Od RAG do Provenance: jak zrozumieliśmy, że same wektory nie są pamięcią
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
W poprzednich artykułach przyglądaliśmy się niewygodnej obserwacji: SDLC tak naprawdę nie ma pamięci.
Nie dlatego, że nie piszemy dokumentacji. Nie dlatego, że Jira jest pusta. Nie dlatego, że notatki ze spotkań znikają.
Tracimy pamięć, ponieważ tracimy przyczynowość.
Podejmowane są decyzje, omawiane są ryzyka, formowane są założenia, przypisywane są action items, a jednak po miesiącach, gdy coś się psuje albo następuje strategiczny pivot, nie potrafimy odtworzyć łańcucha rozumowania, który nas do tego doprowadził. Odzyskujemy fragmenty, ale nie potrafimy prześledzić ich pochodzenia.
Właśnie wtedy do rozmowy weszła idea Provenance. Nie jako kolejna praktyka dokumentacyjna i nie jako trik AI, lecz jako coś bardziej strukturalnego — sposób na zachowanie przyczynowego DNA delivery. Ale gdy tylko mówimy „potrzebujemy pamięci”, natychmiast pojawia się praktyczne pytanie: „Jakiego modelu danych wymaga prawdziwa pamięć SDLC?”
I właśnie tutaj większość zespołów zatrzymuje się zbyt wcześnie.
Zwodniczy komfort pamięci wektorowej
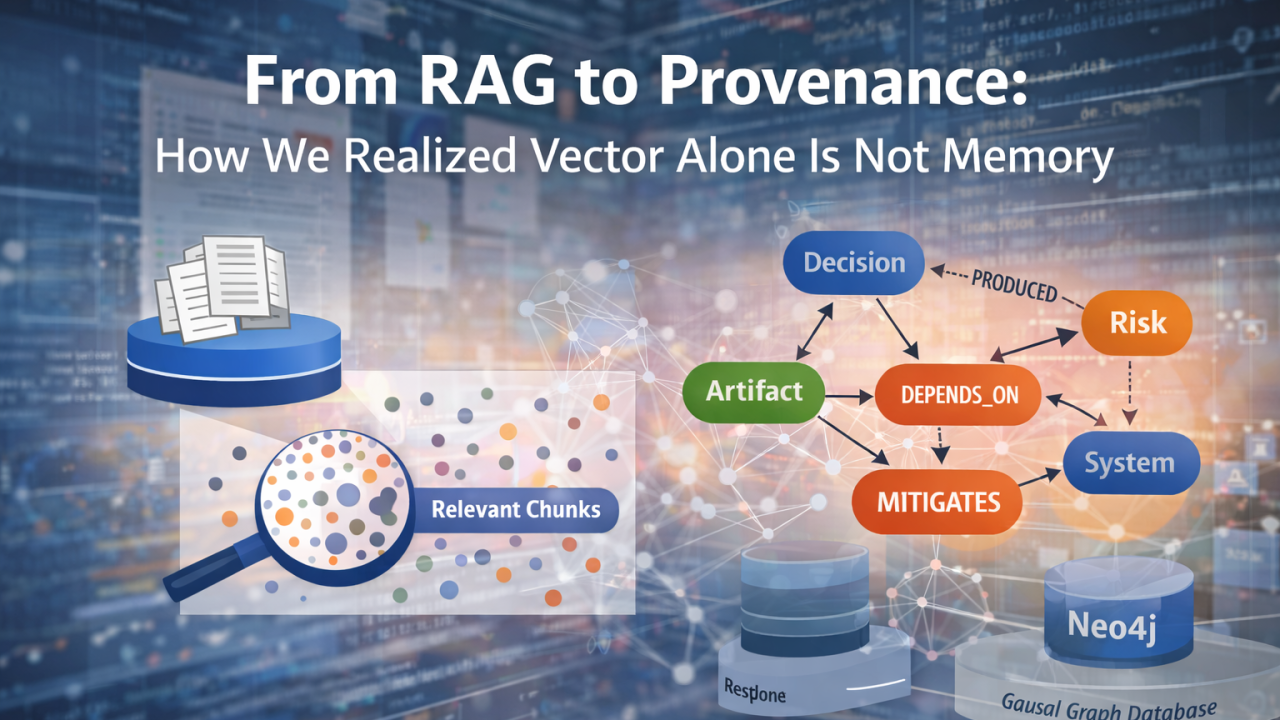
Nowoczesny odruch jest prosty. Bierzemy całą dostępną treść — notatki ze spotkań, tickety Jira, strony Confluence, dokumenty projektowe. Dzielimy je na chunki, zamieniamy na wektory, zapisujemy w pgvector, a następnie odzyskujemy istotne fragmenty przy użyciu podobieństwa semantycznego. Owijamy to LLM-em i nagle mamy coś, co wydaje się inteligentne.
