Przewodnik po Agentic Flow
Author: Yauheni Kurbayeu
Published: Mar 22, 2026
TL;DR
W poprzednim artykule, Jak zbudować zautomatyzowany pipeline tłumaczeń dla bloga Markdown przy użyciu agentów GitHub Copilot, zaprojektowaliśmy pipeline tłumaczeń oparty na GitHub Copilot, zbudowany wokół orkiestratora, podagentów specyficznych dla języków, wielokrotnego użytku skills oraz hooków.
Ten projekt został następnie oceniony na tle rzeczywistej implementacji repozytorium w raporcie oceniającym, Jak działa obecny przepływ tłumaczenia artykułów GitHub Copilot w tym repozytorium, który pokazuje, co obecna konfiguracja faktycznie robi dzisiaj i jak odpowiedzialności są naprawdę rozdzielone pomiędzy instrukcje repozytorium, agentów, skills i hooki.
W tym artykule idziemy o krok dalej i zamieniamy te idee w praktyczny przewodnik. Pokazujemy, jak ten workspace modeluje agentic inheritance, jak warstwowanie instrukcji zastępuje natywne dziedziczenie oraz jak działają trzy podejścia wykonawcze:
- sekwencyjne
- równoległe
- hierarchiczne
Celem jest dostarczenie Ci wzorca projektowego wielokrotnego użytku dla przepływów agentów GitHub Copilot, ze współdzielonymi instrukcjami, wyspecjalizowanymi workerami i jasnymi regułami koordynacji.
Hooki są tutaj celowo poza zakresem. Można je dodać później, aby poprawić walidację, obserwowalność i bezpieczeństwo wokół przepływu.
Co ten workspace już demonstruje
Obecny workspace wykorzystuje strukturę podobną do dziedziczenia, zbudowaną z warstwowych instrukcji, a nie z prawdziwego dziedziczenia klas.
Główne elementy składowe
- .github/copilot-instructions.md definiuje globalne reguły dla wszystkich agentów.
- .github/skills/shared-agent-contract/SKILL.md definiuje wspólną otoczkę zadania i kontrakt zwracanych danych.
- .github/skills/agents-orchestration/SKILL.md definiuje, jak agent nadrzędny deleguje pracę.
- .github/skills/worker/SKILL.md definiuje domyślne zachowanie agentów typu worker.
- .github/agents/main-orchestrator.agent.md pełni rolę głównego koordynatora.
- .github/agents/worker1.agent.md, .github/agents/worker2.agent.md oraz .github/agents/worker3.agent.md pełnią rolę wyspecjalizowanych workerów.
Podsumowanie obecnego przeglądu
- Model dziedziczenia jest jasny i wielokrotnego użytku.
- Tryb sekwencyjny jest modelowany jako łańcuch zarządzany przez orkiestratora.
- Tryb równoległy jest modelowany jako rozgałęzienie i scalenie zarządzane przez orkiestratora.
- Tryb hierarchiczny jest modelowany jako delegacja worker-do-workera.
- Tryb hierarchiczny zmienia rolę
worker1iworker2: w tym trybie nie są już czystymi workerami liściowymi, mimo że współdzielony skill workera domyślnie opisuje workerów jako węzły liściowe.
Ten ostatni punkt nie musi być błędem, ale jest ważną decyzją projektową. Jeśli używasz wykonania hierarchicznego, część workerów staje się pośrednimi koordynatorami.
Agentyczne dziedziczenie
Główna idea
Agenci GitHub Copilot nie mają natywnego dziedziczenia. Praktycznym zamiennikiem jest kompozycja instrukcji:
- Instrukcje globalne pełnią rolę klasy bazowej.
- Współdzielone skills pełnią rolę warstw ról wielokrotnego użytku.
- Pliki agentów pełnią rolę cienkich specjalizacji.
- Dane zadania dostarczane w runtime dopełniają zachowanie.
Ten wzorzec daje większość korzyści dziedziczenia:
- jeden wspólny kontrakt
- mniej zduplikowanej logiki promptów
- wyraźniejsze granice odpowiedzialności
- łatwiejsze utrzymanie, gdy przepływ się rozrasta
Priorytet instrukcji
Obecny workspace stosuje następującą kolejność:
- .github/copilot-instructions.md
- współdzielone skills wskazane przez agenta
- instrukcje lokalne agenta w pliku
.agent.md - otoczka zadania dostarczona w runtime przez użytkownika lub agenta nadrzędnego
Oznacza to, że agent potomny powinien specjalizować współdzielone reguły, a nie im zaprzeczać.
