Von RAG zu Provenance: Wie wir erkannt haben, dass Vektoren allein kein Gedächtnis sind
Author: Yauheni Kurbayeu
Published: Feb 22, 2026
LinkedIn
In den vorherigen Artikeln haben wir eine unangenehme Beobachtung untersucht: Der SDLC hat eigentlich kein echtes Gedächtnis.
Nicht weil wir keine Dokumentation schreiben. Nicht weil Jira leer ist. Nicht weil Meeting-Notizen verschwinden.
Wir verlieren Gedächtnis, weil wir Kausalität verlieren.
Entscheidungen werden getroffen, Risiken diskutiert, Annahmen gebildet, Aufgaben zugewiesen – und doch können wir Monate später, wenn etwas kaputtgeht oder ein strategischer Pivot passiert, die Gedankenkette, die uns dorthin geführt hat, nicht mehr rekonstruieren. Wir finden Fragmente, aber wir können die Herkunftslinie nicht nachverfolgen.
An dieser Stelle kam die Idee der Provenance ins Gespräch. Nicht als eine weitere Dokumentationspraxis und auch nicht als ein KI-Trick, sondern als etwas Strukturelleres — ein Weg, die kausale DNA der Delivery zu bewahren.
Doch sobald wir sagen „wir brauchen Gedächtnis“, folgt sofort eine praktische Frage: „Welches Datenmodell braucht echtes SDLC-Gedächtnis?“
Und genau hier hören die meisten Teams zu früh auf.
Der verführerische Komfort von Vektor-Gedächtnis
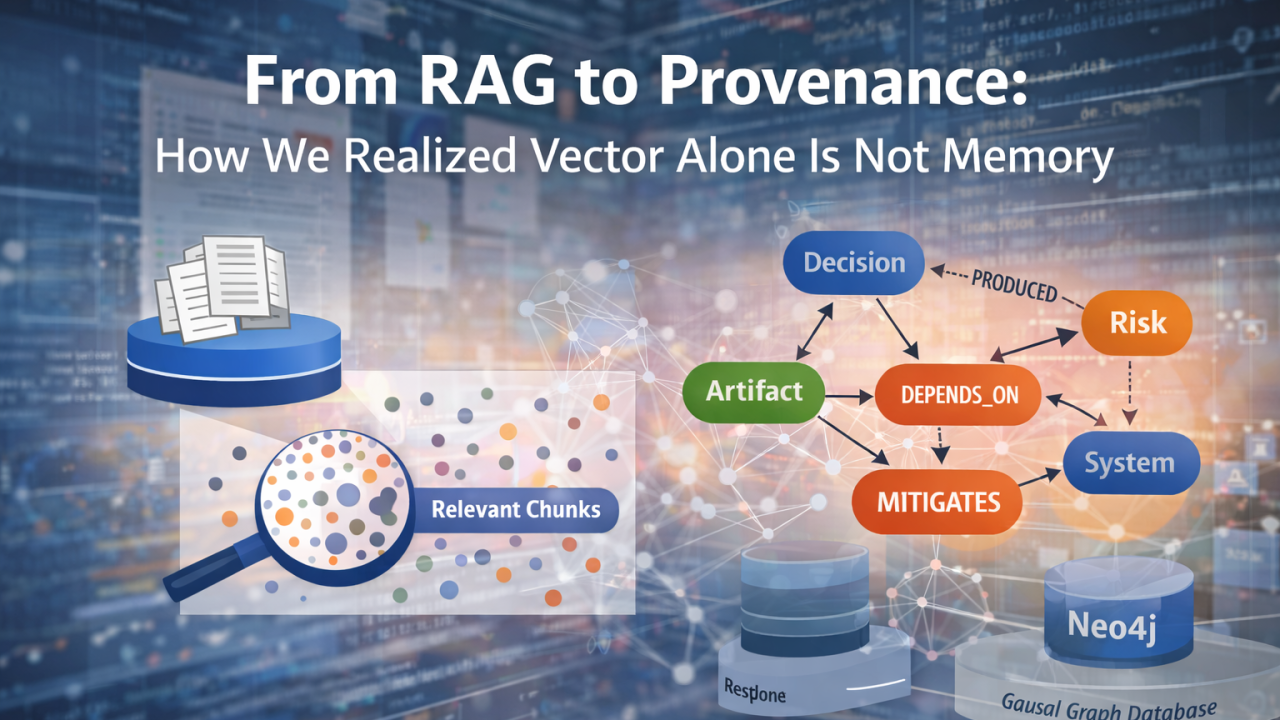
Der moderne Instinkt ist klar. Wir nehmen alle verfügbaren Inhalte — Meeting-Notizen, Jira-Tickets, Confluence-Seiten, Design-Dokumente. Wir teilen sie in Chunks auf, wandeln sie in Vektoren um, speichern sie in pgvector und rufen relevante Fragmente über semantische Ähnlichkeit ab. Wir kombinieren das Ganze mit einem LLM und plötzlich haben wir etwas, das intelligent wirkt.
