Decision Provenance How-To Guide
Author: Yauheni Kurbayeu
Published: Mar 28, 2026
TL;DR
In the previous article, Managing Agent Context and the Exchange Protocol, we focused on how agents keep shared context, how they hand work to one another, and how a stable exchange contract makes multi-agent execution reliable in practice.
In this article, we move from agent flow to agent memory.
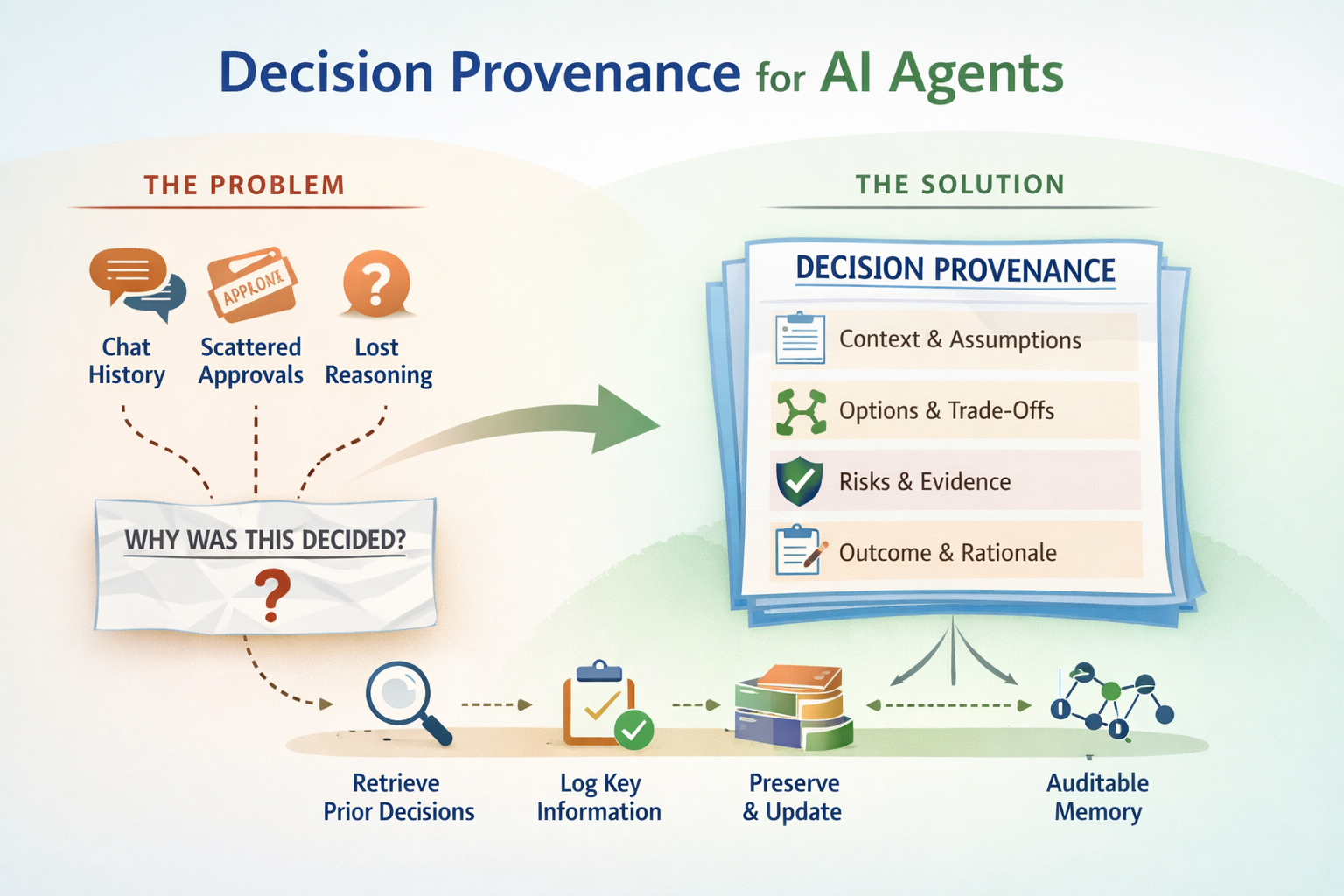
Many teams are already letting AI recommend rollout strategies, architectural changes, policy interpretations, and operational choices. But when those choices need review later, the reasoning is often gone: the prior decisions are unclear, the approval boundary is missing, and the assumptions live only in chat history.