Mapa dziedziczenia dla tego workspace
Global base
.github/copilot-instructions.md
Shared contract
.github/skills/shared-agent-contract/SKILL.md
Role-specific behavior
.github/skills/agents-orchestration/SKILL.md
.github/skills/worker/SKILL.md
Agent specializations
.github/agents/main-orchestrator.agent.md
.github/agents/worker1.agent.md
.github/agents/worker2.agent.md
.github/agents/worker3.agent.mdWspólny kontrakt
Wspólny kontrakt agentów jest najważniejszą warstwą dziedziczenia, ponieważ standaryzuje:
- otoczkę zadania
- oczekiwane pola wejściowe
- schemat wyjściowy
- obsługę błędów
W tym workspace wspólna otoczka zadania zawiera:
task_idobjectivemodeinput_artifactconstraintsexpected_outputparent_agent
Wspólny kontrakt zwracanych danych zawiera:
statusagentsummaryresultnotes
To właśnie pozwala wielu agentom współpracować bez wymyślania nowego mini-protokołu za każdym razem.
Tryby wykonania
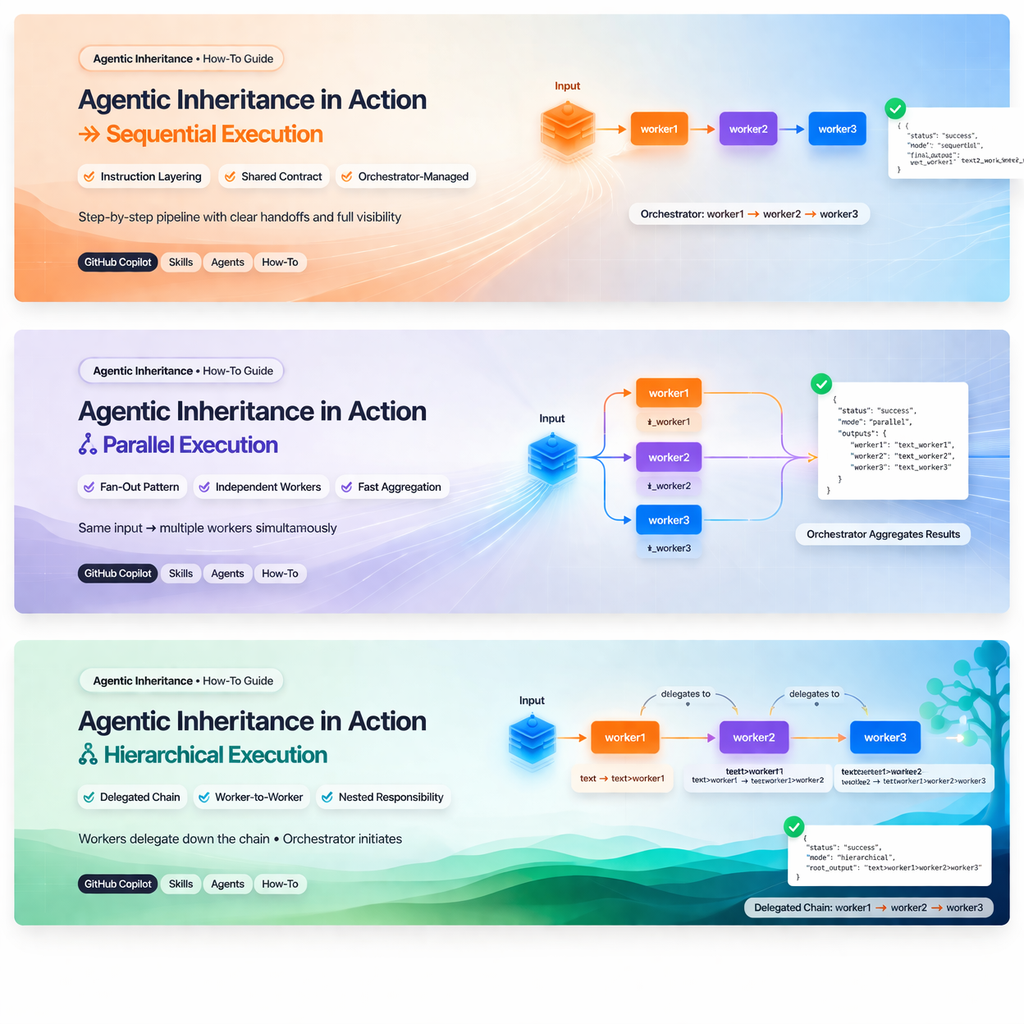
1. Tryb sekwencyjny
Co to oznacza
Tryb sekwencyjny to krok po kroku pipeline kontrolowany przez orkiestratora.