Es funktioniert. Es fühlt sich fast magisch an. Es findet Kontext schneller als jeder Mensch.
Aber mit der Zeit fühlt sich etwas unvollständig an.
Denn Vektorsuche beantwortet nur eine Art von Frage:
„Welcher Text sieht meiner Anfrage ähnlich?“
Ähnlichkeit ist jedoch kein Gedächtnis.
Wenn im März das Billing-System ausfällt und jemand fragt: „Warum ist das passiert?“, kann semantische Ähnlichkeit Fragmente über Billing und März finden. Aber sie kann nicht sagen, welche Entscheidung die Billing-Logik geändert hat, ob diese Entscheidung eine frühere ersetzt hat, welche Systemabhängigkeit betroffen war oder welche Risikominderung nie umgesetzt wurde.
Vektoren liefern Relevanz. Sie liefern keine Kausalität.
Und Delivery-Fehler sind fast immer kausal.
Der Moment, in dem wir merkten, dass wir einen Graphen brauchen
Der Wendepunkt kam, als wir das Problem neu formulierten.
Statt zu fragen: „Wie finden wir Dokumente wieder?“, fragten wir: „Wie bewahren wir die Struktur des Denkens?“
Diese Frage verändert alles.
Wir hörten auf, in Absätzen zu denken, und begannen, in Entitäten zu denken.
- Ein Meeting ist nicht nur Text. Es ist ein Ereignis, das Entscheidungen hervorbringt.
- Eine Entscheidung ist nicht nur ein Satz. Sie beeinflusst Systeme.
- Ein Risiko ist kein Stichpunkt. Es ist etwas, das möglicherweise durch Maßnahmen gemindert wird — oder auch nicht.
- Eine Aktion ist nicht nur eine Aufgabe. Sie verändert den Zustand des Systems.
Plötzlich sah das Gedächtnismodell nicht mehr wie ein Dokumentenspeicher aus, sondern wie ein Graph.
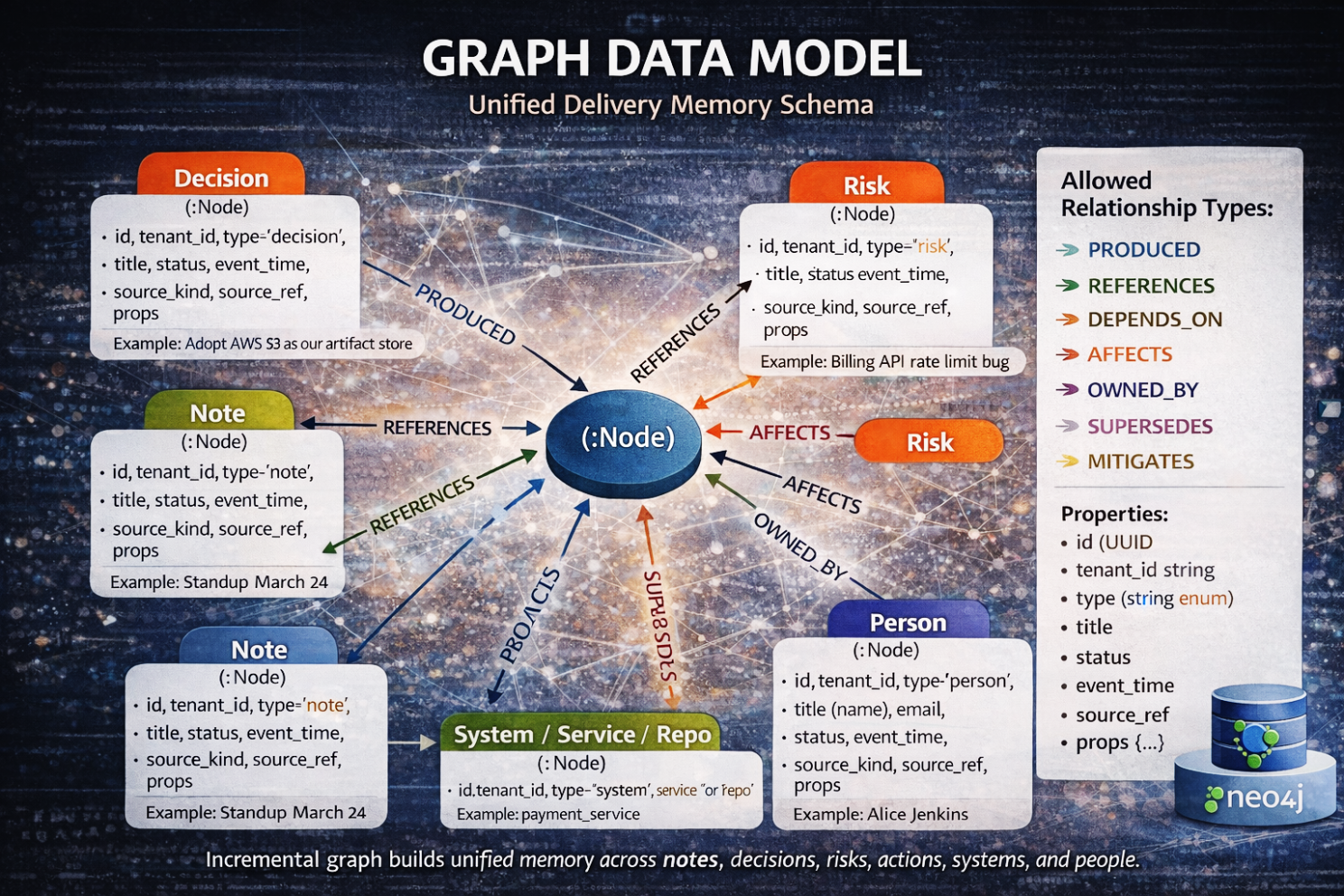