The goal here is to show how to give AI agents a lightweight decision provenance layer so they can retrieve relevant prior decisions before acting, log only decisions that are worth preserving, and keep context, assumptions, alternatives, risks, and evidence in a reusable form.
The result is not raw chat history and not generic observability. It is a practical decision memory pattern you can start with files today and later evolve into a graph-backed provenance system.
The Real Problem
This guide shows how to build a lightweight decision provenance system for AI agents.
The point is not to log every action. The point is to give agents a reusable decision loop:
- retrieve useful prior decisions before making a new one
- compare bounded context before reusing a prior
- log only meaningful decisions, not execution noise
- preserve context, assumptions, alternatives, risks, and evidence
- update old decisions when later evidence validates, invalidates, or supersedes them
In short, this pattern gives your agents a reusable decision memory instead of a pile of chat history.
What You Actually Get
If you implement the pattern below, you will have:
- a threshold skill that decides whether a candidate decision is worth logging
- a provenance contract that defines one portable decision record format
- a file-based backend you can use immediately
- an optional graph backend you can wire later
- agents that retrieve priors before deciding and return decision trace ids after logging
This is useful when you want agents to make decisions more consistently over time, explain themselves better, and leave an auditable trail that can be reused later.
Why AI Teams Need This Now
The current AI shift is changing the failure mode.
Many teams now face some version of this:
- an agent proposes a reasonable solution, but nobody can trace which prior decisions it reused
- a human approves or overrides a risky action, but the approval disappears into chat history
- a team reuses an old decision in a new situation and silently imports the wrong assumptions
- the output looks good, but the intent behind it is no longer recoverable
That is why this is no longer only a documentation problem.
It is becoming a memory problem, a governance problem, and in some workflows an AI safety problem.
Many agent systems still fall into one of two extremes:
- They store nothing, so every session starts from scratch.
- They store too much raw conversation, so future reuse becomes noisy and unsafe.
Decision provenance is the middle path. It stores only major decisions, and it stores them in a form that is structured enough to reuse carefully.
In Provenance Manifesto terms, this guide is one practical way to apply a few core ideas to agent workflows:
- decisions should be treated as first-class artifacts
- decisions must carry context
- decisions must be queryable
- decisions evolve but are never erased
It also helps separate two layers that are often blurred together.
- the knowledge layer tells us what artifacts, tickets, notes, or code exist
- the provenance layer preserves why a decision was made, which assumptions shaped it, which alternatives were rejected, and how that decision later evolved
This guide is about that second layer: the reasoning memory that makes agent behavior more reusable, auditable, and governable over time.
Conceptually, this pattern is influenced by the First Principles Framework (FPF), especially these ideas:
- decisions should be grounded in a bounded context
- reasoning should be externalized into durable forms
- logging should cite policy owners instead of redefining them
- provenance should be more than a narrative "because story"
- refresh and decay should be handled explicitly
Reference source:
- First Principles Framework (FPF) - Core Conceptual Specification
- Author line: Anatoly Levenchuk and assortment of LLMs
- Edition: March 2026
Packaging Notes
The operational problem is framework-independent. The file layout below is only one practical reference implementation.
The sample implementation in this guide is intentionally shaped around GitHub Copilot conventions:
- repository-level
copilot-instructions.md .agent.mdagent profilesSKILL.mdskill files- file-based workflow examples that fit Copilot-style repository customization
That makes it a reference implementation, not a universal packaging standard.
The underlying architecture is broader than GitHub Copilot, though. The same pattern can be ported to almost any agentic framework by mapping the layers like this:
- Copilot custom instructions -> global system or workspace instructions
- Copilot custom agents -> specialized agent profiles or role prompts
- Copilot skills -> reusable capability contracts or prompt modules
- provenance backend skill -> storage adapter or persistence service
- decision note template -> canonical record schema in JSON, YAML, Markdown, database rows, or graph nodes
So the file names and packaging here are Copilot-specific, but the decision-memory design itself is framework-agnostic.
What You Will Build
.github/
copilot-instructions.md
agents/
decision-advisor.agent.md
skills/
decision-logging-threshold/
SKILL.md
decision-provenance/
SKILL.md
decision-provenance-obsidian/
SKILL.md
decision-provenance-neo4j/
SKILL.md # optional
provenance/
decisions/
_template.md
dec-*.mdArchitecture at a Glance
Agent
|
| retrieve prior decisions
v
Decision provenance interface
|
| score whether the new decision should be logged
v
Decision logging threshold
|
| if yes, write through active backend
v
File backend or graph backend
|
| return decision_id
v
Agent response notesFast Path
If you only want the core loop, it is this:
- Retrieve prior decisions before making a major choice.
