From RAG to Provenance (Part 2): Jak inkrementalna pamięć grafowa naprawdę się uczy
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
W poprzednim artykule opisałem moment, w którym zdaliśmy sobie sprawę, że sama wyszukiwarka wektorowa nie jest pamięcią.
Embeddingi świetnie nadają się do znajdowania podobnych tekstów. Ale podobieństwo to nie jest linia pochodzenia decyzji. Nie mówi nam:
- kto podjął jaką decyzję,
- na podstawie jakiego założenia,
- z kim ta decyzja była w konflikcie,
- i kiedy została zastąpiona inną.
Tym razem chcę pokazać, co dzieje się dalej.
Jak system faktycznie aktualizuje pamięć organizacyjną w sposób inkrementalny?
Nie w teorii. Nie na diagramach architektury.
Tylko krok po kroku — na prostym przykładzie z życia.
Step 0 — Wejście (gdzie zaczyna się pamięć)
Załóżmy, że taka notatka pojawia się po spotkaniu produktowym:
„Yauheni zdecydował o przesunięciu wydania instancji EU, ponieważ nowa interpretacja GDPR od zespołu prawnego wprowadza dodatkowe ryzyka zgodności. Action item: przygotować plan mitigacji z zespołem bezpieczeństwa. Anton zadał pytanie, czy możemy izolować dane per workspace zamiast per region.”
To jest tylko tekst.
Ale w tym jednym akapicie znajdują się:
- Decyzje
- Ryzyka
- Pytania
- Zadania (action items)
- Osoby
- Niejawne zależności
Cel biznesowy jest prosty:
Nie pozwól, aby to zniknęło w historii Slacka. Zamień to w uporządkowaną i możliwą do prześledzenia pamięć organizacyjną.
Zaangażowani aktorzy
- Product lead (autor źródła)
- Legal (niejawny autorytet)
- Zespół bezpieczeństwa
- System Provenance (AI + pamięć grafowa)
- Ludzki recenzent
Step 1 — Scribing: przekształcanie tekstu w strukturę znaczeń
Cel biznesowy: wyodrębnić jawne artefakty, aby mogły być zarządzane.
System odczytuje tekst i przekształca go w obiekty strukturalne.
Output (uproszczony przykład JSON):
