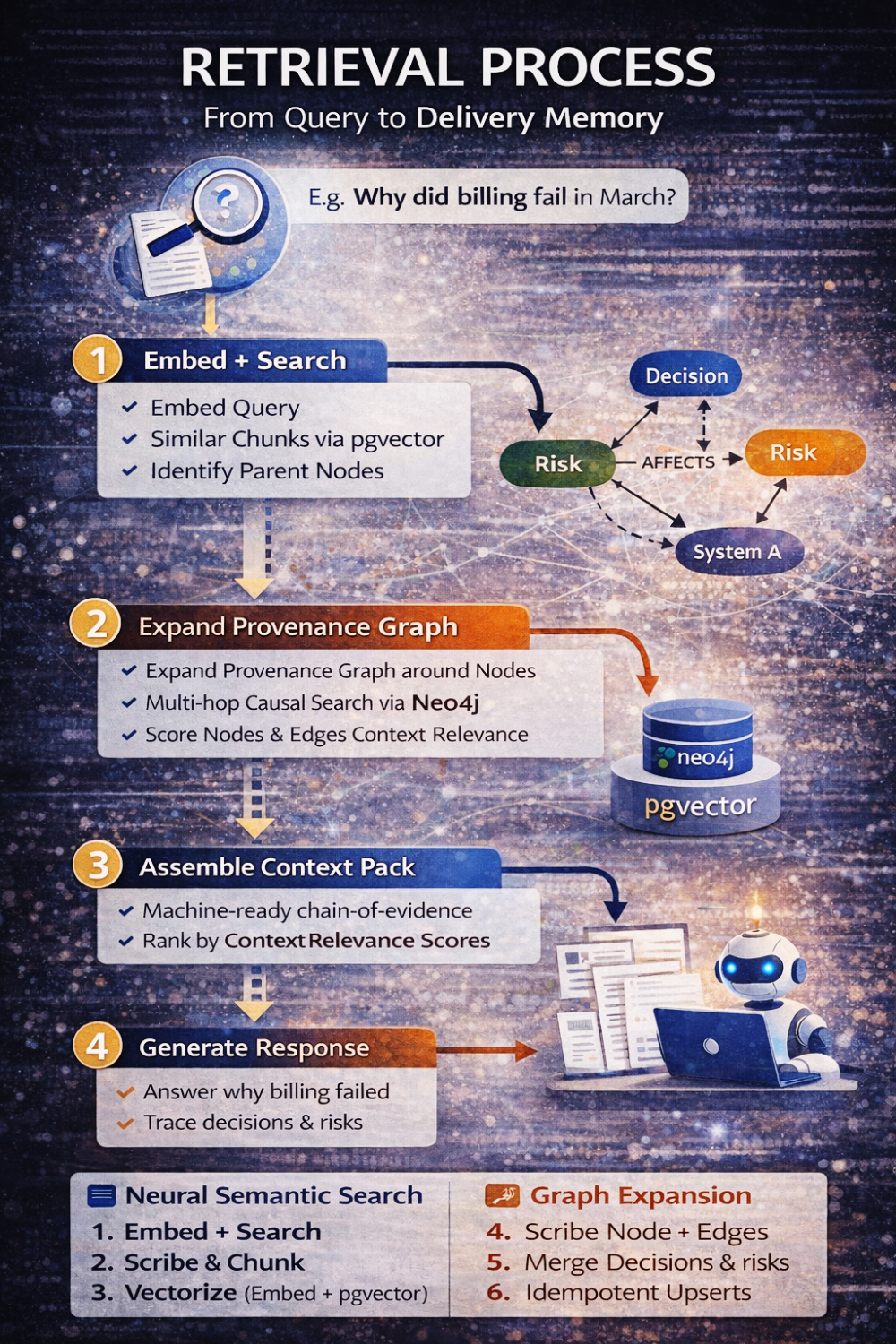
Lorsqu’aujourd’hui quelqu’un demande : « Pourquoi le billing s’est-il cassé en mars ? », le système ne se contente pas de retrouver du texte. Il effectue une conversation structurée entre deux modèles.
D’abord, il vectorise la requête et récupère les chunks sémantiquement pertinents. Ensuite, il identifie les nœuds parents de ces chunks. À partir de là, il étend le graphe de provenance jusqu’à une profondeur définie, contrainte par les types de relations et les frontières de tenant. Il assemble un paquet de contexte qui inclut non seulement du texte pertinent, mais aussi la structure causale autour — décisions, risques, actions, chaînes de supersession. Ce n’est qu’ensuite que le LLM intervient, et même alors, il est contraint de raisonner uniquement à partir de ces preuves assemblées.
Le modèle n’invente pas d’explications. Il les reconstruit.
Retour vers la thèse de la mémoire du SDLC
Plus tôt, nous avons posé une question stratégique : si l’IA remplace l’exécution, qu’est-ce qui reste précieux ?
La réponse était : le contexte et la causalité.
Cette architecture vector-plus-graph met cette thèse en pratique.
Le stockage vectoriel capture ce qui a été dit. La structure en graphe capture pourquoi cela comptait. La combinaison préserve la manière dont le système a évolué.
Sans vecteur, nous perdons la pertinence. Sans graphe, nous perdons la filiation.
Sans les deux, nous perdons la mémoire.
L’intuition la plus profonde
La plupart des équipes construiront des pipelines RAG cette année. Beaucoup croiront disposer d’une « connaissance alimentée par l’IA ».
Mais très peu construiront Provenance.
Parce que Provenance vous oblige à affronter la structure. Cela vous oblige à modéliser explicitement les décisions, à définir la directionnalité, à gérer la supersession, à imposer l’identité, à éviter la duplication, et à penser en termes de systèmes causaux plutôt qu’en termes de documents.
C’est plus exigeant que d’embedder du texte.
Mais c’est précisément pour cela que cela devient un différenciateur stratégique.
Dans un monde où l’IA peut écrire du code et rédiger de la documentation, le véritable avantage compétitif appartiendra aux organisations capables d’expliquer leur propre évolution, de retracer leurs décisions, de justifier leurs arbitrages et de faire émerger les chaînes cachées qui façonnent les résultats.
Ce n’est pas un problème de prompt engineering.
C’est un problème d’architecture de la mémoire.
Et une vraie mémoire n’est jamais plate. Elle est toujours structurée.