От RAG к Provenance: как мы поняли, что одних векторов недостаточно для памяти
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
В предыдущих статьях мы исследовали неудобное наблюдение: у SDLC на самом деле нет памяти.
Не потому, что мы не пишем документацию. Не потому, что Jira пуста. Не потому, что заметки со встреч исчезают.
Мы теряем память, потому что теряем причинно-следственные связи.
Принимаются решения, обсуждаются риски, формируются допущения, назначаются action items, и всё же спустя месяцы, когда что-то ломается или происходит стратегический поворот, мы не можем восстановить цепочку рассуждений, которая привела нас в эту точку. Мы извлекаем фрагменты, но не можем проследить их происхождение.
Именно здесь в разговор вошла идея Provenance. Не как ещё одна практика документирования и не как AI-трюк, а как нечто более структурное — способ сохранить причинную ДНК delivery. Но как только мы говорим «нам нужна память», сразу возникает практический вопрос: «Какой модели данных требует настоящая память SDLC?»
И именно здесь большинство команд останавливаются слишком рано.
Соблазнительный комфорт векторной памяти
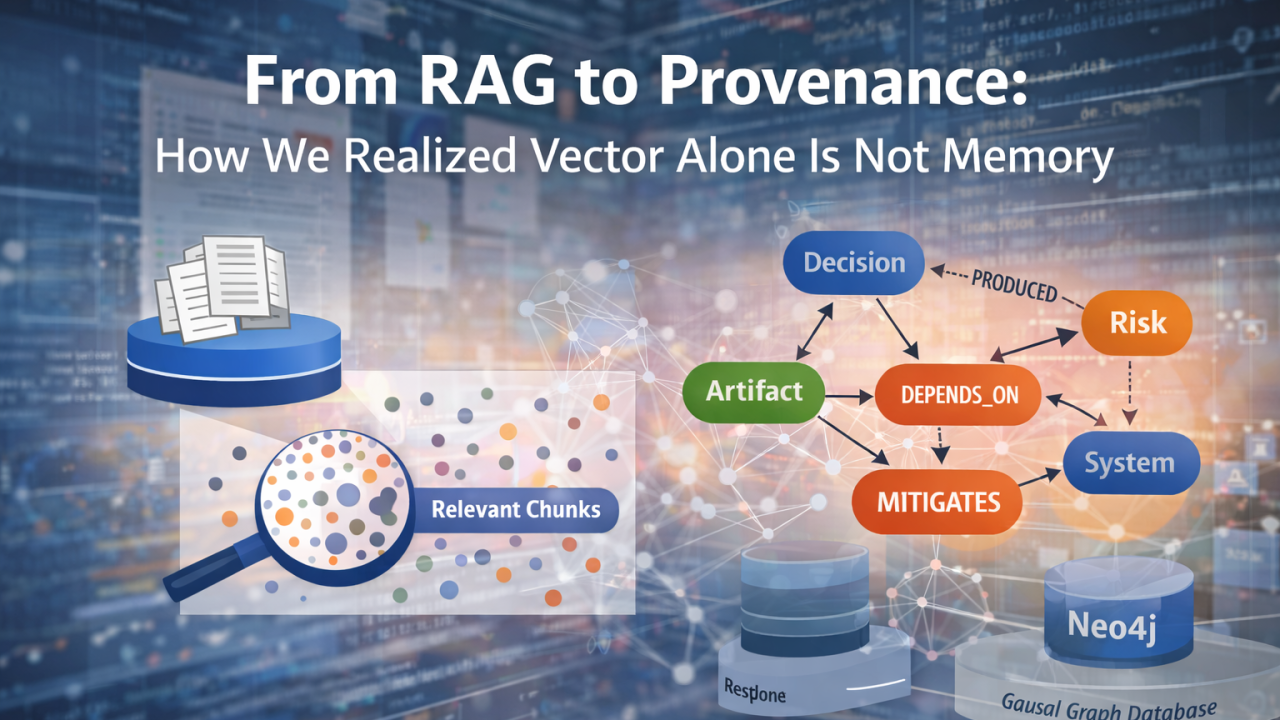
Современный инстинкт понятен. Мы берём весь доступный контент — заметки со встреч, тикеты Jira, страницы Confluence, дизайн-документы. Разбиваем их на chunks, превращаем в векторы, сохраняем в pgvector, а затем извлекаем релевантные фрагменты с помощью семантического сходства. Оборачиваем это в LLM — и внезапно получаем нечто, что кажется интеллектуальным.
Это работает. Это ощущается почти магически. Оно извлекает контекст быстрее, чем это смог бы сделать любой человек.