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}To jeszcze nie jest pamięć. To interpretacja w trybie staging.
Na tym etapie nic nie jest jeszcze zapisane w głównym grafie.
Step 2 — Budowa małego grafu tymczasowego
Cel biznesowy: przedstawić logikę tej jednej notatki zanim zostanie połączona z globalną pamięcią.
Na podstawie wyodrębnionych artefaktów system buduje mały tymczasowy graf.
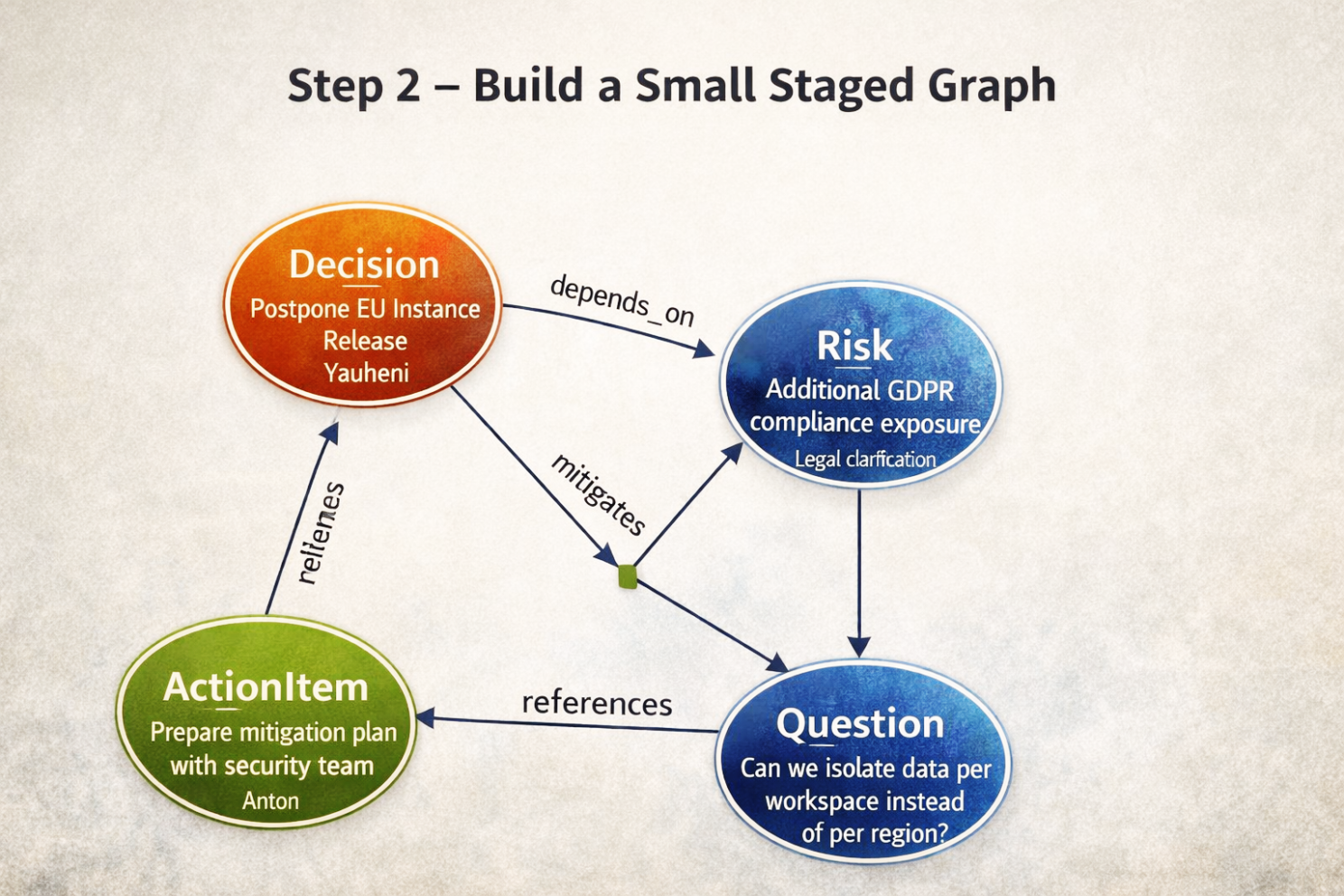
Powstała struktura logiczna:
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionTen graf istnieje tylko w obrębie bieżącej transakcji.
Nie jest jeszcze częścią trwałej pamięci organizacji.
Dlaczego?
Ponieważ jeszcze nie wiemy:
- czy to ryzyko już istnieje,
- czy decyzja jest kontynuacją wcześniejszej,
- czy ktoś o wyższym autorytecie wcześniej nie podjął innej decyzji.
Step 3 — Porównanie semantyczne (ale nie w ciemno)
Cel biznesowy: wykryć, czy te obiekty już istnieją w pamięci.
System sprawdza podobieństwo semantyczne w stosunku do istniejącej pamięci.
Załóżmy, że znajduje:

Teraz system staje przed pytaniem biznesowym:
- Czy to są te same rzeczy?
- Czy są tylko powiązane, ale jednak różne?
Same wektory nie potrafią na to odpowiedzieć.
Dlatego system pobiera kontekst z grafu:
- kto był właścicielem wcześniejszej decyzji,
- jaki był powód,
- czy była tymczasowa,
- czy została później zastąpiona.
Tutaj właśnie pamięć grafowa ma znaczenie.
Step 4 — Rozstrzyganie tożsamości (scalić czy utworzyć?)
Cel biznesowy: uniknąć duplikacji bez utraty niuansów.
System ocenia:
- wcześniejsze „Delay EU rollout (Q1)” wynikało z niestabilności infrastruktury,
- nowe opóźnienie wynika z ryzyka prawnego.
Inny powód. Inny zakres. Inny moment.
Decyzja:
- ✔ utworzyć nowy węzeł Decision
- ✔ połączyć go z istniejącym węzłem ryzyka GDPR
Jeśli ryzyko już istnieje, nie duplikujemy go.
