From RAG к Provenance (Часть 2): Как на самом деле обучается инкрементальная графовая память
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
В предыдущей статье я описал момент, когда мы поняли, что одного лишь векторного поиска недостаточно, чтобы считать систему памятью.
Эмбеддинги отлично находят похожий текст. Но похожесть — это не происхождение. Она не говорит:
- кто принял какое решение,
- на каком предположении оно было основано,
- с кем это решение конфликтовало,
- и когда оно было заменено другим.
На этот раз я хочу показать, что происходит дальше.
Как система на практике инкрементально обновляет организационную память?
Не в теории. Не на архитектурных диаграммах.
А шаг за шагом — на простом примере из реальной жизни.
Step 0 — Входные данные (где начинается память)
Представим, что после продуктового синка появляется такая заметка:
«Yauheni решил отложить выпуск EU‑инстанса, потому что новое разъяснение GDPR от юридической команды вводит дополнительные риски комплаенса. Action item: подготовить план снижения рисков вместе с командой безопасности. Anton задал вопрос, можем ли мы изолировать данные по workspace, а не по региону.»
Это просто текст.
Но внутри этого абзаца есть:
- Решения
- Риски
- Вопросы
- Action items
- Люди
- Неявные зависимости
Бизнес‑цель проста:
Не позволить этому исчезнуть в истории Slack. Преобразовать это в структурированную и отслеживаемую организационную память.
Участники процесса
- Product lead (автор исходной заметки)
- Legal (неявный источник авторитета)
- Команда безопасности
- Система Provenance (AI + графовая память)
- Человек‑ревьюер
Step 1 — Scribing: преобразование текста в структурированный смысл
Бизнес‑цель: извлечь явные артефакты, чтобы ими можно было управлять.
Система читает текст и преобразует его в структурированные объекты.
Output (упрощённый пример JSON):
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}Это ещё не память. Это интерпретация в staging‑режиме.
На этом этапе ничего ещё не фиксируется в основном графе.
Step 2 — Построение небольшого временного графа
Бизнес‑цель: представить логику внутри этой одной заметки до того, как она будет объединена с глобальной памятью.
На основе извлечённых артефактов система строит небольшой временный граф.
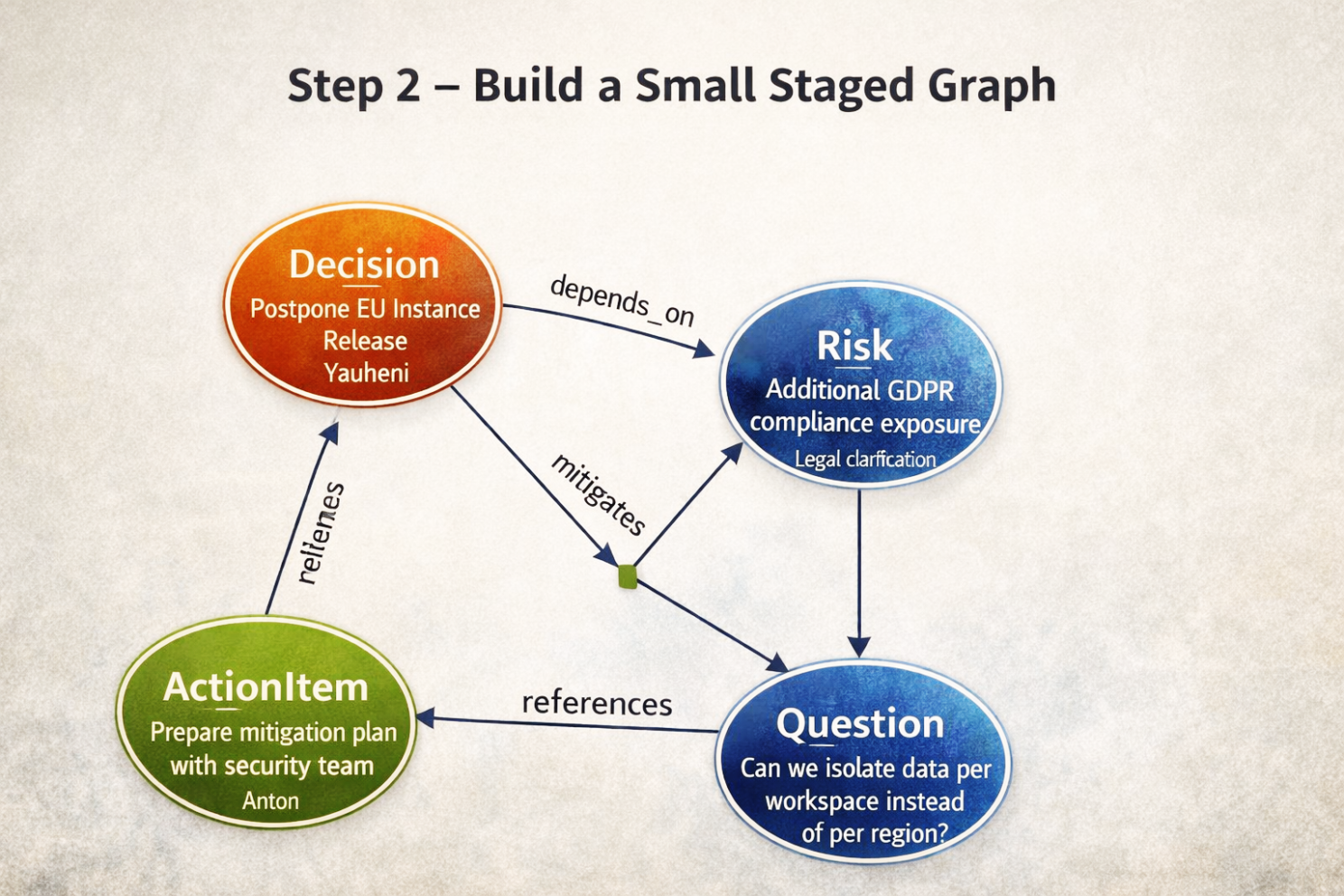
Созданная логическая структура:
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionЭтот граф существует только внутри текущей транзакции.
Он ещё не является частью постоянной памяти компании.
Почему?