Но со временем начинает ощущаться некоторая неполнота.
Потому что векторный поиск отвечает только на один тип вопроса: «Какой текст похож на мой запрос?»
Однако сходство — это не память.
Когда в марте ломается billing и кто-то спрашивает: «Почему это произошло?», семантическое сходство может извлечь фрагменты, где упоминаются billing и март. Но оно не может сказать, какое решение изменило billing-логику, заменило ли это решение предыдущее, какая системная зависимость была затронута или какое смягчающее действие так и не было реализовано.
Векторы дают вам релевантность. Они не дают вам причинность.
А сбои delivery почти всегда имеют причинный характер.
Момент, когда мы поняли, что нам нужен граф
Сдвиг произошёл тогда, когда мы переосмыслили саму проблему.
Вместо вопроса «Как нам извлекать документы?» мы спросили: «Как нам сохранить структуру рассуждения?»
Этот вопрос меняет всё.
Мы перестали мыслить абзацами и начали мыслить сущностями.
- Встреча — это не просто текст. Это событие, которое производит решения.
- Решение — это не просто предложение. Оно влияет на системы.
- Риск — это не просто bullet point. Это нечто, что может быть или не быть смягчено действиями.
- Действие — это не просто задача. Оно изменяет состояние системы.
Внезапно модель памяти перестала быть похожей на хранилище документов и стала больше похожа на граф.
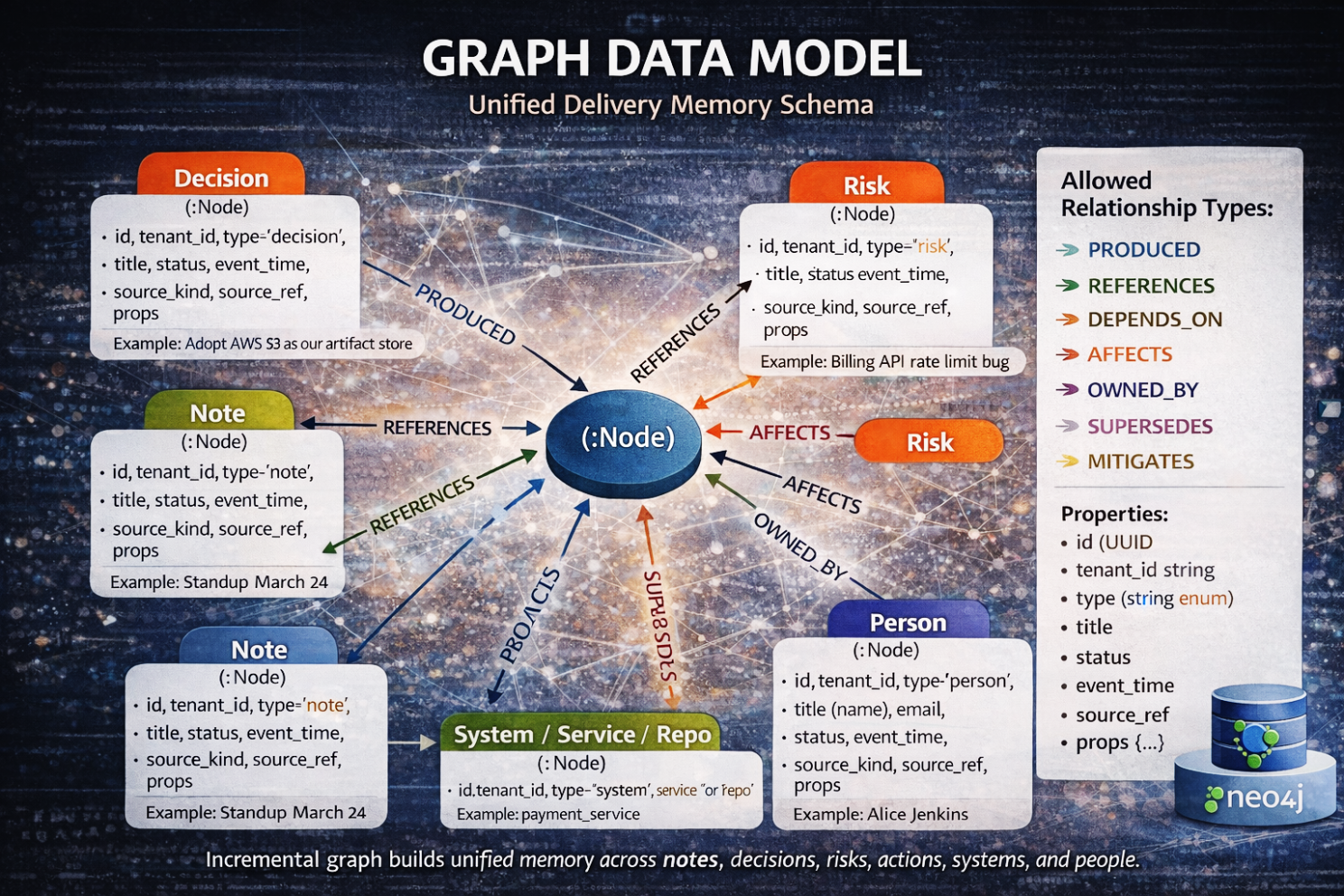
Мы ввели канонические узлы — сущности первого класса, которые существуют независимо от какого-либо отдельного документа. Заметки, решения, риски, action items, артефакты, системы, люди — каждая из этих сущностей стала стабильным объектом с собственной идентичностью. Они хранятся в Postgres как dm_node, а не как встроенный текст.
