From RAG to Provenance (Part 2): Wie inkrementeller Graph-Speicher tatsächlich lernt
Author: Yauheni Kurbayeu
Published: February 28, 2026
LinkedIn
Im vorherigen Artikel habe ich den Moment beschrieben, in dem wir erkannt haben, dass Vektorsuche allein kein Gedächtnis ist.
Embeddings sind hervorragend darin, ähnlichen Text zu finden. Aber Ähnlichkeit ist keine Abstammungslinie. Sie sagt dir nicht: - wer was entschieden hat, - auf welcher Annahme es basierte, - mit wem es im Konflikt stand, - und wann diese Entscheidung überholt wurde.
Dieses Mal möchte ich zeigen, was als Nächstes passiert.
Wie aktualisiert ein System tatsächlich organisationales Gedächtnis inkrementell?
Nicht in der Theorie. Nicht in Architekturdiagrammen.
Sondern Schritt für Schritt --- anhand eines einfachen Beispiels aus der
Praxis.
Step 0 --- Die Eingabe (Wo Gedächtnis beginnt)
Angenommen, diese Notiz erscheint nach einem Product‑Sync:
"Yauheni entschied, die Veröffentlichung der EU‑Instanz zu verschieben, weil eine neue GDPR‑Klarstellung der Rechtsabteilung zusätzliche Compliance‑Risiken einführt. Action item: Mit dem Security‑Team einen Maßnahmenplan zur Risikominderung vorbereiten. Anton stellte die Frage, ob wir Daten pro Workspace statt pro Region isolieren können."
Das ist zunächst nur Text.
Doch innerhalb dieses Absatzes befinden sich:
- Entscheidungen
- Risiken
- Fragen
- Action Items
- Personen
- Implizite Abhängigkeiten
Das geschäftliche Ziel ist einfach:
Lass das nicht im Slack‑Verlauf verschwinden. Wandle es in strukturiertes, nachvollziehbares organisatorisches Gedächtnis um.
Beteiligte Akteure
- Product Lead (Quellautor)
- Legal (implizite Autorität)
- Security‑Team
- Provenance‑System (AI + Graph‑Gedächtnis)
- Menschlicher Reviewer
Step 1 --- Scribing: Text in strukturierte Bedeutung umwandeln
Geschäftliches Ziel: Explizite Artefakte extrahieren, damit sie gesteuert werden können.
Das System liest den Text und wandelt ihn in strukturierte Objekte um.
Output (vereinfachtes JSON‑Beispiel):
{
"artifacts": [
{
"type": "Decision",
"title": "Postpone EU Instance Release",
"reason": "New GDPR clarification introduces compliance risks",
"owner": "Yauheni"
},
{
"type": "Risk",
"title": "Additional GDPR compliance exposure",
"source": "Legal clarification"
},
{
"type": "ActionItem",
"title": "Prepare mitigation plan with security team"
},
{
"type": "Question",
"title": "Can we isolate data per workspace instead of per region?",
"raised_by": "Anton"
}
]
}Das ist noch kein Gedächtnis. Es ist eine gestufte Interpretation.
An diesem Punkt wird noch nichts in den zentralen Graphen übernommen.
Step 2 --- Einen kleinen gestuften Graphen erstellen
Geschäftliches Ziel: Die Logik innerhalb dieser einen Notiz darstellen, bevor sie mit dem globalen Gedächtnis vermischt wird.
Aus den extrahierten Artefakten erstellt das System einen kleinen temporären Graphen.