To działa. To wydaje się wręcz magiczne. Odzyskuje kontekst szybciej niż jakikolwiek człowiek mógłby to zrobić.
Ale z czasem zaczyna brakować czegoś istotnego.
Bo wyszukiwanie wektorowe odpowiada tylko na jeden typ pytania: „Jaki tekst wygląda podobnie do mojego zapytania?”
Podobieństwo nie jest jednak pamięcią.
Gdy billing psuje się w marcu i ktoś pyta: „Dlaczego tak się stało?”, podobieństwo semantyczne może odnaleźć fragmenty wspominające billing i marzec. Ale nie powie ci, która decyzja zmieniła logikę billingową, czy ta decyzja zastąpiła wcześniejszą, która zależność systemowa została dotknięta albo które działanie mitigacyjne nigdy nie zostało wdrożone.
Wektory dają ci trafność. Nie dają ci przyczynowości.
A awarie delivery niemal zawsze mają charakter przyczynowy.
Moment, w którym zrozumieliśmy, że potrzebujemy grafu
Zmiana nastąpiła, gdy przeformułowaliśmy problem.
Zamiast pytać: „Jak odzyskiwać dokumenty?”, zapytaliśmy: „Jak zachować strukturę rozumowania?”
To pytanie zmienia wszystko.
Przestaliśmy myśleć w kategoriach akapitów, a zaczęliśmy myśleć w kategoriach encji.
- Spotkanie to nie tylko tekst. To zdarzenie, które produkuje decyzje.
- Decyzja to nie tylko zdanie. Ona wpływa na systemy.
- Ryzyko to nie tylko bullet point. To coś, co może, ale nie musi, zostać zmitigowane przez działania.
- Akcja to nie tylko zadanie. Ona modyfikuje stan systemu.
Nagle model pamięci przestał wyglądać jak magazyn dokumentów, a zaczął przypominać graf.
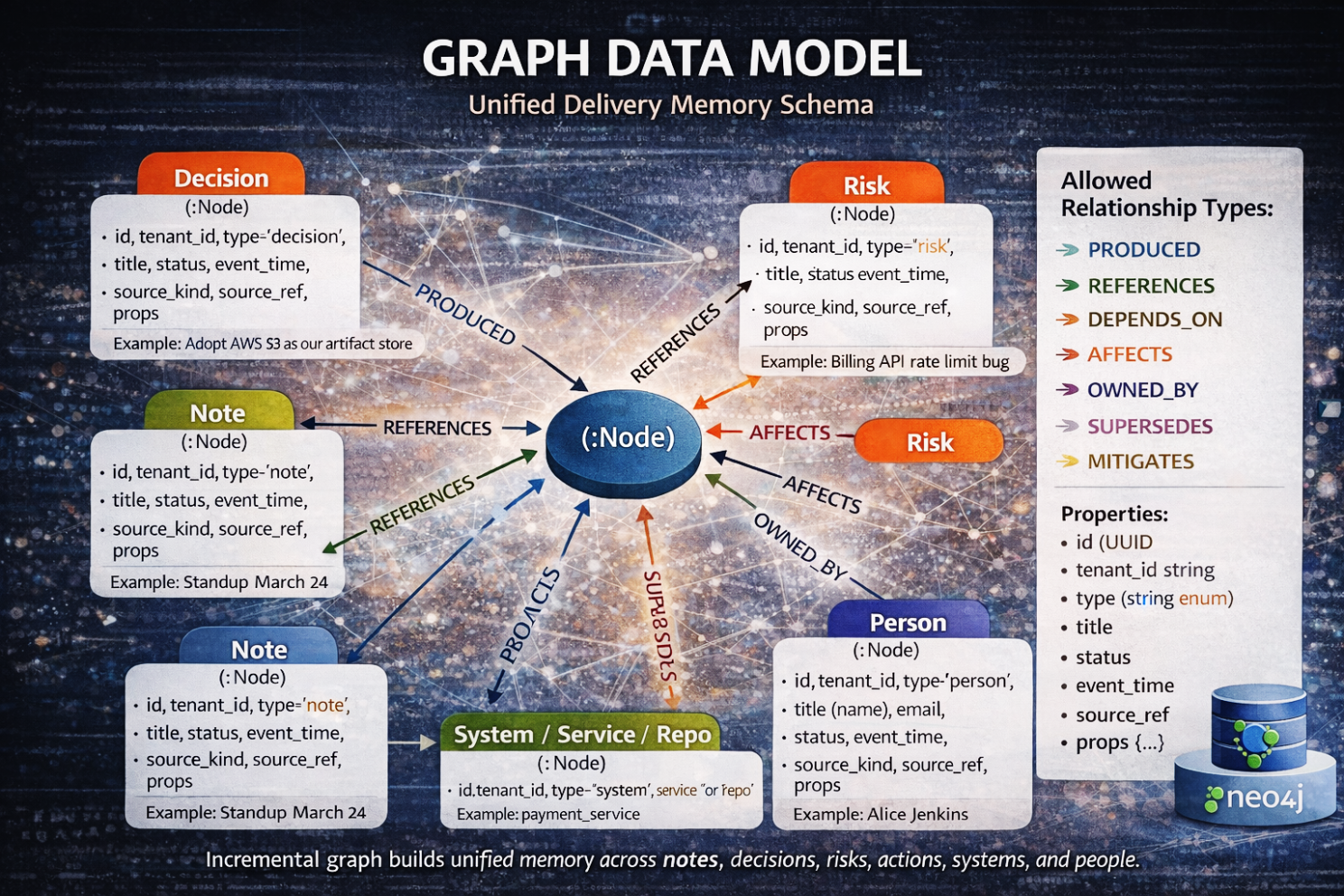