Orkiestrator pozostaje odpowiedzialny za każde przekazanie:
main-orchestrator -> worker1 -> main-orchestrator -> worker2 -> main-orchestrator -> worker3Kiedy go używać
- gdy każdy krok zależy od poprzedniego wyniku
- gdy chcesz scentralizowanej kontroli i widoczności
- gdy awaria powinna natychmiast zatrzymać przepływ
Zalety
- najłatwiejszy tryb do zrozumienia
- najsilniejsza kontrola orkiestratora
- proste logowanie i ponawianie prób
Kompromisy
- wolniejszy niż tryb równoległy
- orkiestrator znajduje się na ścieżce krytycznej pomiędzy każdym krokiem
Przykład
status: success
agent: main-orchestrator
summary: Ran workers 1→2→3 sequentially on the input text and returned the final transformed output.
result:
mode: sequential
steps:
- worker: worker1
input: "text to transform"
output: "text to transform_worker1"
- worker: worker2
input: "text to transform_worker1"
output: "text to transform_worker1_worker2"
- worker: worker3
input: "text to transform_worker1_worker2"
output: "text to transform_worker1_worker2_worker3"
final_output: "text to transform_worker1_worker2_worker3"
notes: Each worker appended its marker in turn, with the orchestrator coordinating the handoffs and preserving the step history.Jak to zaimplementować
- Orkiestrator otrzymuje oryginalne dane wejściowe.
- Orkiestrator wysyła dane wejściowe do
worker1. worker1zwraca ustrukturyzowany wynik.- Orkiestrator pobiera
worker1.resulti wysyła go doworker2. - Orkiestrator pobiera
worker2.resulti wysyła go doworker3. - Orkiestrator zwraca końcowy wynik workera wraz z historią kroków.
2. Tryb równoległy
Co to oznacza
Tryb równoległy to wzorzec fan-out, w którym orkiestrator wysyła te same dane wejściowe do wielu workerów w tym samym czasie.
main-orchestrator -> worker1
main-orchestrator -> worker2
main-orchestrator -> worker3Następnie orkiestrator agreguje wyniki.
Kiedy go używać
- gdy workerzy są niezależni
- gdy chcesz uzyskać wyniki porównawcze
- gdy szybkość ma większe znaczenie niż zależność krok po kroku
Zalety
- szybsze wykonanie, gdy zadania są niezależne
- dobre do eksperymentów i porównań
- prosty model agregacji
Kompromisy
- workerzy nie mogą budować jedni na drugich
- wyniki mogą wymagać przetwarzania końcowego, zanim będą bezpośrednio porównywalne
Przykład
status: success
agent: main-orchestrator
summary: Ran three workers in parallel on the same input text and collected their outputs.
result:
mode: parallel
outputs:
worker1: "text Parallel_worker1"
worker2: "text Parallel_worker2"
worker3: "text Parallel_worker3"
notes: Each worker independently appended its own marker to the shared input, with the orchestrator coordinating the aggregation of results.Jak to zaimplementować
- Orkiestrator otrzymuje oryginalne dane wejściowe.
- Orkiestrator wysyła ten sam
input_artifactdo wszystkich workerów. - Każdy worker niezależnie zwraca własny ustrukturyzowany wynik.
- Orkiestrator łączy wyniki w obiekt rezultatów z kluczami odpowiadającymi workerom.
3. Tryb hierarchiczny
Co to oznacza
Tryb hierarchiczny to delegowany łańcuch, w którym orkiestrator uruchamia przepływ, ale workerzy przekazują sterowanie dalej w dół:
main-orchestrator -> worker1 -> worker2 -> worker3Różni się to od trybu sekwencyjnego, ponieważ orkiestrator nie jest punktem przekazania pomiędzy kolejnymi etapami.