Затем мы ввели связи provenance — направленные отношения, которые фиксируют смысл.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
Это не гиперссылки. Это причинные утверждения.
И в этот момент произошло нечто тонкое, но мощное: память перестала быть текстовой и стала структурной.

Почему важны и вектор, и граф
Было бы заманчиво перенести всё в графовую базу данных и объявить победу. Но это было бы неполным решением.
Нам всё ещё нужны векторы.
Потому что, когда пользователь задаёт вопрос, мы не знаем, с чего начать. Нам нужен семантический сигнал, чтобы определить релевантные области пространства знаний. Именно это даёт нам pgvector. Он помогает быстро и эффективно находить наиболее релевантные chunks.
Но как только мы находим эти chunks, управление берёт на себя граф.
От начальных узлов, найденных через векторный поиск, мы расширяем граф provenance с помощью Neo4j. Мы проходим по отношениям, связанным с тем, кто произвёл это решение, на что оно влияет, что оно заменяет, какой риск смягчает и что от него зависит. И внезапно ответ состоит уже не просто из похожих текстовых фрагментов, а из реконструированного причинного окружения.
Вектор даёт нам точку входа. Граф даёт нам объяснение.
Вместе они образуют нечто гораздо более близкое к организационной памяти, чем любая из этих технологий по отдельности.
Построение памяти инкрементально, как нейронное усиление
Одним из важнейших архитектурных решений было следующее: граф должен быть глобальным, а не привязанным к отдельному документу.
Каждая ingestion не создаёт изолированный остров. Вместо этого она изменяет и усиливает общую память.
Когда новая заметка ссылается на существующую систему, мы переиспользуем этот узел. Когда две встречи производят одно и то же решение, но в немного разных формулировках, мы нормализуем их и связываем заново. Когда action item смягчает риск, который уже обсуждался ранее, мы не создаём ещё один риск; мы усиливаем уже существующую связь.
Со временем граф становится плотнее. Связи получают больше уверенности. Повторяющиеся ссылки увеличивают счётчики поддержки. Память delivery становится более согласованной.
Это не machine learning в классическом смысле, но структурно это напоминает усиление.
Чем чаще что-то упоминается, связывается или реализуется, тем сильнее становится его структурное присутствие.