Wir führten kanonische Knoten ein — erstklassige Entitäten, die unabhängig von einem einzelnen Dokument existieren. Notizen, Entscheidungen, Risiken, Action Items, Artefakte, Systeme, Menschen — jede wurde zu einem stabilen Objekt mit eigener Identität. Sie werden in Postgres als dm_node gespeichert, nicht als eingebetteter Text.
Dann führten wir Provenance-Kanten ein — gerichtete Beziehungen, die Bedeutung erfassen.
- Produced
- References
- Depends_on
- Affects
- Mitigates
- Supersedes
Das sind keine Hyperlinks. Es sind kausale Aussagen.
Und an diesem Punkt geschah etwas Subtiles, aber Mächtiges: Gedächtnis hörte auf, textuell zu sein, und wurde strukturell.

Warum sowohl Vektoren als auch Graphen wichtig sind
Es wäre verlockend, alles in eine Graphdatenbank zu verschieben und den Sieg zu erklären. Aber das wäre unvollständig.
Wir brauchen weiterhin Vektoren.
Denn wenn ein Nutzer eine Frage stellt, wissen wir nicht, wo wir beginnen sollen. Wir brauchen ein semantisches Signal, um relevante Bereiche des Wissensraums zu identifizieren. Genau das liefert pgvector. Es hilft uns, schnell und effizient die relevantesten Chunks zu finden.
Doch sobald wir diese Chunks gefunden haben, übernimmt der Graph.
Von den Startknoten, die durch die Vektorsuche identifiziert wurden, erweitern wir den Provenance-Graphen über Neo4j. Wir durchlaufen Beziehungen darüber, wer diese Entscheidung getroffen hat, was sie beeinflusst, was sie ersetzt, welches Risiko sie mindert und wovon sie abhängt. Plötzlich besteht die Antwort nicht nur aus ähnlichen Textfragmenten, sondern aus einer rekonstruierten kausalen Umgebung.