Wzmacniamy je.
Pamięć staje się warstwowa, a nie fragmentaryczna.
Step 5 — Ocena i ważenie relacji
Cel biznesowy: określić siłę zależności.
Nie wszystkie zależności są takie same.
Przykład:
- Decision depends_on Risk → silne powiązanie przyczynowe
- Question references Decision → słabsze powiązanie kontekstowe
Każda krawędź otrzymuje:
- fragment dowodu
- poziom pewności
- referencję źródła
- identyfikator transakcji
Przykładowy zapis:
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Teraz system może odpowiedzieć:
- Dlaczego wydanie zostało przesunięte?
- Jakie ryzyka to uzasadniały?
- Jak silne było uzasadnienie decyzji?
Step 6 — Wykrywanie konfliktów (autorytet ma znaczenie)
Wyobraźmy sobie teraz coś istotnego.
Dwa miesiące wcześniej CTO formalnie zdecydował:
“EU instance must go live before Q2 to support enterprise pipeline.”
Wyższy autorytet. Przeciwny kierunek.
System wykrywa:
- ten sam zakres (instancja EU),
- sprzeczną decyzję,
- inny poziom właściciela.
Zgłasza:
⚠ Konflikt: istnieje decyzja wyższego autorytetu.
Na tym etapie system nie blokuje rzeczywistości.
Prosi o walidację człowieka.
To jest governance, nie automatyzacja.
Step 7 — Przegląd człowieka (warstwa zaufania)
Cel biznesowy: zachować odpowiedzialność.
Recenzent widzi zestaw zmian.
Tworzy:
- nową Decision
- nowe ActionItem
Scala:
- Risk → istniejące ryzyko GDPR
Relacje:
- Decision depends_on Risk
- ActionItem mitigates Risk
Konflikt:
- wcześniejsza dyrektywa CTO wymaga przeglądu
Recenzent może:
- zatwierdzić
- zmodyfikować
- eskalować
- jawnie zastąpić wcześniejszą decyzję
Jeśli zostanie zastąpiona:
Decision A → supersedes → Decision BBez usuwania. Bez przepisywania historii.
Tylko ewolucja.
Step 8 — Commit (atomowa aktualizacja pamięci)
