Praxisleitfaden für Agentic Flow
Author: Yauheni Kurbayeu
Published: Mar 22, 2026
TL;DR
Im vorherigen Artikel, Aufbau einer automatisierten Übersetzungspipeline für einen Markdown-Blog mit GitHub-Copilot-Agents, haben wir eine GitHub-Copilot-basierte Übersetzungspipeline entworfen, die auf einem Orchestrator, sprachspezifischen Subagents, wiederverwendbaren Skills und Hooks basiert.
Dieses Design wurde anschließend anhand der realen Repository-Implementierung im Bewertungsbericht Wie der aktuelle GitHub-Copilot-Artikelübersetzungsfluss in diesem Repository funktioniert bewertet. Dort wird gezeigt, was das aktuelle Setup heute tatsächlich leistet und wie die Verantwortlichkeiten wirklich auf Repository-Anweisungen, Agents, Skills und Hooks verteilt sind.
In diesem Artikel gehen wir einen Schritt weiter und machen aus diesen Ideen einen praktischen Leitfaden. Wir zeigen, wie dieses Workspace agentische Vererbung modelliert, wie Anweisungsschichtung die native Vererbung ersetzt und wie die drei Ausführungsansätze funktionieren:
- sequenziell
- parallel
- hierarchisch
Ziel ist es, Ihnen ein wiederverwendbares Entwurfsmuster für GitHub-Copilot-Agent-Flows mit gemeinsamen Anweisungen, spezialisierten Workern und klaren Koordinationsregeln an die Hand zu geben.
Hooks sind hier bewusst nicht Teil des Umfangs. Sie können später ergänzt werden, um Validierung, Beobachtbarkeit und Sicherheit rund um den Flow zu verbessern.
Was dieses Workspace bereits demonstriert
Das aktuelle Workspace verwendet eine vererbungsähnliche Struktur, die aus geschichteten Anweisungen statt aus echter Klassenvererbung aufgebaut ist.
Zentrale Bausteine
- .github/copilot-instructions.md definiert die globalen Regeln für alle Agents.
- .github/skills/shared-agent-contract/SKILL.md definiert die gemeinsame Aufgabenhülle und den Rückgabevertrag.
- .github/skills/agents-orchestration/SKILL.md definiert, wie ein Parent-Agent Arbeit delegiert.
- .github/skills/worker/SKILL.md definiert das Standardverhalten für Worker-Agents.
- .github/agents/main-orchestrator.agent.md fungiert als Root-Koordinator.
- .github/agents/worker1.agent.md, .github/agents/worker2.agent.md und .github/agents/worker3.agent.md fungieren als spezialisierte Worker.
Zusammenfassung der aktuellen Überprüfung
- Das Vererbungsmodell ist klar und wiederverwendbar.
- Der sequenzielle Modus ist als orchestratorgesteuerte Verkettung modelliert.
- Der parallele Modus ist als orchestratorgesteuertes Fan-out und Fan-in modelliert.
- Der hierarchische Modus ist als Worker-zu-Worker-Delegation modelliert.
- Der hierarchische Modus verändert die Rolle von
worker1undworker2: In diesem Modus sind sie keine reinen Leaf-Worker mehr, obwohl der gemeinsame Worker-Skill Worker standardmäßig als Leaf-Knoten beschreibt.
Dieser letzte Punkt ist nicht zwangsläufig falsch, aber er ist eine wichtige Designentscheidung. Wenn Sie hierarchische Ausführung verwenden, werden einige Worker zu zwischengeschalteten Koordinatoren.
Agentische Vererbung
Die Kernidee
GitHub-Copilot-Agents besitzen keine native Vererbung. Der praktische Ersatz ist die Komposition von Anweisungen:
- Globale Anweisungen fungieren als Basisklasse.
- Gemeinsame Skills fungieren als wiederverwendbare Rollenschichten.
- Agent-Dateien fungieren als schlanke Spezialisierungen.
- Laufzeit-Aufgabendaten vervollständigen das Verhalten.
Dieses Muster bietet Ihnen die meisten Vorteile von Vererbung:
- ein gemeinsamer Vertrag
- weniger duplizierte Prompt-Logik
- klarere Verantwortungsgrenzen
- einfachere Wartung, wenn der Flow wächst
Vorrang von Anweisungen
Das aktuelle Workspace folgt dieser Reihenfolge:
- .github/copilot-instructions.md
- gemeinsame Skills, auf die ein Agent verweist
- agentspezifische Anweisungen in der Datei
.agent.md - Laufzeit-Aufgabenhülle vom Benutzer oder Parent-Agent
Das bedeutet, dass ein Child-Agent die gemeinsamen Regeln spezialisieren, ihnen aber nicht widersprechen sollte.