Kiedy go używać
- gdy podprzepływ powinien być własnością samych workerów
- gdy chcesz zagnieżdżonej odpowiedzialności
- gdy późniejsi workerzy są koncepcyjnie dziećmi wcześniejszych workerów
Zalety
- wspiera wzorce delegacji przypominające drzewo lub zagnieżdżone struktury
- może ograniczyć natężenie komunikacji z orkiestratorem
- naturalnie modeluje łańcuchy przetwarzania rodzic-dziecko
Kompromisy
- trudniejszy do śledzenia niż sekwencyjny tryb zarządzany przez orkiestratora
- agenci typu worker przestają być czystymi węzłami liściowymi
- obsługa błędów i obserwowalność stają się bardziej złożone
Ważna uwaga projektowa
W tym workspace tryb hierarchiczny jest realizowany poprzez umożliwienie workerom delegowania pracy innym workerom.
Oznacza to, że:
worker1staje się rodzicemworker2worker2staje się rodzicemworker3- tylko
worker3pozostaje prawdziwym liściem w ścieżce hierarchicznej
To główna różnica koncepcyjna względem domyślnego skilla workera, który opisuje workerów jako agentów liściowych, o ile nie zostaną wyraźnie skonfigurowani inaczej.
Przykład
status: success
agent: main-orchestrator
summary: Ran workers hierarchically (worker1 → worker2 → worker3) on the input textTree and collected each stage’s output.
result:
mode: hierarchical
hierarchy:
worker1:
input: "textTree"
output: "textTree>worker1"
worker2:
parent: "worker1"
input: "textTree>worker1"
output: "textTree>worker1>worker2"
worker3:
parent: "worker2"
input: "textTree>worker1>worker2"
output: "textTree>worker1>worker2>worker3"
root_output: "textTree>worker1>worker2>worker3"
notes: Hierarchical mode mirrors a delegated chain (each worker builds on its parent’s output); the orchestrator initiates the flow but does not manage each handoff, allowing workers to take ownership of the subflow and pass results directly to their child workers.Jak to zaimplementować
- Orkiestrator uruchamia przepływ, wywołując
worker1. worker1przekształca dane wejściowe i przekazuje wynik doworker2.worker2przekształca dane wejściowe i przekazuje wynik doworker3.worker3zwraca końcowy wynik.- Przepływ zwraca wynik końcowy razem z rodowodem etapów.
Sekwencyjny vs równoległy vs hierarchiczny
| Podejście | Punkt kontroli | Model zależności | Najlepsze zastosowanie |
|---|---|---|---|
| Sekwencyjne | Orkiestrator pomiędzy każdym krokiem | Silna zależność między krokami | Pipeline’y ze scentralizowaną kontrolą |
| Równoległe | Orkiestrator rozsyła i agreguje | Niezależni workerzy | Szybkość, porównania, wyniki wielu wariantów |
| Hierarchiczne | Workerzy delegują dalej w łańcuchu | Zagnieżdżona zależność rodzic-dziecko | Podprzepływy drzewiaste i delegowana odpowiedzialność |
Jak zaprojektować podobny Agentic Flow
Krok 1. Zdefiniuj kontrakt bazowy tylko raz
Umieść współdzielone reguły w .github/copilot-instructions.md i zachowaj ich ogólny charakter:
- otoczka zadania
- schemat wyniku
- schemat błędu
- ograniczenia delegowania
Krok 2. Przenieś zachowania wielokrotnego użytku do skills
Użyj jednego współdzielonego skilla kontraktowego, a następnie utwórz skille specyficzne dla ról, takie jak:
- orkiestracja
- wykonanie workera
- walidacja
- transformacja specyficzna dla domeny
W ten sposób unikasz kopiowania tej samej logiki promptów do każdego agenta.
Krok 3. Zachowaj cienkie pliki agentów
Każdy plik agenta powinien odpowiadać tylko na następujące pytania:
- za co odpowiada ten agent
- z których skills korzysta
- których agentów potomnych może wywoływać
- czym różni się od agentów równorzędnych
Jeśli jakaś reguła dotyczy wielu agentów, zazwyczaj powinna zostać przeniesiona wyżej do współdzielonego skilla albo globalnej instrukcji.
Krok 4. Wybierz właściwy tryb wykonania
Używaj:
- trybu sekwencyjnego dla pipeline’ów kontrolowanych przez orkiestratora
- trybu równoległego dla niezależnych gałęzi
- trybu hierarchicznego dla delegowanych poddrzew lub zagnieżdżonych łańcuchów
Nie wybieraj trybu hierarchicznego tylko dlatego, że wygląda bardziej zaawansowanie. Należy go stosować wtedy, gdy delegowanie będące własnością workerów jest rzeczywiście lepszym modelem.