Wprowadziliśmy kanoniczne węzły — encje pierwszej klasy, które istnieją niezależnie od pojedynczego dokumentu. Notatki, decyzje, ryzyka, action items, artefakty, systemy, ludzie — każda z tych rzeczy stała się stabilnym obiektem z własną tożsamością. Są przechowywane w Postgresie jako dm_node, a nie jako osadzony tekst.
Następnie wprowadziliśmy krawędzie provenance — kierunkowe relacje, które przechwytują znaczenie.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
To nie są hiperłącza. To są stwierdzenia przyczynowe.
I w tym momencie wydarzyło się coś subtelnego, ale bardzo istotnego: pamięć przestała być tekstowa, a stała się strukturalna.

Dlaczego zarówno wektor, jak i graf mają znaczenie
Kuszące byłoby przeniesienie wszystkiego do bazy grafowej i ogłoszenie zwycięstwa. Ale to byłoby niepełne.
Nadal potrzebujemy wektorów.
Bo kiedy użytkownik zadaje pytanie, nie wiemy, od czego zacząć. Potrzebujemy semantycznego sygnału, który wskaże istotne regiony przestrzeni wiedzy. Właśnie to daje nam pgvector. Pomaga szybko i efektywnie znaleźć najbardziej relewantne chunki.
Ale gdy już znajdziemy te chunki, graf przejmuje kontrolę.
Od węzłów startowych zidentyfikowanych przez wyszukiwanie wektorowe rozwijamy graf provenance przy użyciu Neo4j. Przechodzimy po relacjach mówiących o tym, kto wytworzył tę decyzję, na co ona wpływa, co zastępuje, jakie ryzyko mitiguje i co od niej zależy. Nagle odpowiedź nie składa się już tylko z podobnych fragmentów tekstu, ale z odtworzonego przyczynowego sąsiedztwa.