Именно так память SDLC начинает ощущаться меньше как документация и больше как когниция.

Retrieval как структурированный разговор
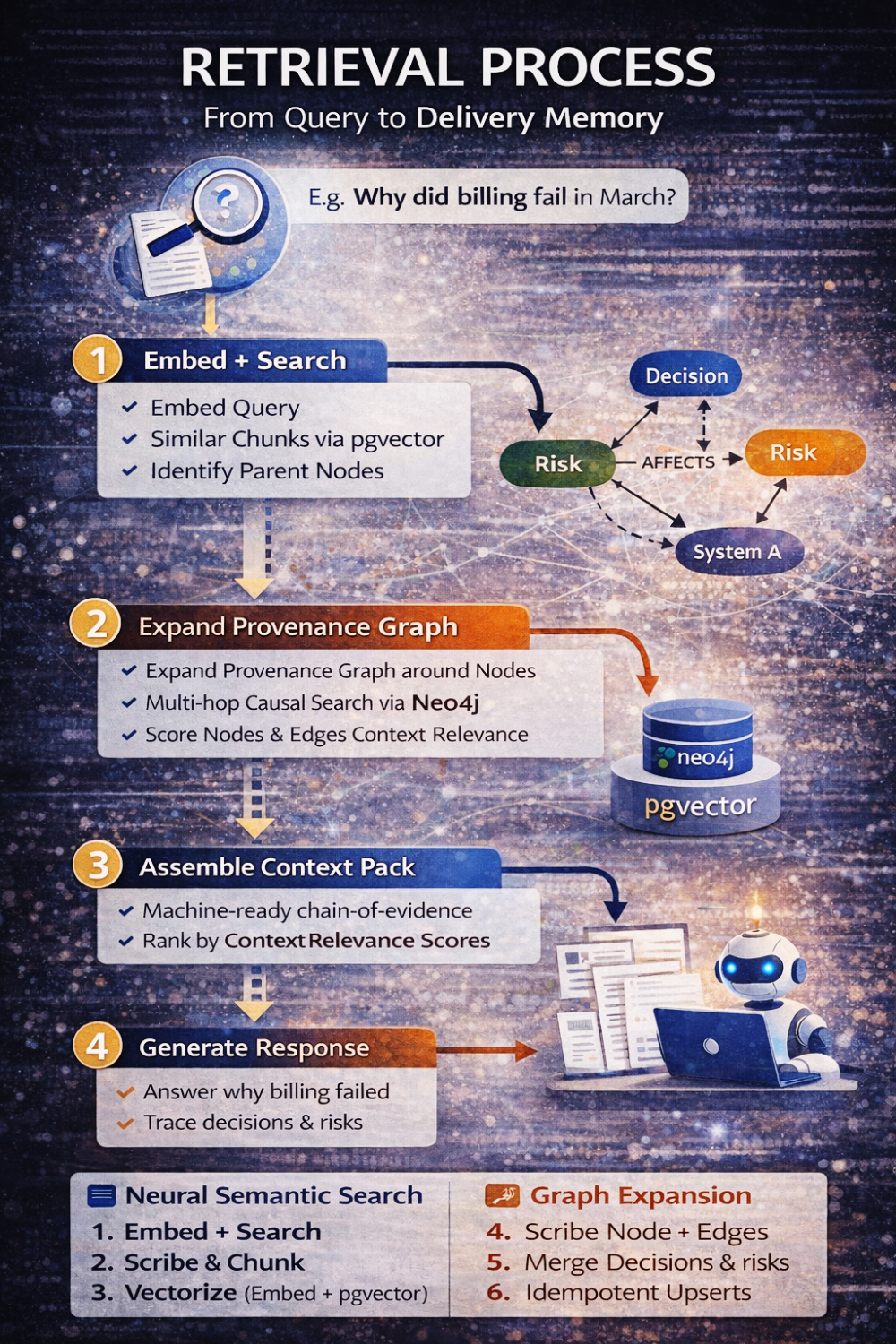
Когда теперь кто-то спрашивает: «Почему billing сломался в марте?», система не просто извлекает текст. Она выполняет структурированный разговор между двумя моделями.
Сначала она векторизует запрос и извлекает семантически релевантные chunks. Затем определяет родительские узлы этих chunks. Оттуда она расширяет граф provenance до заданной глубины, ограниченной типами связей и границами tenant. Она собирает context pack, который включает не только релевантный текст, но и причинную структуру вокруг него — решения, риски, действия, цепочки supersession. Только после этого в работу вступает LLM, и даже тогда он ограничен рассуждением исключительно на основе этого собранного набора доказательств.
Модель не выдумывает объяснения.
Она реконструирует их.
Возвращаясь к тезису о памяти SDLC
Ранее мы задавали стратегический вопрос: если AI заменяет исполнение, что остаётся ценным?
Ответом были контекст и причинность.
Этот дизайн vector-plus-graph переводит этот тезис в практическую плоскость.
Векторное хранилище фиксирует, что было сказано. Графовая структура фиксирует, почему это было важно. Их сочетание сохраняет то, как система эволюционировала.
Без вектора мы теряем релевантность. Без графа мы теряем lineage.
Без обоих мы теряем память.
Более глубокое понимание
Большинство команд в этом году построят RAG pipelines. Многие будут считать, что у них есть «AI-powered knowledge». Но очень немногие построят Provenance.
Потому что Provenance заставляет вас столкнуться со структурой. Она заставляет явно моделировать решения, определять направленность, обрабатывать supersession, обеспечивать идентичность, избегать дублирования и мыслить в терминах причинных систем, а не документов.
Это сложнее, чем просто embedить текст.
Но именно поэтому это становится стратегическим дифференциатором.
В мире, где AI может писать код и создавать документацию, реальное конкурентное преимущество будет принадлежать организациям, которые способны объяснить собственную эволюцию, проследить решения, обосновать trade-offs и выявить скрытые цепочки, формирующие результаты.
Это не проблема prompt engineering.
Это проблема архитектуры памяти.
И настоящая память никогда не бывает плоской. Она всегда структурирована.