Krok 5. Dbaj o śledzalność wyników
Zawsze zwracaj wystarczająco dużo struktury, aby agent nadrzędny mógł zrozumieć:
- kto wykonał zadanie
- jakie dane wejściowe otrzymał
- jaki wynik wytworzył
- czy krok zakończył się sukcesem
Przykładowe wyniki w tym workspace są dobrym wzorcem, ponieważ zachowują zarówno wynik końcowy, jak i ścieżkę prowadzącą do jego uzyskania.
Zalecane usprawnienia
- Zdecyduj, czy workerzy powinni domyślnie naprawdę być agentami liściowymi, czy też delegacja hierarchiczna jest wymaganiem pierwszej klasy.
- Jeśli tryb hierarchiczny jest wymaganiem pierwszej klasy, zaktualizuj opis skilla workera tak, aby wyraźniej opisywał workerów będących węzłami wewnętrznymi.
- Utrzymuj stabilność wspólnego kontraktu, aby wszystkie tryby wykonania zwracały kompatybilne struktury wyników.
- Rozważ później bardziej semantyczne nazwy workerów, takie jak
normalize,transformifinalize, gdy wzorzec się ustabilizuje.
Końcowy wniosek
Najczystszym sposobem budowania agentic inheritance w GitHub Copilot jest traktowanie dziedziczenia jako warstwowej architektury promptów:
- instrukcje bazowe dla uniwersalnej polityki
- współdzielone skills dla zachowań wielokrotnego użytku
- cienkie agenty dla specjalizacji
- jawne tryby wykonania do kontroli przepływu
Te trzy tryby wykonania są wartościowymi narzędziami w Twoim zestawie projektowym:
- sekwencyjny to najczytelniejszy pipeline prowadzony przez orkiestratora
- równoległy to najczytelniejszy model fan-out
- hierarchiczny jest najpotężniejszy, ale też najbardziej strukturalnie opiniotwórczy
Jeśli wprowadzasz agentic flow do nowego zespołu, zacznij od trybu sekwencyjnego, dodaj równoległy, gdy zadania są niezależne, a hierarchiczny wprowadzaj dopiero wtedy, gdy naprawdę potrzebujesz łańcuchów delegacji będących własnością workerów.
Przydatne specyfikacje i dokumentacja GitHub Copilot
- Informacje o dostosowywaniu odpowiedzi GitHub Copilot - Przegląd instrukcji obejmujących całe repozytorium, instrukcji zależnych od ścieżki oraz powiązanych mechanizmów dostosowywania.
- Dodawanie niestandardowych instrukcji repozytorium dla GitHub Copilot - Praktyczny przewodnik po tworzeniu
.github/copilot-instructions.mdoraz.github/instructions/*.instructions.md. - Obsługa różnych typów niestandardowych instrukcji - Macierz referencyjna pokazująca, gdzie obsługiwane są instrukcje obejmujące całe repozytorium, zależne od ścieżki, osobiste i organizacyjne.
- Informacje o niestandardowych agentach - Koncepcyjny przegląd tego, czym są niestandardowi agenci, gdzie się znajdują i jak wpisują się w przepływy pracy Copilota.
- Tworzenie niestandardowych agentów dla GitHub Copilot coding agent - Przewodnik krok po kroku po tworzeniu profili
.github/agents/*.agent.md. - Konfiguracja niestandardowych agentów - Dokumentacja referencyjna dla frontmatter agentów, narzędzi, ustawień modelu i zachowania przy wywołaniu.
- Informacje o skills agentów - Wyjaśnia, czym są skills i jak uzupełniają instrukcje oraz niestandardowych agentów.
- Tworzenie skills agentów dla GitHub Copilot - Praktyczny przewodnik po strukturze
.github/skills/<skill>/SKILL.mdi powiązanych zasobów. - Informacje o hookach - Koncepcyjne wyjaśnienie triggerów hooków, zdarzeń cyklu życia i przypadków użycia związanych z governance.
- Używanie hooków z agentami GitHub Copilot - Przewodnik wdrożeniowy dla
.github/hooks/hooks.jsoni akcji hooków opartych na shellu. - Konfiguracja hooków - Materiał referencyjny dotyczący struktury manifestu hooków, zdarzeń i szczegółów konfiguracji.
- Ściągawka dostosowywania Copilota - Zwięzły materiał referencyjny porównujący instrukcje, agentów, skills, hooki i inne opcje dostosowywania obok siebie.