- Compare bounded context, ownership, and assumptions before reusing a prior.
- Make the new decision and state the trade-offs, risks, and caveats explicitly.
- Run the threshold check and persist the decision only if it deserves durable memory.
- Update the same decision later when evidence validates, invalidates, or supersedes it.
Everything else in this guide expands one of those five steps.
The Core Concepts
1. Not every step deserves memory
You should log only meaningful decisions:
- strategy choices
- non-trivial trade-offs
- decisions with durable impact
- policy or escalation boundaries
You should not log:
- formatting
- deterministic transforms
- pure retrieval
- mechanical tool calls
- repeated micro-decisions inside an already chosen strategy
2. A decision is reusable only inside context
A good provenance record must say:
- what was decided
- in what domain and scope
- under which invariants
- based on which assumptions and evidence
- with which confidence and caveats
Without that, future agents may reuse an old decision in the wrong situation.
3. The system should separate concerns
Use one owner for each job:
- threshold skill: "should this be logged?"
- provenance skill: "what is the record format and lifecycle?"
- backend skill: "where does the record live?"
That separation keeps the system easier to evolve.
Step-by-Step Setup
Step 1. Add global instructions
Create .github/copilot-instructions.md:
Every agent in this project should treat decision provenance as reusable memory.
Before making a major decision:
- retrieve relevant prior decisions by domain, scope, or keywords
- prefer validated and higher-confidence priors
- compare bounded context before reusing an old decision
After making a decision:
- call the decision-logging-threshold skill
- if the result says the decision should be logged, write it through the active provenance backend
- include decision_trace_ids in the agent return notes
Do not log:
- deterministic transforms
- retrieval-only steps
- mechanical execution
- repeated micro-decisions inside an already selected strategy
The default backend is the file-based Markdown backend unless an agent explicitly switches to a graph backend.Step 2. Add the threshold skill
Create .github/skills/decision-logging-threshold/SKILL.md:
---
name: decision-logging-threshold
description: Shared scoring and gating policy that decides whether a candidate decision should be persisted.
---
# Decision Logging Threshold
Use this skill before writing any decision to provenance.
## Ownership
This skill owns:
- scoring dimensions
- mandatory overrides
- the final log / no-log gate
Other skills may store the threshold result, but should not redefine the scoring model.
## Core rule
decision_score =
impact_radius +
reversibility +
uncertainty +
tradeoff_intensity +
longevity
Log if:
- decision_score >= 5
- or a mandatory override applies
## Dimensions
- impact_radius: 0 local, 1 cross-component, 2 system-wide
- reversibility: 0 easy, 1 reversible with cost, 2 hard or irreversible
- uncertainty: 0 deterministic, 1 some judgment, 2 high ambiguity
- tradeoff_intensity: 0 none, 1 minor, 2 explicit competing options
- longevity: 0 ephemeral, 1 medium-lived, 2 persistent
## Mandatory overrides
- security, privacy, legal, financial, or compliance boundaries
- human approval, rejection, override, or escalation boundaries
## Standard output
threshold_check:
threshold_policy_ref: decision-logging-threshold/v1
impact_radius: 0|1|2
reversibility: 0|1|2
uncertainty: 0|1|2
tradeoff_intensity: 0|1|2
longevity: 0|1|2
decision_score: <0..10>
mandatory_overrides: []
override_applied: true|false
usefulness_gate: true|false
should_log: true|false
rationale: <short reason>How to Decide What Deserves Memory
The threshold skill is a practical significance heuristic, not a formal industry standard.
Its job is simple:
- avoid logging trivial execution noise
- reliably capture decisions that are likely to matter later
The model uses five small dimensions because they are easy for humans and agents to score consistently during real work.
The formula
decision_score =
impact_radius +
reversibility +
uncertainty +
tradeoff_intensity +
longevityPossible total range:
- minimum:
0 - maximum:
10
Default decision gate:
0-2: almost certainly do not log3-4: usually do not log unless the usefulness test is clearly true5+: log- any mandatory override: log even if the numeric score is lower
This makes the threshold easy to apply while still leaving room for judgment.
Metric 1. impact_radius
Question:
If this decision is wrong or later needs to change, how wide is the blast radius?
