From RAG to Provenance (Part 2): Comment la mémoire graphique incrémentale apprend réellement
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
Dans l’article précédent, j’ai décrit le moment où nous avons réalisé que la recherche vectorielle seule n’est pas une mémoire.
Les embeddings sont excellents pour trouver des textes similaires. Mais la similarité n’est pas une lignée. Elle ne vous indique pas :
- qui a décidé quoi,
- sur quelle hypothèse la décision était basée,
- avec qui elle était en conflit,
- et quand cette décision a été remplacée.
Cette fois‑ci, je veux montrer ce qui se passe ensuite.
Comment un système met‑il réellement à jour la mémoire organisationnelle de manière incrémentale ?
Pas en théorie. Pas dans des diagrammes d’architecture.
Mais étape par étape — à l’aide d’un exemple simple du monde réel.
Step 0 — L’entrée (là où la mémoire commence)
Imaginons que cette note apparaisse après une synchronisation produit :
“Yauheni a décidé de reporter la mise en production de l’instance EU parce que la nouvelle clarification GDPR de l’équipe juridique introduit des risques supplémentaires de conformité. Action item : préparer un plan de mitigation avec l’équipe sécurité. Anton a soulevé la question de savoir si nous pouvons isoler les données par workspace plutôt que par région.”
Ceci n’est qu’un texte.
Mais à l’intérieur de ce paragraphe se trouvent :
- Des décisions
- Des risques
- Des questions
- Des actions
- Des personnes
- Des dépendances implicites
L’objectif métier est simple :
Ne laissez pas cela disparaître dans l’historique Slack. Transformez‑le en mémoire organisationnelle structurée et traçable.
Acteurs impliqués
- Product lead (auteur de la source)
- Legal (autorité implicite)
- Équipe sécurité
- Système Provenance (AI + mémoire graphique)
- Relecteur humain
Step 1 — Scribing : transformer le texte en signification structurée
Objectif métier : Extraire des artefacts explicites afin qu’ils puissent être gouvernés.
Le système lit le texte et le convertit en objets structurés.