Der Vektor gibt uns den Einstiegspunkt. Der Graph liefert die Erklärung.
Zusammen bilden sie etwas, das dem organisatorischen Gedächtnis viel näherkommt als jede der beiden Technologien allein.
Gedächtnis inkrementell aufbauen, wie neuronale Verstärkung
Eine der wichtigsten Architekturentscheidungen war diese: Der Graph muss global sein, nicht dokumentbasiert.
Jede Ingestion erzeugt keine isolierte Insel. Stattdessen verändert und verstärkt sie ein gemeinsames Gedächtnis.
Wenn eine neue Notiz auf ein bestehendes System verweist, verwenden wir diesen Knoten wieder. Wenn zwei Meetings dieselbe Entscheidung in leicht unterschiedlichen Worten erzeugen, normalisieren wir sie und verbinden sie erneut. Wenn ein Action Item ein Risiko mindert, das bereits zuvor diskutiert wurde, erzeugen wir kein neues Risiko — wir verstärken die Verbindung.
Mit der Zeit wird der Graph dichter. Kanten gewinnen an Vertrauen. Wiederholte Referenzen erhöhen Support-Zähler. Das Delivery-Gedächtnis wird kohärenter.
Es ist kein maschinelles Lernen im klassischen Sinn, aber strukturell ähnelt es Verstärkung.
Je häufiger etwas erwähnt, verknüpft oder umgesetzt wird, desto stärker wird seine strukturelle Präsenz.
So beginnt sich SDLC-Gedächtnis weniger wie Dokumentation und mehr wie Kognition anzufühlen.

Retrieval als strukturierte Konversation
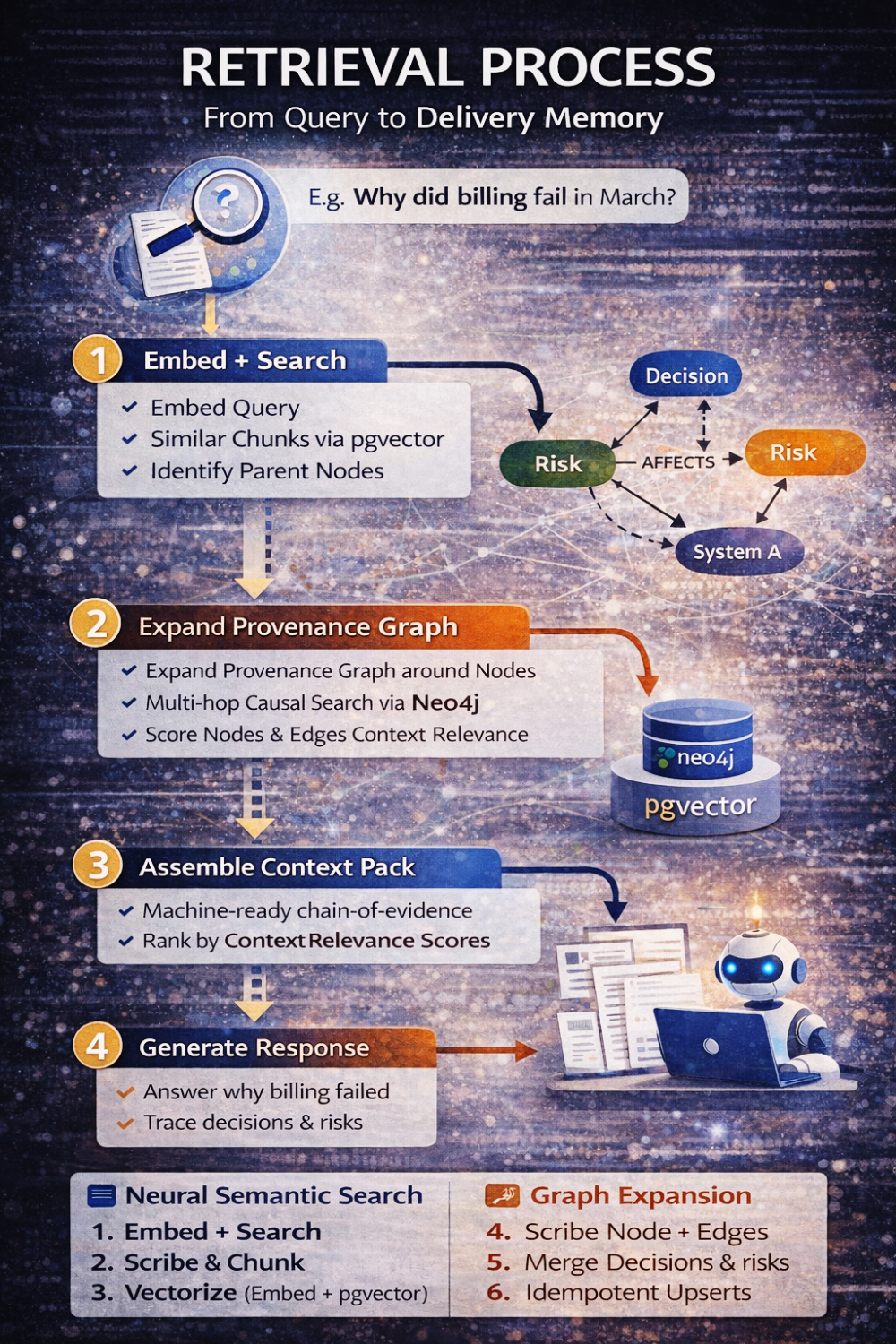
Wenn heute jemand fragt: „Warum ist Billing im März ausgefallen?“, ruft das System nicht einfach Text ab. Es führt eine strukturierte Konversation zwischen zwei Modellen.
Zuerst wird die Anfrage eingebettet und semantisch relevante Chunks werden abgerufen. Danach identifiziert das System die übergeordneten Knoten dieser Chunks. Von dort erweitert es den Provenance-Graphen bis zu einer definierten Tiefe, begrenzt durch Beziehungstypen und Tenant-Grenzen.