Scoring:
0= local to one step, file, component, or one narrow workflow1= affects multiple components, one team boundary, or one meaningful workflow2= system-wide, cross-team, customer-wide, policy-wide, or organization-wide effect
Examples:
- renaming one helper method:
0 - choosing one cache strategy for multiple services:
1 - deciding whether to launch a risky feature to all customers:
2
How to think about it:
This dimension is closest to classic impact or consequence assessment in risk-informed decision making.
Metric 2. reversibility
Question:
How hard is it to undo this decision once it is made?
Scoring:
0= easy to reverse quickly with low cost1= reversible, but only with real migration, rollback, coordination, or cleanup cost2= hard to reverse, path-dependent, or effectively irreversible
Examples:
- trying a prompt tweak in one internal workflow:
0 - changing a database access pattern that requires coordinated rollout:
1 - committing to an architecture or customer contract that is very expensive to unwind:
2
How to think about it:
This dimension is strongly inspired by the one-way door vs two-way door decision model used by Amazon and AWS guidance, where reversible decisions can move faster and harder-to-reverse decisions deserve more scrutiny.
Metric 3. uncertainty
Question:
How much is this decision being made under incomplete evidence, ambiguity, or unstable assumptions?
Scoring:
0= mostly deterministic, well-understood, and low ambiguity1= some unknowns remain, but the decision is still reasonably bounded2= major uncertainty, conflicting signals, sparse evidence, or high ambiguity
Examples:
- applying a known rule with clear inputs:
0 - choosing between two reasonable options with partial but decent evidence:
1 - deciding during an incident with incomplete telemetry and conflicting stakeholder signals:
2
How to think about it:
This does not mean "uncertain decisions are bad." It means uncertain decisions are often more valuable to preserve because future teams need to know what was believed, what was missing, and why the choice still happened.
Metric 4. tradeoff_intensity
Question:
Is this a real choice among competing goals, or just straightforward execution?
Scoring:
0= no meaningful trade-off, almost purely mechanical1= some competing considerations exist, but one option is still fairly obvious2= clear tension between multiple legitimate options, goals, or stakeholders
Examples:
- converting one file format to another with no alternatives:
0 - choosing between two implementation paths with mild pros and cons:
1 - balancing reliability vs growth, fraud prevention vs conversion, or speed vs compliance:
2
How to think about it:
Trade-off intensity is important because decisions become historically valuable when they reveal competing goals, not when they merely record execution.
Metric 5. longevity
Question:
For how long is this decision likely to shape later work?
Scoring:
0= ephemeral, short-lived, or disposable1= medium-lived, likely to influence the current task or near-term cycle2= persistent, foundational, or likely to influence many later decisions
Examples:
- one temporary troubleshooting step:
0 - a sprint-level rollout choice:
1 - a platform policy, long-lived architecture decision, or enduring customer strategy:
2
How to think about it:
Longevity matters because the best candidates for provenance are decisions that future agents or humans may need to revisit months later.
How to calculate the score in practice
Use the smallest score that is still honest.
A good workflow is:
- Score each metric independently.
- Write one sentence explaining each non-zero score.
- Sum the five values.
- Apply the mandatory overrides.
- Apply the usefulness check: "Would this decision be useful as a prior or audit artifact later?"
If the numeric score is low and the usefulness answer is no, do not log it.
Example calculation
Scenario:
Should we add stricter identity checks that reduce fraud but may drop conversion by 12%?Example scoring:
impact_radius: 2
reversibility: 1
uncertainty: 1
tradeoff_intensity: 2
longevity: 2
decision_score: 8
usefulness_gate: true
should_log: trueWhy:
impact_radius: 2because the choice affects customers, fraud rates, revenue, and operationsreversibility: 1because the policy can be changed, but only with cost and coordinationuncertainty: 1because conversion impact is estimated, not fully knowntradeoff_intensity: 2because fraud prevention and growth are directly in tensionlongevity: 2because the decision can shape ongoing policy and risk posture
What this metric model is built on
This exact five-factor threshold is a local heuristic, but it is built on a blend of familiar decision and architecture ideas:
- ADR practice: only significant decisions deserve durable records, and those records should preserve context, options, consequences, and confidence
- risk-informed thinking: significance grows with consequence, uncertainty, and cost of reversal
- trade-off analysis: competing goals are strong signals that a decision is worth preserving
- reversibility discipline: hard-to-reverse decisions deserve stronger memory and review
In other words, this is not pretending to be a universal formula. It is a small operational scoring model designed to make those broader ideas usable by agents.