Wektor daje nam punkt wejścia. Graf daje nam wyjaśnienie.
Razem tworzą coś znacznie bliższego pamięci organizacyjnej niż każda z tych technologii osobno.
Budowanie pamięci inkrementalnie, jak neuronalne wzmacnianie
Jedna z najważniejszych decyzji architektonicznych była następująca: graf musi być globalny, a nie przypisany do dokumentu.
Każda ingestia nie tworzy odizolowanej wyspy. Zamiast tego modyfikuje i wzmacnia współdzieloną pamięć.
Gdy nowa notatka odnosi się do istniejącego systemu, ponownie używamy tego samego węzła. Gdy dwa spotkania produkują tę samą decyzję ujętą nieco innymi słowami, normalizujemy ją i ponownie łączymy. Gdy action item mitiguje ryzyko, które było już wcześniej omawiane, nie tworzymy kolejnego ryzyka; wzmacniamy połączenie.
Z czasem graf staje się gęstszy. Krawędzie zyskują większą pewność. Powtarzające się odwołania zwiększają liczniki wsparcia. Delivery memory staje się bardziej spójna.
To nie jest machine learning w klasycznym sensie, ale strukturalnie przypomina wzmacnianie.
Im częściej coś jest wspominane, łączone lub realizowane, tym silniejsza staje się jego strukturalna obecność.
W ten sposób pamięć SDLC zaczyna przypominać mniej dokumentację, a bardziej poznanie.

Retrieval jako ustrukturyzowana rozmowa
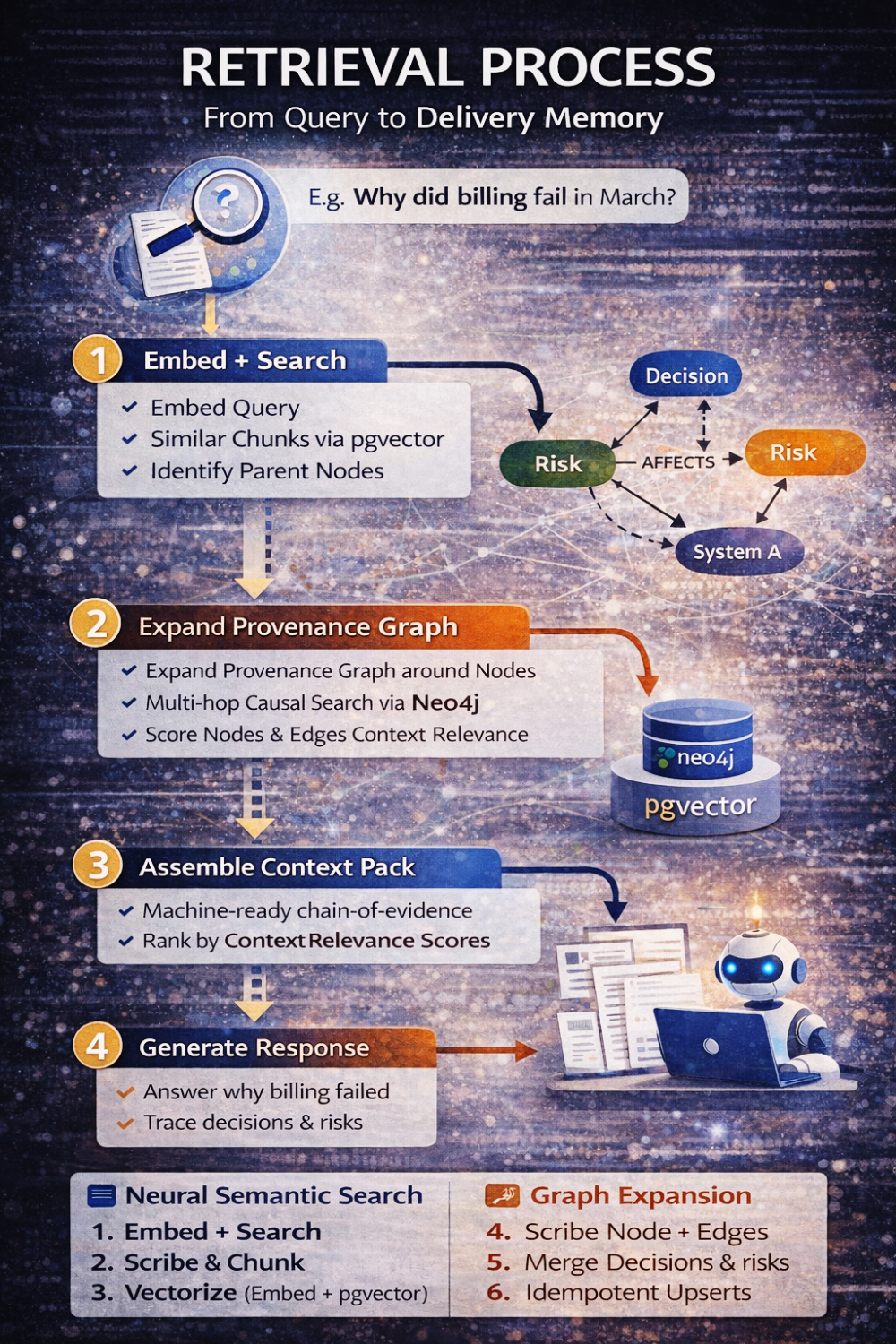
Gdy ktoś dziś pyta: „Dlaczego billing zepsuł się w marcu?”, system nie odzyskuje po prostu tekstu. Wykonuje ustrukturyzowaną rozmowę między dwoma modelami.
Najpierw embeduje zapytanie i odzyskuje semantycznie relewantne chunki. Następnie identyfikuje nadrzędne węzły tych chunków. Stamtąd rozwija graf provenance do zdefiniowanej głębokości, ograniczonej typami relacji i granicami tenantów. Składa pakiet kontekstowy, który zawiera nie tylko istotny tekst, ale też przyczynową strukturę wokół niego — decyzje, ryzyka, akcje, łańcuchy supersession. Dopiero wtedy do gry wchodzi LLM, i nawet wtedy jest ograniczony do rozumowania wyłącznie na podstawie tego złożonego zestawu dowodów.