Es erstellt ein Kontextpaket, das nicht nur relevanten Text enthält, sondern auch die kausale Struktur darum herum — Entscheidungen, Risiken, Aktionen, Supersession-Ketten. Erst dann tritt das LLM in Aktion, und selbst dann ist es darauf beschränkt, nur über diese zusammengestellten Belege zu argumentieren.
Das Modell erfindet keine Erklärungen.
Es rekonstruiert sie.
Rückbindung an die SDLC-Memory-These
Früher stellten wir eine strategische Frage: Wenn KI die Ausführung ersetzt, was bleibt dann wertvoll?
Die Antwort war Kontext und Kausalität.
Dieses Vector-plus-Graph-Design operationalisiert diese These.
Vektorspeicher erfasst, was gesagt wurde. Graphstruktur erfasst, warum es wichtig war. Die Kombination bewahrt, wie sich das System entwickelt hat.
Ohne Vektor verlieren wir Relevanz.
Ohne Graph verlieren wir Herkunftslinien.
Ohne beides verlieren wir Gedächtnis.
Die tiefere Erkenntnis
Die meisten Teams werden dieses Jahr RAG-Pipelines bauen. Viele werden glauben, sie hätten „KI-gestütztes Wissen“.
Aber nur sehr wenige werden Provenance bauen.
Denn Provenance zwingt dazu, Struktur zu konfrontieren. Es zwingt dazu, Entscheidungen explizit zu modellieren, Richtungen zu definieren, Supersession zu handhaben, Identitäten zu erzwingen, Duplikate zu vermeiden und in kausalen Systemen statt in Dokumenten zu denken.
Das ist anspruchsvoller als Text zu embedden.
Aber genau deshalb wird es zu einem strategischen Differenzierungsmerkmal.
In einer Welt, in der KI Code schreiben und Dokumentation verfassen kann, wird der eigentliche Wettbewerbsvorteil Organisationen gehören, die ihre eigene Entwicklung erklären können — die Entscheidungen nachverfolgen, Trade-offs begründen und die verborgenen Ketten sichtbar machen können, die Ergebnisse formen.
Das ist kein Prompt-Engineering-Problem.
Es ist ein Problem der Gedächtnisarchitektur.
Und echtes Gedächtnis ist niemals flach. Es ist immer strukturiert.