Output (exemple JSON simplifié) :
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}Ce n’est pas encore de la mémoire. C’est une interprétation en staging.
À ce stade, rien n’est encore validé dans le graphe central.
Step 2 — Construire un petit graphe temporaire
Objectif métier : Représenter la logique contenue dans cette note avant de la mélanger avec la mémoire globale.
À partir des artefacts extraits, le système construit un petit graphe temporaire.
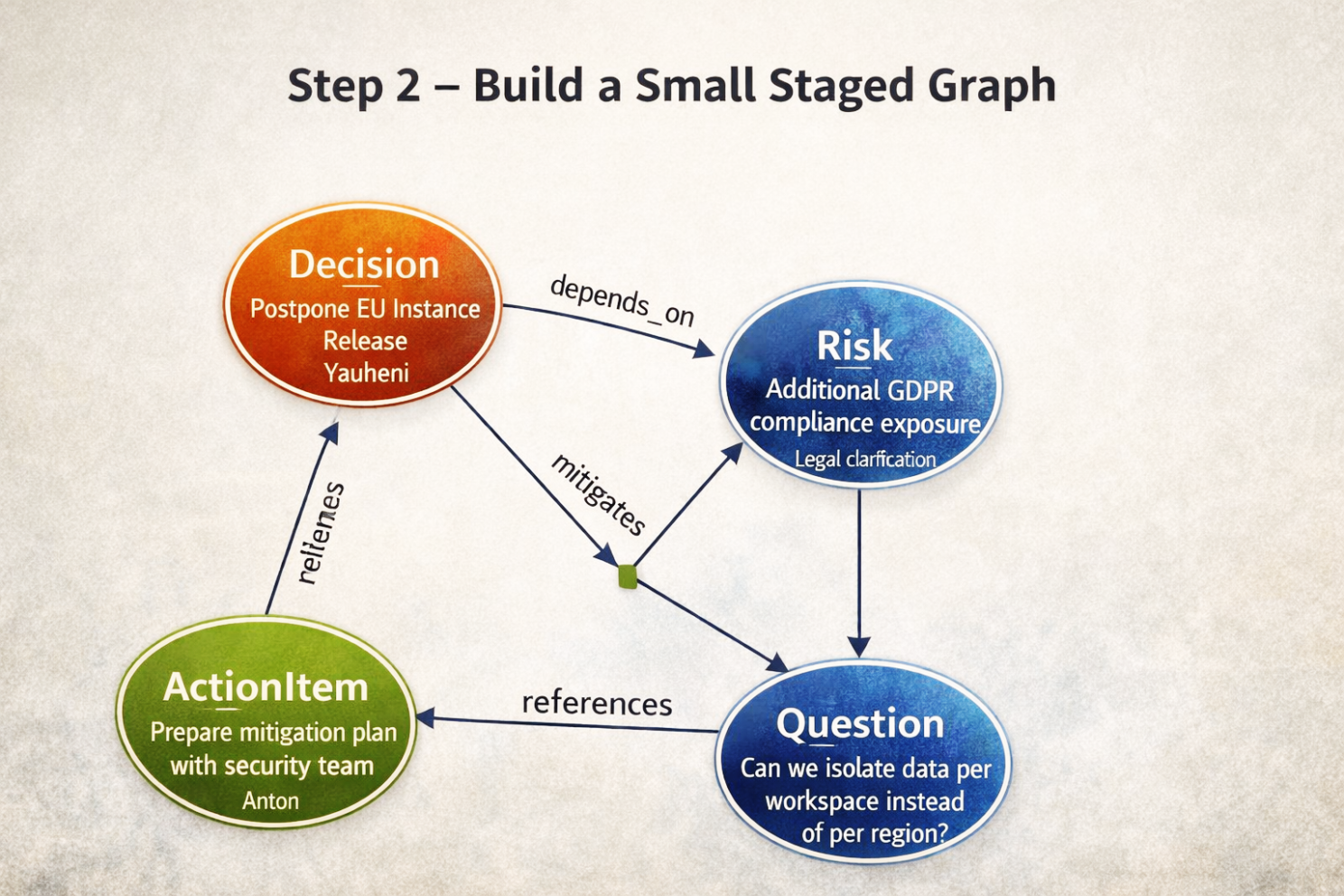
Structure logique créée :
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionCe graphe existe uniquement dans la transaction actuelle.
Il ne fait pas encore partie de la mémoire permanente de l’entreprise.
Pourquoi ?
Parce que nous ne savons pas encore si :
- Ce risque existe déjà.
- La décision est la continuation d’une décision plus ancienne.
- Une autorité de rang supérieur a déjà décidé autre chose.
Step 3 — Comparaison sémantique (mais pas aveugle)
Objectif métier : Détecter si ces objets existent déjà dans la mémoire.
Le système vérifie la similarité sémantique avec la mémoire existante.
Supposons qu’il trouve :

Le système fait alors face à une question métier :
- S’agit‑il des mêmes éléments ?
- Ou sont‑ils liés mais distincts ?
Les vecteurs seuls ne peuvent pas répondre à cela.
Le système récupère donc le contexte depuis le graphe :
- Qui possédait la décision précédente ?
- Quelle en était la raison ?
- Était‑elle temporaire ?
- A‑t‑elle été remplacée ?
C’est là que la mémoire graphique devient essentielle.
Step 4 — Résolution d’identité (fusionner ou créer ?)
Objectif métier : Éviter la duplication sans détruire la nuance.
Le système évalue :
- L’ancienne décision “Delay EU rollout (Q1)” était due à une instabilité d’infrastructure.
- Le nouveau report est dû à un risque juridique.
Raison différente. Portée différente. Moment différent.
Décision :
- ✔ Créer un nouveau nœud Decision
- ✔ Le relier au nœud de risque GDPR existant
Si le risque existe déjà, nous ne le dupliquons pas.