Vererbungsübersicht für dieses Workspace
Global base
.github/copilot-instructions.md
Shared contract
.github/skills/shared-agent-contract/SKILL.md
Role-specific behavior
.github/skills/agents-orchestration/SKILL.md
.github/skills/worker/SKILL.md
Agent specializations
.github/agents/main-orchestrator.agent.md
.github/agents/worker1.agent.md
.github/agents/worker2.agent.md
.github/agents/worker3.agent.mdGemeinsamer Vertrag
Der gemeinsame Agent-Vertrag ist die wichtigste Vererbungsschicht, weil er Folgendes standardisiert:
- die Aufgabenhülle
- die erwarteten Eingabefelder
- das Ausgabeschema
- die Fehlerbehandlung
In diesem Workspace enthält die gemeinsame Aufgabenhülle:
task_idobjectivemodeinput_artifactconstraintsexpected_outputparent_agent
Der gemeinsame Rückgabevertrag enthält:
statusagentsummaryresultnotes
Genau das ermöglicht es mehreren Agents, zusammenzuarbeiten, ohne jedes Mal ein neues Mini-Protokoll erfinden zu müssen.
Ausführungsmodi
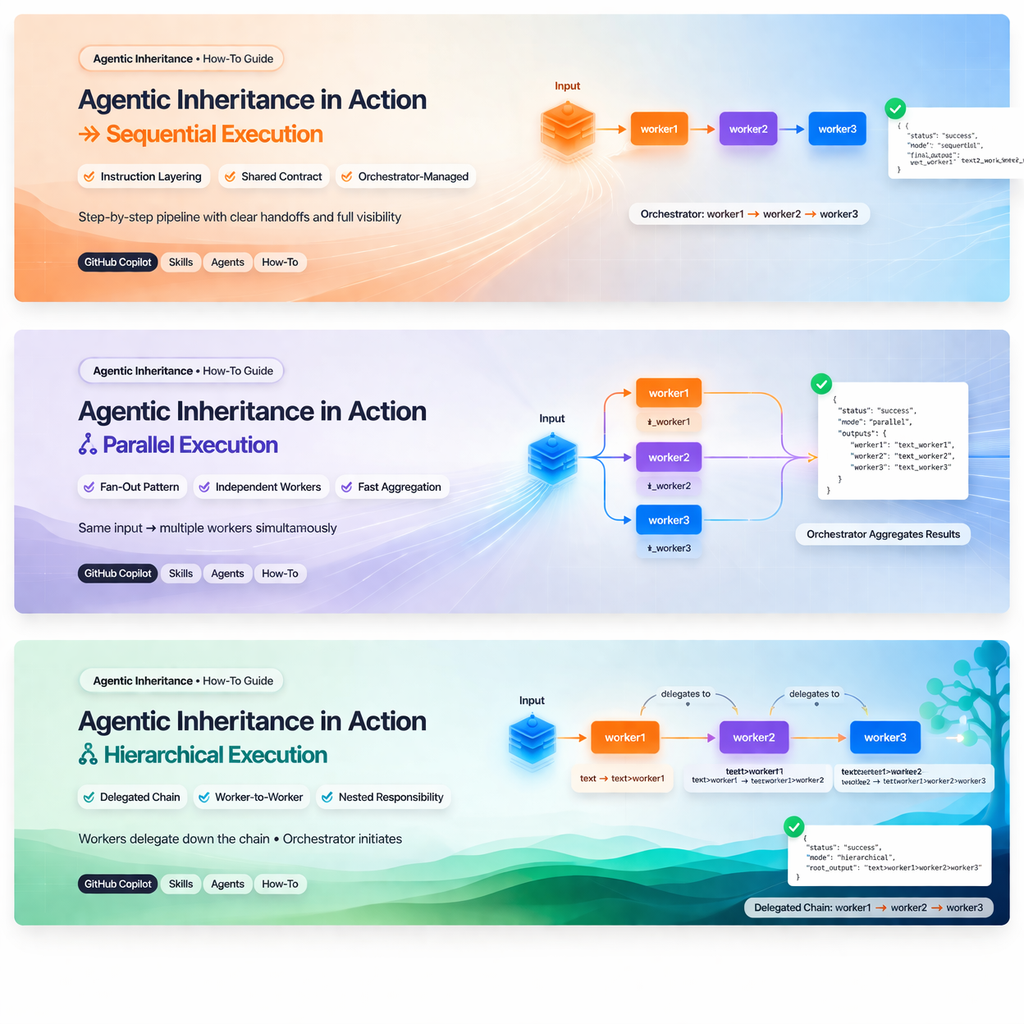
1. Sequenzieller Modus
Was er bedeutet
Der sequenzielle Modus ist eine Schritt-für-Schritt-Pipeline, die vom Orchestrator gesteuert wird.