Po zatwierdzeniu system zapisuje wszystko jako jedną transakcję.
Kanoniczny graf zawiera teraz:
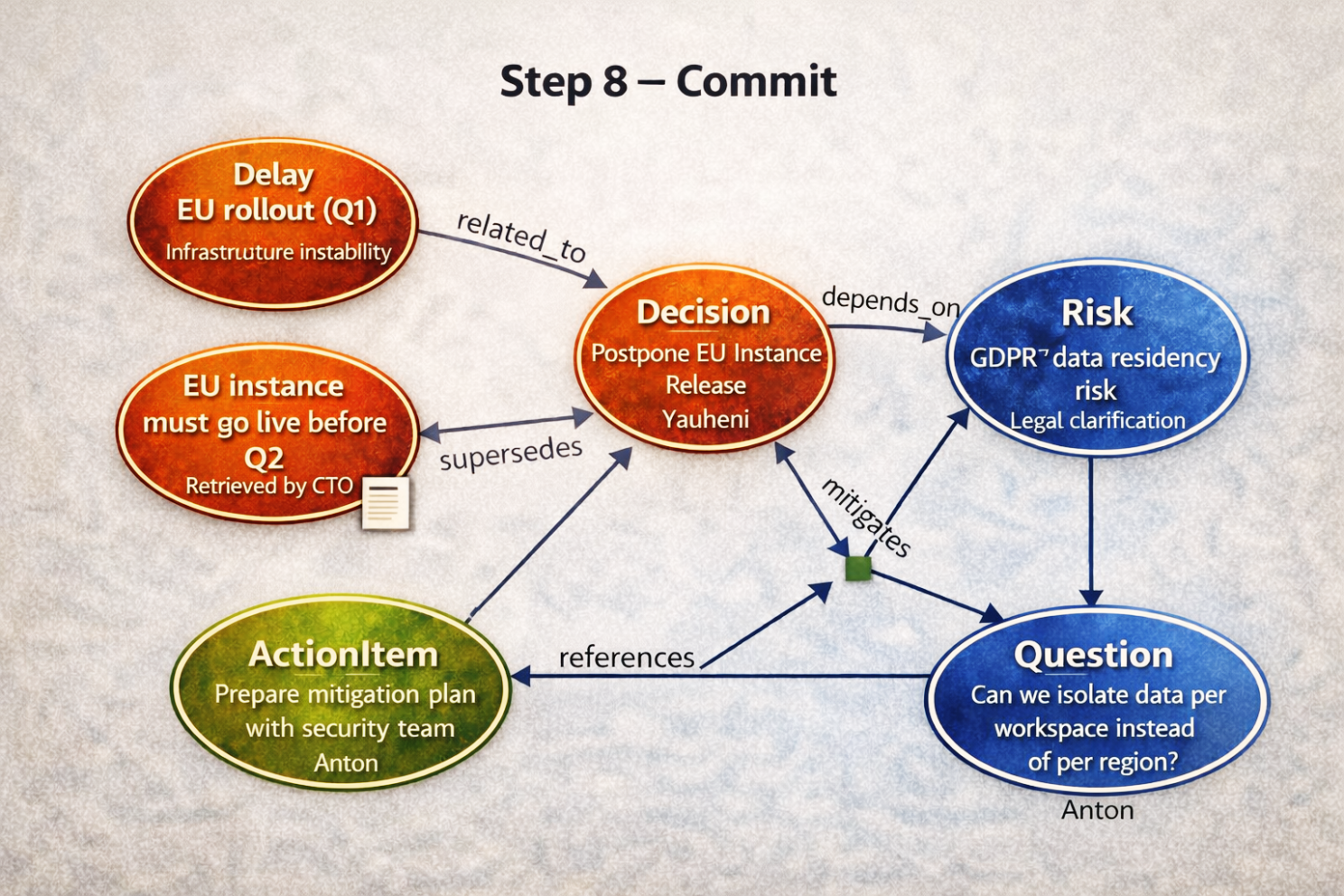
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / konflikty (jeśli występują)
Każdy element zapisuje:
- kto go wprowadził
- kiedy
- na podstawie jakiego tekstu
- powiązane wcześniejsze artefakty
- czy nadpisał wcześniejszą decyzję
To jest pamięć.
Dlaczego to ważne poza architekturą
Spójrzmy z dystansu.
W większości organizacji:
- decyzje są rozproszone
- uzasadnienia znikają
- odpowiedzialność się zmienia
- kontekst zanika
- ludzie dyskutują o historii zamiast rozwiązywać problem.
Dzięki inkrementalnym aktualizacjom provenance:
- każda notatka staje się elementem governance
- każda zależność staje się jawna
- każdy konflikt staje się widoczny
- każda zmiana jest możliwa do prześledzenia
To nie jest RAG.
To nie jest tylko podobieństwo wektorowe.
To jest akumulacja kapitału decyzyjnego.
Większa zmiana
Kiedy 50–80% pracy wykonują agenci AI zamiast inżynierów, staje się to jeszcze ważniejsze.
Agenci będą:
- generować plany
- proponować decyzje
- tworzyć action items
- refaktoryzować systemy
- zmieniać architekturę
Bez uporządkowanej pamięci: zwiększają entropię.
Z Provenance: działają w ramach governance.
Różnica nie polega na produktywności.
Różnica polega na przetrwaniu systemu.
Od retrieval do ewolucji
RAG odpowiada na pytania o przeszłość.
Provenance buduje przeszłość inkrementalnie.
Każde przetworzenie:
- wyodrębnia znaczenie
- rozwiązuje tożsamość
- weryfikuje autorytet
- zapisuje linię pochodzenia
- wzmacnia lub aktualizuje wcześniejszą pamięć
Z czasem graf staje się:
- historią decyzji
- mapą ryzyk
- rejestrem governance
- żywą pamięcią SDLC
I dzieje się to inkrementalnie.
Jedna notatka ze spotkania na raz.