Nous le renforçons.
La mémoire devient stratifiée, pas fragmentée.
Step 5 — Évaluation et pondération des relations
Objectif métier : Quantifier la force des relations.
Toutes les dépendances ne sont pas équivalentes.
Exemple :
- Decision depends_on Risk → lien causal fort
- Question references Decision → lien contextuel plus faible
Chaque arête reçoit :
- Un extrait de preuve
- Un score de confiance
- Une référence de source
- Un ID de transaction
Exemple d’enregistrement :
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Le système peut désormais répondre :
- Pourquoi cette release a‑t‑elle été reportée ?
- Quels risques l’ont justifiée ?
- Quelle était la force du raisonnement ?
Step 6 — Détection des conflits (l’autorité compte)
Imaginons maintenant quelque chose d’important.
Deux mois auparavant, le CTO a décidé officiellement :
“EU instance must go live before Q2 to support enterprise pipeline.”
Autorité plus élevée. Direction opposée.
Le système détecte :
- Même périmètre (instance EU)
- Décision opposée
- Rang de propriétaire différent
Il signale :
⚠ Conflit : une décision de rang supérieur existe.
À ce stade, le système ne bloque pas la réalité.
Il demande une validation humaine.
C’est de la gouvernance, pas de l’automatisation.
Step 7 — Revue humaine (couche de confiance)
Objectif métier : Maintenir la responsabilité.
Le relecteur voit un ensemble de modifications.
Crée :
- Nouvelle Decision
- Nouveau ActionItem
Fusionne :
- Risk → risque GDPR existant
Relations :
- Decision depends_on Risk
- ActionItem mitigates Risk
Conflit :
- La directive précédente du CTO nécessite une revue
Le relecteur peut :
- Approuver
- Modifier
- Escalader
- Remplacer explicitement la décision précédente
Si elle est remplacée :
Decision A → supersedes → Decision BAucune suppression. Aucune réécriture de l’histoire.
Seulement une évolution.
Step 8 — Commit (mise à jour atomique de la mémoire)