External references behind the threshold concept
- Architectural Decision Records (ADR) overview
- Google Cloud: Architecture decision records overview
- Microsoft Learn: Maintain an architecture decision record (ADR)
- AWS Well-Architected: Evaluate tradeoffs while managing benefits and risks
- AWS Executive Insights: one-way door and two-way door decision model
- AWS Prescriptive Guidance: reversible vs irreversible data-driven actions
- NIST: Risk-based decision making for sustainable and resilient infrastructure
- NIST: Incorporating Attribute Value Uncertainty into Decision Analysis
Mandatory Overrides Deep Dive
Mandatory overrides exist because some decisions are important even when the numeric score is not especially high.
The threshold formula is good at catching durable trade-offs, but it can miss decisions that matter mainly because of governance, accountability, or legal significance. That is why the model includes an override layer.
In simple terms:
- the score asks, "How significant is this decision?"
- the override asks, "Would it be unsafe or irresponsible not to preserve this decision?"
If the answer to the second question is yes, log it.
Why overrides exist
Some decisions deserve a record not because they are technically complex, but because they cross a boundary that requires traceability.
Typical examples:
- a privacy-sensitive data access exception
- a security control bypass during an incident
- a human approval or rejection that changes the course of action
- a compliance-related interpretation applied to a real case
- an escalation where responsibility shifts from agent to human or from one team to another
These may score only 2, 3, or 4 numerically, but they still should be logged because the audit value is high.
Override category 1. Policy, compliance, and controlled boundaries
Use an override when the decision touches a governed boundary such as:
- security
- privacy
- legal or regulatory interpretation
- financial controls
- business-rule enforcement
- data retention or data deletion policy
- safety-critical operating constraints
Why:
These decisions often require future proof that:
- the boundary was recognized
- someone made a conscious choice
- the applicable policy was identified
- later review is possible
Example:
An agent decides to block account creation because a fraud rule fired, even though the technical workflow itself is routine.That may not be a high trade-off score every time, but it still crosses a policy boundary and may need later review, dispute handling, or audit.
Override category 2. Human interaction and accountability boundaries
Use an override when the decision includes:
- explicit human approval
- explicit human rejection
- manual override
- escalation
- delegated exception handling
- a handoff where the accountable decision-maker changes
Why:
These moments are often important because they show:
- who actually authorized the action
- where autonomous behavior stopped
- where responsibility changed
- what judgment was accepted despite uncertainty
Example:
The agent recommends rollback, but a human incident commander explicitly approves a hotfix-in-place instead.That event should be logged even if the numeric score for the final action is not extreme, because the approval boundary itself is part of the provenance.
How overrides interact with the total score
Think of overrides as a second gate, not as extra points.
Do this:
- Calculate the numeric score normally.
- Check whether any override category applies.
- If yes, set:
override_applied: true
should_log: true
mandatory_overrides:
- <override reason>Do not do this:
- do not artificially inflate the numeric metric values just to force logging
- do not hide override reasoning inside free-form prose
- do not skip logging just because the score is below
5
The score and the override serve different purposes.
Practical examples
Example 1: low numeric score, but still log
impact_radius: 0
reversibility: 1
uncertainty: 0
tradeoff_intensity: 0
longevity: 0
decision_score: 1
mandatory_overrides:
- privacy-boundary
override_applied: true
should_log: true
rationale: A privacy-governed exception was applied and must remain auditable.Example 2: ordinary technical choice, no override
impact_radius: 1
reversibility: 1
uncertainty: 0
tradeoff_intensity: 1
longevity: 0
decision_score: 3
mandatory_overrides: []
override_applied: false
should_log: false
rationale: Useful locally, but not important enough as a durable prior.Example 3: human override during incident handling
impact_radius: 1
reversibility: 1
uncertainty: 1
tradeoff_intensity: 1
longevity: 0
decision_score: 4
mandatory_overrides:
- human-override
override_applied: true
should_log: true
rationale: The accountable decision was explicitly changed by a human approver.A good rule of thumb
Apply a mandatory override when the decision creates one of these needs:
- future auditability
- future dispute resolution
- future accountability tracing
- future policy review
- future explanation of why a normal rule was bypassed, approved, or rejected
If the main value of the record is traceability rather than technical complexity, that is usually a sign that an override is appropriate.