Der Orchestrator bleibt für jede Übergabe verantwortlich:
main-orchestrator -> worker1 -> main-orchestrator -> worker2 -> main-orchestrator -> worker3Wann er eingesetzt werden sollte
- wenn jeder Schritt vom vorherigen Ergebnis abhängt
- wenn Sie zentrale Kontrolle und Sichtbarkeit möchten
- wenn ein Fehler den Flow sofort stoppen soll
Vorteile
- der am einfachsten nachvollziehbare Modus
- stärkste Kontrolle durch den Orchestrator
- unkompliziertes Logging und Wiederholungsversuche
Abwägungen
- langsamer als der parallele Modus
- der Orchestrator liegt zwischen jedem Schritt auf dem kritischen Pfad
Beispiel
status: success
agent: main-orchestrator
summary: Ran workers 1→2→3 sequentially on the input text and returned the final transformed output.
result:
mode: sequential
steps:
- worker: worker1
input: "text to transform"
output: "text to transform_worker1"
- worker: worker2
input: "text to transform_worker1"
output: "text to transform_worker1_worker2"
- worker: worker3
input: "text to transform_worker1_worker2"
output: "text to transform_worker1_worker2_worker3"
final_output: "text to transform_worker1_worker2_worker3"
notes: Each worker appended its marker in turn, with the orchestrator coordinating the handoffs and preserving the step history.Wie man ihn implementiert
- Der Orchestrator erhält die ursprüngliche Eingabe.
- Der Orchestrator sendet die Eingabe an
worker1. worker1gibt ein strukturiertes Ergebnis zurück.- Der Orchestrator nimmt
worker1.resultund sendet es anworker2. - Der Orchestrator nimmt
worker2.resultund sendet es anworker3. - Der Orchestrator gibt die endgültige Worker-Ausgabe zusammen mit dem Schrittverlauf zurück.
2. Paralleler Modus
Was er bedeutet
Der parallele Modus ist ein Fan-out-Muster, bei dem der Orchestrator dieselbe Eingabe gleichzeitig an mehrere Worker sendet.
main-orchestrator -> worker1
main-orchestrator -> worker2
main-orchestrator -> worker3Der Orchestrator aggregiert anschließend die Ergebnisse.
Wann er eingesetzt werden sollte
- wenn Worker unabhängig voneinander sind
- wenn Sie Ausgaben vergleichen möchten
- wenn Geschwindigkeit wichtiger ist als Abhängigkeiten zwischen den Schritten
Vorteile
- schnellere Ausführung, wenn Aufgaben unabhängig sind
- gut für Experimente und Vergleiche
- einfaches Aggregationsmodell
Abwägungen
- Worker können nicht aufeinander aufbauen
- Ergebnisse benötigen eventuell Nachbearbeitung, bevor sie direkt vergleichbar sind
Beispiel
status: success
agent: main-orchestrator
summary: Ran three workers in parallel on the same input text and collected their outputs.
result:
mode: parallel
outputs:
worker1: "text Parallel_worker1"
worker2: "text Parallel_worker2"
worker3: "text Parallel_worker3"
notes: Each worker independently appended its own marker to the shared input, with the orchestrator coordinating the aggregation of results.Wie man ihn implementiert
- Der Orchestrator erhält die ursprüngliche Eingabe.
- Der Orchestrator sendet dasselbe
input_artifactan alle Worker. - Jeder Worker gibt unabhängig sein eigenes strukturiertes Ergebnis zurück.
- Der Orchestrator kombiniert die Ausgaben zu einem nach Workern indizierten Ergebnisobjekt.
3. Hierarchischer Modus
Was er bedeutet
Der hierarchische Modus ist eine delegierte Kette, bei der der Orchestrator den Flow startet, Worker die Kontrolle aber entlang der Kette weitergeben:
main-orchestrator -> worker1 -> worker2 -> worker3Dies unterscheidet sich vom sequenziellen Modus, weil der Orchestrator nicht der Übergabepunkt zwischen jeder Phase ist.