Model nie wymyśla wyjaśnień.
On je rekonstruuje.
Powrót do tezy o pamięci SDLC
Wcześniej zadaliśmy strategiczne pytanie: jeśli AI zastępuje wykonanie, co pozostaje wartościowe?
Odpowiedzią były kontekst i przyczynowość.
Ten projekt vector-plus-graph operacjonalizuje tę tezę.
Magazyn wektorowy przechwytuje to, co zostało powiedziane. Struktura grafu przechwytuje, dlaczego to miało znaczenie. Ich połączenie zachowuje sposób, w jaki system ewoluował.
Bez wektora tracimy trafność. Bez grafu tracimy lineage.
Bez obu tracimy pamięć.
Głębszy wgląd
Większość zespołów zbuduje w tym roku pipeline’y RAG. Wiele z nich uwierzy, że ma „wiedzę wspieraną przez AI”.
Ale bardzo niewiele zbuduje Provenance.
Bo Provenance zmusza do zmierzenia się ze strukturą. Zmusza do jawnego modelowania decyzji, definiowania kierunkowości, obsługi supersession, egzekwowania tożsamości, unikania duplikacji i myślenia w kategoriach systemów przyczynowych, a nie dokumentów.
To jest bardziej wymagające niż samo embedowanie tekstu.
Ale właśnie dlatego staje się strategicznym wyróżnikiem.
W świecie, w którym AI potrafi pisać kod i tworzyć dokumentację, prawdziwa przewaga konkurencyjna będzie należeć do organizacji, które potrafią wyjaśnić własną ewolucję, prześledzić decyzje, uzasadnić trade-offy i ujawnić ukryte łańcuchy kształtujące rezultaty.
To nie jest problem prompt engineeringu.
To problem architektury pamięci.
A prawdziwa pamięć nigdy nie jest płaska. Zawsze jest ustrukturyzowana.