Common mistakes
- logging every human-facing event as an override even when no real approval or exception occurred
- failing to log low-score compliance decisions because they "look routine"
- inflating metric scores instead of using the override mechanism honestly
- writing
override_applied: truewithout naming the override reason
The cleanest pattern is:
- keep the metrics honest
- use overrides only for real governance and accountability boundaries
- always name the override explicitly
Step 3. Add the provenance interface skill
At this point, we already have a threshold skill that can answer:
Is this decision important enough to log?
What we do not yet have is a shared contract for everything that happens before and after that answer.
That is what the provenance interface skill is for.
What the provenance interface skill is
The provenance interface skill is the behavioral and structural contract for decision memory.
It is not the storage backend.
It is not the scoring policy.
It is the layer that defines:
- what a decision record is
- what fields must be present for safe reuse
- how agents retrieve prior decisions
- how agents write new decisions
- how agents update old decisions when reality changes
You can think of it as the API contract between agent reasoning and persistence.
In other words:
- the threshold skill decides whether a decision deserves memory
- the provenance interface defines what that memory must look like
- the backend decides where that memory lives
What it is exactly doing
The provenance interface skill does four jobs.
1. It standardizes the decision record
Without a shared record format, every agent will log decisions differently:
- one agent stores assumptions
- another stores only the conclusion
- another omits alternatives
- another forgets to record confidence or evidence gaps
That makes the memory unsafe to reuse.
The interface solves that by forcing every logged decision into the same conceptual shape.
2. It standardizes the lifecycle
The interface defines three core operations:
RETRIEVE_DECISIONSWRITE_DECISIONUPDATE_DECISION
That matters because provenance is not only about writing records. It is also about:
- consulting priors before deciding
- preserving new decisions after deciding
- revising the state of those decisions when new evidence appears
3. It standardizes reuse boundaries
The interface forces agents to compare bounded context before importing a prior decision.
That changes provenance from:
- "find something similar and copy it"
into:
- "find something relevant, compare context, then decide whether it is a valid prior"
That is a much safer pattern.
4. It standardizes traceability
The interface ensures that all logged decisions expose:
- who made the decision
- why it was made
- what alternatives were considered
- how confident the agent was
- which priors informed it
- how it can later be validated, invalidated, or refreshed
That makes the resulting memory useful not only for retrieval, but also for audit, governance, and review.
How it should be embedded into agents
An agent should not treat provenance as an optional afterthought.
If an agent can make meaningful decisions, it should load the provenance interface skill directly in its instruction set together with:
- the threshold skill
- one active backend
Minimal example:
Use the `decision-logging-threshold` skill.
Use the `decision-provenance` skill.
Use the `decision-provenance-obsidian` skill.This means the agent is expected to operate with the following loop:
- Retrieve priors before making a major decision.
- Make the decision.
- Score it using the threshold skill.
- If it qualifies, write it through the backend using the provenance contract.
- If later evidence arrives, update the same decision instead of silently replacing it.
How it changes agent behavior
Adding the provenance interface changes agent behavior in a real way.
Without this skill, agents often behave like this:
- answer the question in the moment
- provide a rationale
- move on
With this skill, agents should behave more like this:
- search for prior decisions first
- reason with context and comparability in mind
- express assumptions, caveats, evidence gaps, and alternatives explicitly
- decide whether the outcome should become durable memory
- preserve links between old and new decisions
- revisit the decision when new evidence changes its status
So this skill changes the agent from a stateless responder into a participant in an evolving decision system.
What good embedding looks like in practice
When the skill is embedded correctly, you should see these behavior changes:
- the agent consults prior decisions before making similar ones
- the agent distinguishes between execution noise and decision-worthy trade-offs
- the agent logs only major decisions, but logs them consistently
- the agent returns
decision_trace_idsin its notes - the agent updates existing decisions instead of creating contradictory replacements without lineage
What bad embedding looks like
Common failure modes include:
- including the skill in the prompt but never actually retrieving priors
- writing records without using the canonical schema
- logging every action as if it were a decision
- never calling
UPDATE_DECISIONafter later evidence arrives - using provenance only as storage, not as part of the decision loop
The interface is valuable only when it changes behavior, not when it exists only as a file in the repository.
Create .github/skills/decision-provenance/SKILL.md:
---
name: decision-provenance
description: Storage-agnostic decision memory layer for retrieving, writing, and updating major decisions.
---
# Decision Provenance
Use this skill to define what a decision record is and how agents interact with it.
Use it together with:
- decision-logging-threshold
- one provenance backend
## Rule
Before logging a decision:
- call decision-logging-threshold
- store the returned threshold_check object
This skill does not own threshold semantics.