Потому что мы пока не знаем:
- существует ли уже этот риск,
- является ли решение продолжением более раннего,
- принимал ли кто‑то с более высоким уровнем авторитета другое решение.
Step 3 — Семантическое сравнение (но не вслепую)
Бизнес‑цель: определить, существуют ли уже эти объекты в памяти.
Система проверяет семантическое сходство с существующей памятью.
Предположим, она находит:

Теперь система сталкивается с бизнес‑вопросом:
- Это те же самые сущности?
- Или они связаны, но всё же различаются?
Одни лишь векторы не могут ответить на этот вопрос.
Поэтому система извлекает контекст из графа:
- кто владел предыдущим решением,
- какова была причина,
- было ли оно временным,
- было ли оно заменено.
Именно здесь важна графовая память.
Step 4 — Разрешение идентичности (объединить или создать?)
Бизнес‑цель: избежать дублирования, не потеряв нюансы.
Система оценивает:
- старое решение «Delay EU rollout (Q1)» было вызвано нестабильностью инфраструктуры,
- новое отложение связано с юридическим риском.
Другая причина. Другой контекст. Другое время.
Решение:
- ✔ создать новый узел Decision
- ✔ связать его с существующим узлом риска GDPR
Если риск уже существует, мы его не дублируем.
Мы усиливаем его.
Память становится многослойной, а не фрагментированной.
Step 5 — Оценка и взвешивание связей
Бизнес‑цель: количественно определить силу отношений.
Не все зависимости одинаковы.
Пример:
- Decision depends_on Risk → сильная причинная связь
- Question references Decision → более слабая контекстная связь
Каждое ребро получает:
- фрагмент доказательства
- уровень уверенности
- ссылку на источник
- идентификатор транзакции
Пример записи ребра:
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Теперь система может ответить:
- Почему релиз был отложен?
- Какие риски это оправдывали?
- Насколько сильным было обоснование?
Step 6 — Обнаружение конфликтов (авторитет имеет значение)
Представим теперь важную ситуацию.
Два месяца назад CTO официально решил:
«EU instance must go live before Q2 to support enterprise pipeline.»
Более высокий авторитет. Противоположное направление.
Система обнаруживает:
- тот же контекст (EU instance),
- противоположное решение,
- разный уровень владельца решения.
Она сообщает:
⚠ Конфликт: существует решение более высокого уровня.
На этом этапе система не блокирует реальность.
Она запрашивает человеческую проверку.
Это governance, а не автоматизация.
Step 7 — Человеческая проверка (уровень доверия)
Бизнес‑цель: сохранить ответственность.
Ревьюер видит набор изменений.