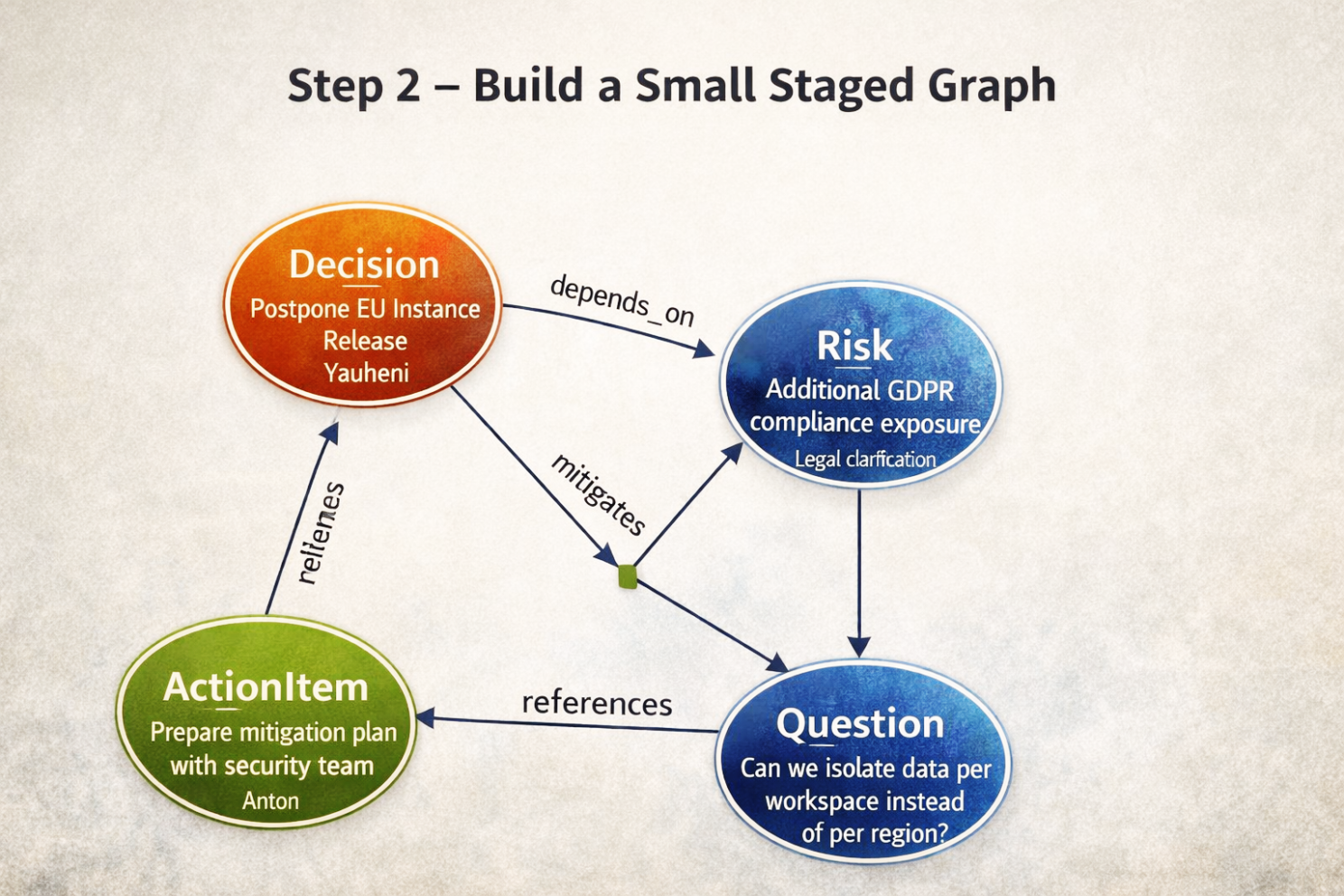
Logische Struktur:
Decision → depends_on → Risk
ActionItem → mitigates → Risk
Question → references → DecisionDieser Graph existiert nur innerhalb der aktuellen Transaktion.
Er ist noch nicht Teil des permanenten Unternehmensgedächtnisses.
Warum?
Weil wir noch nicht wissen, ob:
- dieses Risiko bereits existiert,
- die Entscheidung eine Fortsetzung einer früheren ist,
- eine höher rangige Autorität zuvor etwas anderes entschieden hat.
Step 3 --- Semantischer Vergleich (aber nicht blind)
Geschäftliches Ziel: Erkennen, ob diese Objekte bereits im Gedächtnis existieren.
Das System prüft semantische Ähnlichkeit mit bestehendem Gedächtnis.
Angenommen, es findet:

Nun steht das System vor einer geschäftlichen Frage:
- Sind das dieselben Dinge?\
- Oder sind sie verwandt, aber unterschiedlich?
Vektoren allein können das nicht beantworten.
Deshalb ruft das System Kontext aus dem Graphen ab:
- Wer war Eigentümer der früheren Entscheidung?
- Was war der Grund?
- War sie temporär?
- Wurde sie später überholt?
Hier wird Graph‑Gedächtnis entscheidend.
Step 4 --- Identitätsauflösung (zusammenführen oder erstellen?)
Geschäftliches Ziel: Duplikate vermeiden, ohne Nuancen zu zerstören.
Das System bewertet:
- Die alte Entscheidung „Delay EU rollout (Q1)" entstand aufgrund von Infrastrukturinstabilität.
- Die neue Verschiebung basiert auf rechtlichen Risiken.
Anderer Grund. Anderer Umfang. Anderer Zeitpunkt.