## Record id
dec-<YYYY-MM-DD>-<agent>-<slug>
## Canonical record
decision_id: dec-YYYY-MM-DD-agent-slug
agent: <agent-name>
decision_owner: <person|team|agent>
owner_role: <role or accountable function>
approved_by: ""
approved_by_role: ""
date: <ISO-8601 timestamp>
decision: "<what was decided>"
bounded_context:
domain: <domain>
scope: <scope>
context_version: v1
invariants:
- <rule>
reasoning: "<why>"
considered_alternatives:
- "<option>"
rejected_alternatives:
- alternative: "<option>"
reason: "<why rejected>"
assumptions:
- "<assumption>"
risks_accepted:
- "<risk>"
caveats:
- "<qualifier>"
evidence_gaps:
- "<missing evidence>"
evidence_refs:
- "<artifact or trace id>"
policy_refs:
- "<policy id>"
threshold_check:
threshold_policy_ref: decision-logging-threshold/v1
impact_radius: 0
reversibility: 0
uncertainty: 0
tradeoff_intensity: 0
longevity: 0
decision_score: 0
mandatory_overrides: []
override_applied: false
usefulness_gate: true
should_log: true
rationale: "<short reason>"
confidence: medium
confidence_basis: "<why this confidence level is justified>"
decision_links:
parent: ""
informs: []
supersedes: []
conflicts_with: []
parallel_to: []
validated_by: []
invalidated_by: []
validation_plan:
signals:
- "<what to watch>"
check_window: "<when to re-evaluate>"
validation_status: pending
review_by: ""
refresh:
status: active
triggers: []
last_reviewed_at: ""
superseded_by: ""
outcome: pending
incidents: []
evolution_log:
- date: <ISO-8601>
change: "Initial decision"
tags:
- decision
- agent/<agent-name>
- domain/<domain>
- status/pending
## Operations
RETRIEVE_DECISIONS
- use before making a decision
- query by domain, scope, agent, tags, keywords, or evidence ref
- rank validated and higher-confidence priors first
WRITE_DECISION
- use only when threshold_check.should_log is true
- populate the full record
- write through the active backend
- return the decision_id
UPDATE_DECISION
- use when new evidence arrives
- append incidents and evolution entries
- update validation_status, review_by, refresh, and decision_links
## Return notes
notes:
- decision_trace_ids: [dec-...]
- prior decisions consulted: [dec-...]Step 4. Add the backend implementation
At this point, we already have:
- a threshold skill that decides whether a decision should be logged
- a provenance interface that defines the record shape and lifecycle
What we still need is a real persistence layer.
For the first prototype, the simplest useful answer is:
- use Obsidian-compatible Markdown as the decision memory
- keep a graph-shaped mental model from day one
- keep Neo4j only as scaffolding for future migration, not as the final production target
Why Obsidian is a good first implementation
For initial prototyping, Obsidian can be used as-is as a lightweight decision memory implementation.
That works well because it is:
- human-readable
- versionable with normal source control
- searchable with plain text tools
- structurally rich enough to hold front matter plus links
- easy to evolve while the provenance schema is still stabilizing
In early stages, transparency matters more than infrastructure sophistication.
A lightweight Markdown vault is often the fastest way to prove that the contract is useful before investing in a more advanced storage stack.
Why a backend is needed at all
The backend is not just storage. It is what makes decision memory operational.
A usable provenance backend must preserve three properties:
1. Decisions must be queryable
If decisions cannot be found again, they are not functioning as memory.
That means a backend must support retrieval by things like:
- domain
- scope
- agent
- tags
- keywords
- evidence references
- validation state
This is why even a Markdown implementation should keep machine-readable YAML front matter instead of storing everything as loose prose.
2. Decisions must be attributable
Every meaningful decision must have ownership.
Attribution matters because it answers questions like:
- who made this decision
- who approved or overrode it
- in what role or context it was made
- who is accountable for revisiting it later
Accountability enables trust, governance, and responsible change.
The runtime agent that produced a recommendation and the accountable owner of the decision may be the same, but they should not be assumed to be identical.
3. Decisions evolve but are never erased
A provenance system is not a page that gets silently rewritten.
Decisions may be:
- revised
- superseded
- invalidated
- branched into context-specific variants
But their history should remain preserved.
Organizational intelligence grows through the evolution of reasoning, not through rewriting history.
That is why the backend must support append-oriented history such as:
incidentsevolution_logvalidation_statusrefresh- typed decision links such as
supersedes,validated_by, andinvalidated_by
What the decision-provenance-obsidian skill does
The decision-provenance-obsidian skill is the concrete backend implementation for the abstract provenance contract.