Создаёт:
- новое Decision
- новый ActionItem
Объединяет:
- Risk → существующий риск GDPR
Связи:
- Decision depends_on Risk
- ActionItem mitigates Risk
Конфликт:
- предыдущая директива CTO требует проверки
Ревьюер может:
- одобрить
- изменить
- эскалировать
- явно заменить предыдущее решение
Если решение заменено:
Decision A → supersedes → Decision BНикаких удалений. Никакого переписывания истории.
Только эволюция.
Step 8 — Commit (атомарное обновление памяти)
После одобрения система фиксирует всё одной транзакцией.
Теперь канонический граф содержит:
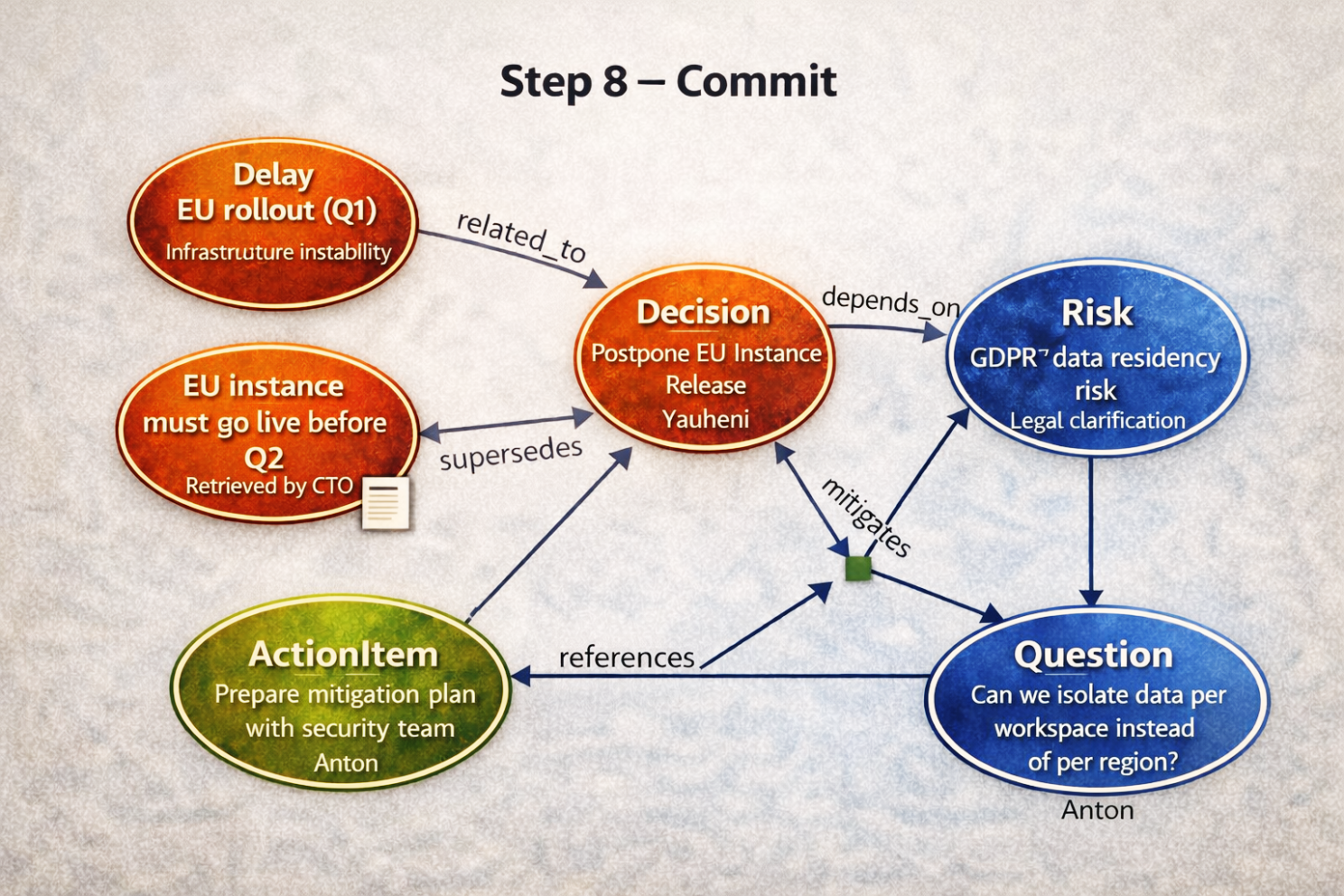
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / конфликты (если применимо)
Каждый элемент записывает:
- кто его добавил
- когда
- на основе какого текста
- связанные предыдущие артефакты
- было ли что‑то переопределено
Это и есть память.