Entscheidung:
- ✔ Einen neuen Decision‑Knoten erstellen\
- ✔ Ihn mit dem bestehenden GDPR‑Risiko‑Knoten verknüpfen
Wenn das Risiko bereits existiert, duplizieren wir es nicht.
Wir stärken es.
Gedächtnis wird geschichtet, nicht fragmentiert.
Step 5 --- Bewertung und Gewichtung von Beziehungen
Geschäftliches Ziel: Die Stärke von Beziehungen quantifizieren.
Nicht alle Abhängigkeiten sind gleich.
Beispiel:
- Decision depends_on Risk → starke kausale Verbindung
- Question references Decision → schwächere kontextuelle Verbindung
Jede Kante erhält:
- Evidenz‑Auszug
- Konfidenz‑Score
- Quellenreferenz
- Transaktions‑ID
Beispiel:
{
"from": "Decision: Postpone EU Instance Release",
"to": "Risk: GDPR data residency risk",
"type": "depends_on",
"weight": 0.82,
"evidence": "because the new GDPR clarification introduces additional compliance risks",
"source": "Product Sync 2026-02-27"
}Jetzt kann das System beantworten:
- Warum wurde diese Veröffentlichung verschoben?
- Welche Risiken rechtfertigten sie?
- Wie stark war die zugrunde liegende Begründung?
Step 6 --- Konflikterkennung (Autorität ist wichtig)
Stellen wir uns nun etwas Wichtiges vor.
Vor zwei Monaten entschied der CTO offiziell:
"EU instance must go live before Q2 to support enterprise pipeline."
Höhere Autorität. Entgegengesetzte Richtung.
Das System erkennt:
- Gleicher Umfang (EU‑Instanz)
- Gegensätzliche Entscheidung
- Unterschiedliche Rangordnung der Eigentümer
Es meldet:
⚠ Konflikt: Eine Entscheidung mit höherer Autorität existiert.
An diesem Punkt blockiert das System nicht die Realität.
Es fordert eine menschliche Validierung an.
Das ist Governance, nicht Automatisierung.
Step 7 --- Menschliche Überprüfung (Vertrauensebene)
Geschäftliches Ziel: Verantwortlichkeit erhalten.
Der Reviewer sieht ein Change‑Set.
Erstellt:
- Neue Decision
- Neues ActionItem
Führt zusammen:
- Risk → bestehendes GDPR‑Risiko
Beziehungen:
- Decision depends_on Risk
- ActionItem mitigates Risk
Konflikt:
- Frühere CTO‑Anweisung erfordert Überprüfung
Der Reviewer kann:
- Genehmigen
- Ändern
- Eskalieren
- Die frühere Entscheidung explizit überholen
Wenn sie überholt wird:
Decision A → supersedes → Decision BKeine Löschung. Keine Umschreibung der Geschichte.
Nur Evolution.
Step 8 --- Commit (Atomare Gedächtnisaktualisierung)
Nach der Genehmigung schreibt das System alles in einer einzigen Transaktion.
Der kanonische Graph enthält nun:
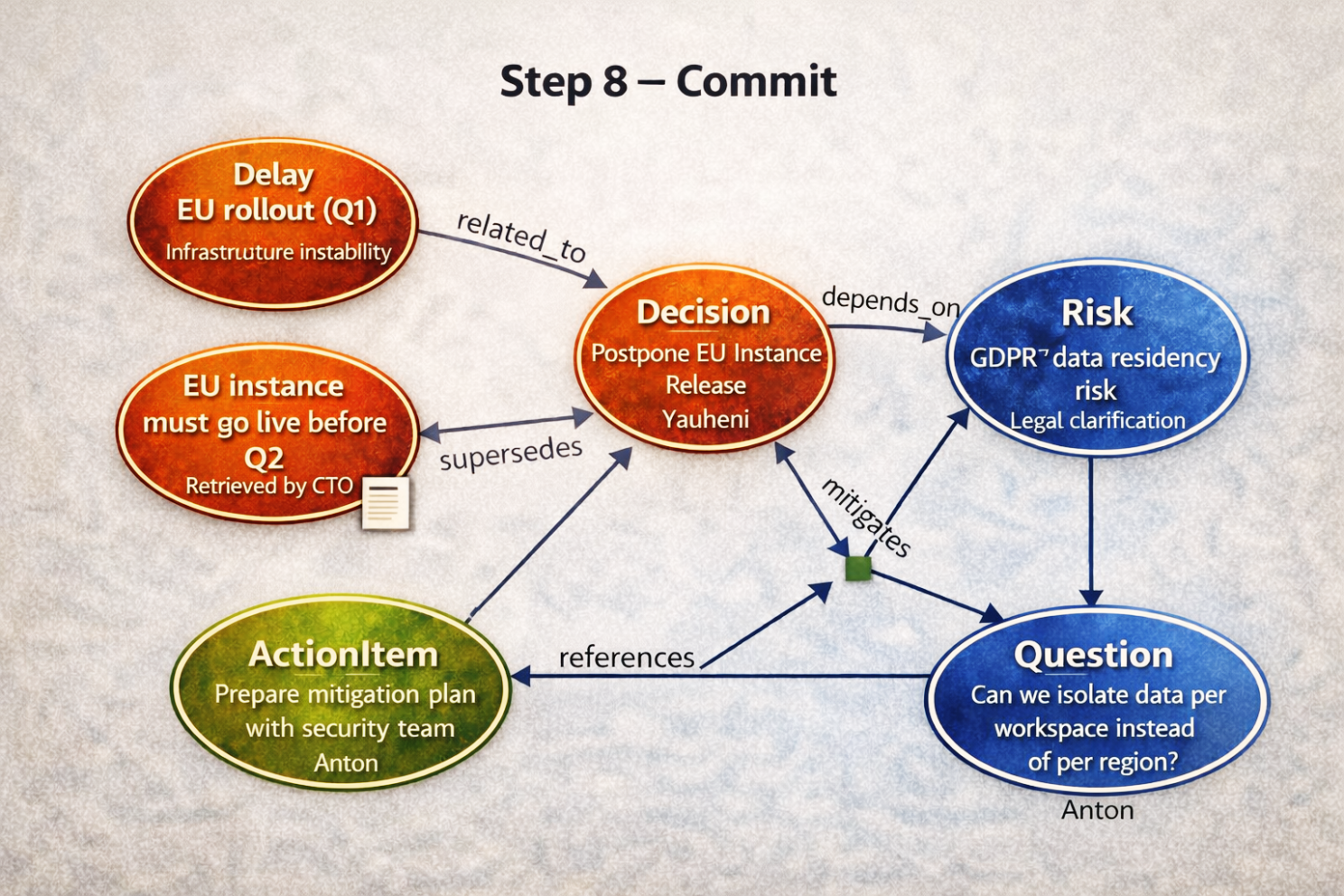
- Decision (Postpone EU Release)
- Risk (GDPR Data Residency)
- Action Item (Mitigation Plan)
- Question (Data Isolation Strategy)
- Supersedes / conflicts (falls zutreffend)
Jedes Element speichert:
- Wer es eingeführt hat
- Wann
- Auf welchem Text es basiert
- Verknüpfte frühere Artefakte
- Ob es etwas überstimmt hat
Das ist Gedächtnis.
Warum das über Architektur hinaus wichtig ist
Treten wir einen Schritt zurück.
In den meisten Organisationen:
- sind Entscheidungen verstreut
- geht die Begründung verloren
- wechseln Verantwortlichkeiten
- verschwindet Kontext
- streiten Menschen über Geschichte, statt Probleme zu lösen.
Mit inkrementellen Provenance‑Updates:
- wird jede Notiz zu strukturierter Governance
- wird jede Abhängigkeit explizit
- wird jeder Konflikt sichtbar
- wird jede Veränderung nachvollziehbar
Das ist kein RAG.
Das ist nicht nur Vektorähnlichkeit.
Das ist Akkumulation von Entscheidungs‑Kapital.
Der größere Wandel
Wenn 50--80 % der Ausführung von AI‑Agenten statt von Ingenieuren erfolgen, wird das noch kritischer.
Agenten werden:
- Pläne generieren
- Entscheidungen vorschlagen
- Action Items erstellen
- Systeme refaktorisieren
- Architekturen verändern
Ohne strukturiertes Gedächtnis: verstärken sie Entropie.
Mit Provenance: operieren sie innerhalb von Governance.
Der Unterschied ist nicht Produktivität.
Der Unterschied ist Überlebensfähigkeit.
Von Retrieval zu Evolution
RAG beantwortet Fragen über die Vergangenheit.
Provenance baut die Vergangenheit inkrementell auf.
Jede Ingestion:
- extrahiert Bedeutung
- löst Identitäten auf
- validiert Autorität
- dokumentiert Abstammung
- stärkt oder aktualisiert bestehendes Gedächtnis
Mit der Zeit wird der Graph zu:
- einer Entscheidungshistorie
- einer Risiko‑Heatmap
- einem Governance‑Ledger
- einem lebendigen SDLC‑Gedächtnis
Und das geschieht inkrementell.
Eine Meeting‑Notiz nach der anderen.