Une fois approuvé, le système valide tout dans une seule transaction.
Le graphe canonique contient maintenant :
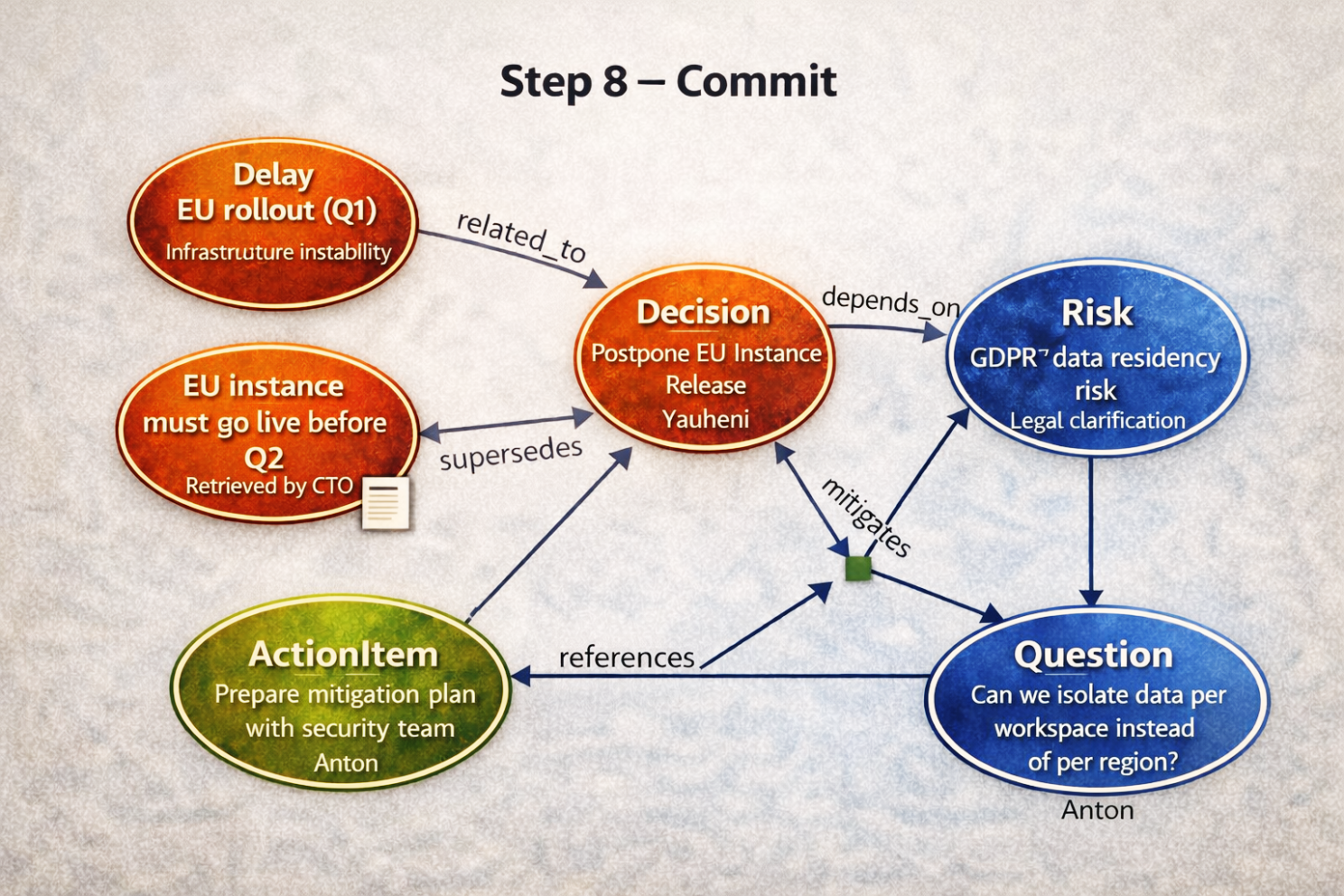
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / conflits (si applicable)
Chaque élément enregistre :
- Qui l’a introduit
- Quand
- Sur quel texte
- Les artefacts précédents liés
- S’il a annulé quelque chose
Ceci est de la mémoire.
Pourquoi cela dépasse l’architecture
Prenons un peu de recul.
Dans la plupart des organisations :
- Les décisions sont dispersées
- Les justifications se perdent
- La responsabilité change
- Le contexte disparaît
- Les gens débattent de l’histoire au lieu de résoudre le problème
Avec des mises à jour incrémentales de provenance :
- Chaque note devient une gouvernance structurée
- Chaque dépendance devient explicite
- Chaque conflit devient visible
- Chaque changement devient traçable
Ce n’est pas du RAG.
Ce n’est pas seulement de la similarité vectorielle.
C’est l’accumulation de capital décisionnel.
Le changement majeur
Lorsque 50 à 80 % de l’exécution est réalisée par des agents AI plutôt que par des ingénieurs, cela devient encore plus critique.
Les agents vont :
- Générer des plans
- Proposer des décisions
- Créer des actions
- Refactoriser des systèmes
- Modifier l’architecture
Sans mémoire structurée : ils amplifient l’entropie.
Avec Provenance : ils opèrent à l’intérieur de la gouvernance.
La différence n’est pas la productivité.
La différence est la survivabilité.
De la récupération à l’évolution
RAG répond à des questions sur le passé.
Provenance construit le passé de manière incrémentale.
Chaque ingestion :
- Extrait le sens
- Résout l’identité
- Valide l’autorité
- Enregistre la lignée
- Renforce ou met à jour la mémoire existante
Avec le temps, le graphe devient :
- un historique des décisions
- une heatmap des risques
- un registre de gouvernance
- une mémoire SDLC vivante
Et cela se produit de manière incrémentale.
Une note de réunion à la fois.