Wann er eingesetzt werden sollte
- wenn ein Teilfluss den Workern selbst gehören soll
- wenn Sie verschachtelte Verantwortung möchten
- wenn spätere Worker konzeptionell Children früherer Worker sind
Vorteile
- unterstützt baumartige oder verschachtelte Delegationsmuster
- kann Orchestrierungsrauschen reduzieren
- modelliert Parent-Child-Verarbeitungsketten auf natürliche Weise
Abwägungen
- schwerer nachzuvollziehen als orchestratorgesteuerter sequenzieller Modus
- Worker-Agents sind keine reinen Leaf-Knoten mehr
- Fehlerbehandlung und Beobachtbarkeit werden komplexer
Wichtiger Designhinweis
In diesem Workspace wird der hierarchische Modus dadurch implementiert, dass Worker an andere Worker delegieren dürfen.
Das bedeutet:
worker1wird zum Parent vonworker2worker2wird zum Parent vonworker3- nur
worker3bleibt im hierarchischen Pfad ein echter Leaf-Knoten
Das ist der wichtigste konzeptionelle Unterschied zum Standard-Worker-Skill, der Worker als Leaf-Agents beschreibt, sofern nicht ausdrücklich etwas anderes konfiguriert ist.
Beispiel
status: success
agent: main-orchestrator
summary: Ran workers hierarchically (worker1 → worker2 → worker3) on the input textTree and collected each stage’s output.
result:
mode: hierarchical
hierarchy:
worker1:
input: "textTree"
output: "textTree>worker1"
worker2:
parent: "worker1"
input: "textTree>worker1"
output: "textTree>worker1>worker2"
worker3:
parent: "worker2"
input: "textTree>worker1>worker2"
output: "textTree>worker1>worker2>worker3"
root_output: "textTree>worker1>worker2>worker3"
notes: Hierarchical mode mirrors a delegated chain (each worker builds on its parent’s output); the orchestrator initiates the flow but does not manage each handoff, allowing workers to take ownership of the subflow and pass results directly to their child workers.Wie man ihn implementiert
- Der Orchestrator startet den Flow, indem er
worker1aufruft. worker1transformiert die Eingabe und leitet das Ergebnis anworker2weiter.worker2transformiert die Eingabe und leitet das Ergebnis anworker3weiter.worker3gibt die terminale Ausgabe zurück.- Der Flow gibt das endgültige Ergebnis zusammen mit der Stage-Lineage zurück.
Sequenziell vs. Parallel vs. Hierarchisch
| Ansatz | Kontrollpunkt | Abhängigkeitsmodell | Am besten geeignet für |
|---|---|---|---|
| Sequenziell | Orchestrator zwischen jedem Schritt | Starke Schrittabhängigkeit | Pipelines mit zentralisierter Kontrolle |
| Parallel | Orchestrator verteilt und aggregiert | Unabhängige Worker | Geschwindigkeit, Vergleiche, Multi-Variant-Ausgaben |
| Hierarchisch | Worker delegieren entlang der Kette | Verschachtelte Parent-Child-Abhängigkeit | Baumartige Teilflüsse und delegierte Verantwortung |
Wie man einen ähnlichen agentischen Flow entwirft
Schritt 1. Den Basisvertrag einmal definieren
Legen Sie gemeinsame Regeln in .github/copilot-instructions.md ab und halten Sie sie generisch:
- Aufgabenhülle
- Ergebnisschema
- Fehlerschema
- Delegationsgrenzen
Schritt 2. Wiederverwendbares Verhalten in Skills verschieben
Verwenden Sie einen gemeinsamen Vertragsskill und erstellen Sie dann rollenspezifische Skills wie zum Beispiel:
- Orchestrierung
- Worker-Ausführung
- Validierung
- domänenspezifische Transformation
So vermeiden Sie es, dieselbe Prompt-Logik in jeden Agent zu kopieren.
Schritt 3. Agent-Dateien schlank halten
Jede Agent-Datei sollte nur diese Fragen beantworten:
- wofür dieser Agent verantwortlich ist
- welche Skills er verwendet
- welche Child-Agents er aufrufen darf
- wodurch er sich von benachbarten Agents unterscheidet
Wenn eine Regel für viele Agents gilt, sollte sie in der Regel nach oben in einen gemeinsamen Skill oder in eine globale Anweisung verschoben werden.
Schritt 4. Den richtigen Ausführungsmodus wählen
Verwenden Sie:
- sequenziell für orchestratorgesteuerte Pipelines
- parallel für unabhängige Zweige
- hierarchisch für delegierte Teilbäume oder verschachtelte Ketten
Wählen Sie den hierarchischen Modus nicht nur deshalb, weil er fortgeschrittener aussieht. Er sollte eingesetzt werden, wenn eine von Workern getragene Delegation tatsächlich das bessere Modell ist.
Schritt 5. Ausgaben nachvollziehbar halten
Geben Sie immer genügend Struktur zurück, damit der Parent verstehen kann:
- wer ausgeführt hat
- welche Eingabe empfangen wurde
- welche Ausgabe erzeugt wurde
- ob der Schritt erfolgreich war
Die Beispielausgaben in diesem Workspace sind ein gutes Muster, weil sie sowohl das Endergebnis als auch den Weg dorthin erhalten.
Empfohlene Verbesserungen
- Entscheiden Sie, ob Worker standardmäßig wirklich Leaf-Agents sein sollen oder ob hierarchische Delegation eine erstklassige Anforderung ist.
- Wenn der hierarchische Modus erstklassig ist, aktualisieren Sie die Sprache im Worker-Skill, damit interne Knoten-Worker expliziter beschrieben werden.
- Halten Sie den gemeinsamen Vertrag stabil, damit alle Ausführungsmodi kompatible Ergebnisstrukturen zurückgeben.
- Ziehen Sie später semantische Worker-Namen wie
normalize,transformundfinalizein Betracht, sobald das Muster stabil ist.
Zentrale Erkenntnis
Der sauberste Weg, agentische Vererbung in GitHub Copilot aufzubauen, besteht darin, Vererbung als geschichtete Prompt-Architektur zu behandeln:
- Basisanweisungen für universelle Richtlinien
- gemeinsame Skills für wiederverwendbares Verhalten
- schlanke Agents für Spezialisierung
- explizite Ausführungsmodi zur Flow-Steuerung
Diese drei Ausführungsmodi sind allesamt wertvolle Werkzeuge in Ihrem Design-Werkzeugkasten:
- sequenziell ist die klarste, vom Orchestrator geführte Pipeline
- parallel ist das klarste Fan-out-Modell
- hierarchisch ist am leistungsfähigsten, aber auch strukturell am meinungsstärksten
Wenn Sie agentischen Flow in ein neues Team einführen, beginnen Sie mit sequenziell, fügen Sie parallel hinzu, wenn Aufgaben unabhängig sind, und führen Sie hierarchisch nur dann ein, wenn Sie wirklich von Workern getragene Delegationsketten benötigen.
Nützliche GitHub-Copilot-Spezifikationen und Dokumentation
- Über das Anpassen von GitHub-Copilot-Antworten - Überblick über repositoryweite Anweisungen, pfadspezifische Anweisungen und verwandte Anpassungsmechanismen.
- Hinzufügen benutzerdefinierter Repository-Anweisungen für GitHub Copilot - Praktischer Leitfaden zum Erstellen von
.github/copilot-instructions.mdund.github/instructions/*.instructions.md. - Unterstützung für verschiedene Arten benutzerdefinierter Anweisungen - Referenzmatrix dafür, wo repositoryweite, pfadspezifische, persönliche und organisationsweite Anweisungen unterstützt werden.
- Über benutzerdefinierte Agents - Konzeptioneller Überblick darüber, was benutzerdefinierte Agents sind, wo sie liegen und wie sie in Copilot-Workflows passen.
- Erstellen benutzerdefinierter Agents für den Copilot Coding Agent - Schritt-für-Schritt-Anleitung zum Erstellen von Profilen unter
.github/agents/*.agent.md. - Konfiguration benutzerdefinierter Agents - Referenzdokumentation für Agent-Frontmatter, Tools, Modelleinstellungen und Aufrufverhalten.
- Über Agent-Skills - Erklärt, was Skills sind und wie sie Anweisungen und benutzerdefinierte Agents ergänzen.
- Erstellen von Agent-Skills für GitHub Copilot - Praktischer Leitfaden zur Strukturierung von
.github/skills/<skill>/SKILL.mdund verwandten Ressourcen. - Über Hooks - Konzeptionelle Erklärung von Hook-Triggern, Lebenszyklusereignissen und Governance-Anwendungsfällen.
- Verwendung von Hooks mit GitHub-Copilot-Agents - Implementierungsleitfaden für
.github/hooks/hooks.jsonund shellbasierte Hook-Aktionen. - Hook-Konfiguration - Referenz für die Struktur des Hook-Manifests, Ereignisse und Konfigurationsdetails.
- Copilot-Anpassungs-Spickzettel - Kompakte Referenz, die Anweisungen, Agents, Skills, Hooks und andere Anpassungsoptionen nebeneinander vergleicht.