It does three things:
- Stores each decision as one Markdown file.
- Uses YAML front matter as the machine-readable node payload.
- Builds relationship edges through wikilinks in the Markdown body.
In practice, each file acts like a decision node:
provenance/
decisions/
_template.md
dec-*.mdThe YAML front matter carries structured fields such as:
decision_iddecision_ownerowner_rolebounded_contextthreshold_checkdecision_linksvalidation_statusrefresh
The Markdown body keeps the same record readable by humans and visible in Obsidian graph views.
How edges are represented in Obsidian
The decision template defines the relationship vocabulary through the decision_links object and the corresponding wiki-link section in the note body.
The edge types are:
parentThe current decision is derived from or nested under a parent decision.informsA prior decision materially informed this one.supersedesA newer decision replaces an older one.conflicts_withTwo decisions are in meaningful tension.parallel_toDecisions were made in parallel on related work.validated_byA later decision or event strengthened confidence in this one.invalidated_byA later decision or event undermined this one.
So the Obsidian backend is already graph-shaped, even though the first storage surface is just Markdown.
That matches the backend switching guidance used in the prototype architecture:
- the abstract
decision-provenancecontract stays stable - different backends can implement the same retrieval/write/update lifecycle
- decision ids stay stable across backends so lineage can survive migration
Sample backend skill
Create .github/skills/decision-provenance-obsidian/SKILL.md:
---
name: decision-provenance-obsidian
description: File-based Markdown backend for the decision-provenance interface.
---
# Decision Provenance File Backend
Use this backend to store decisions as local Markdown files.
## Storage layout
provenance/
decisions/
_template.md
dec-*.md
## Retrieval
- search decision files by bounded_context, agent, tags, decision text, or evidence refs
- rank validated records first, then by confidence
## Write
- create one file per decision: provenance/decisions/<decision_id>.md
- store machine-readable fields in YAML front matter
- store a readable explanation in the Markdown body
- include wikilinks only when links are populated
- never write empty links like [[]]
## Update
- append incidents
- append evolution entries
- update validation_status, review_by, refresh, and tagsOne meaningful example
A strong example from the prototype decision set is the fraud-vs-growth identity-check decision.
Why this example is useful:
- it has a high threshold score
- it includes mandatory overrides
- it shows bounded context clearly
- it includes evidence refs and policy refs
- it leaves room for later validation and refresh
Condensed example:
decision_id: dec-2026-03-28-incident-fraud-vs-growth-identity-checks
agent: critical-tradeoff-advisor
decision_owner: fraud-risk-policy-owner
owner_role: risk-policy-owner
approved_by: head-of-risk
approved_by_role: accountable-human-approver
decision: "Introduce stricter identity checks in a risk-targeted way, accepting some conversion loss."
bounded_context:
domain: risk-tradeoff
scope: fraud-vs-growth-identity-checks
threshold_check:
decision_score: 9
mandatory_overrides: [security, financial/legal]
override_applied: true
should_log: true
evidence_refs:
- fraud-metrics-dashboard
- risk-model-evaluation-report
policy_refs:
- aml-kyc-policy-v1
- payment-provider-risk-terms
validation_status: pendingThis is exactly the kind of decision that benefits from provenance:
- the trade-off is durable
- the reasoning will matter later
- the policy boundary matters
- future evidence may validate or invalidate the choice
Why keep decision-provenance-neo4j only as scaffolding for now
The current Neo4j backend is useful as scaffolding because it makes the edge model explicit early:
PARENT_OFINFORMSPARALLEL_TOSUPERSEDESCONFLICTS_WITHVALIDATED_BYINVALIDATED_BY
That is valuable for:
- testing the graph vocabulary
- thinking about migration
- proving that the record contract maps cleanly into graph storage
But for the long-term scaling direction in this guide, it is better to treat this Neo4j layer as scaffolding rather than the final memory product.
Scaling path: from Obsidian prototype to provenance MCP
Once the system grows, a stronger architecture is usually:
- vector storage for semantic retrieval of decision content
- graph storage for provenance, evolution, and typed decision relationships
- one MCP or service layer that exposes both capabilities through one consistent interface
A concrete example would be:
pgvectorfor embeddings and semantic search over decision contentNeo4jfor decision evolution, lineage, validation, and conflict structure- a provenance MCP that orchestrates retrieval, writes, updates, and cross-store synchronization
Why this hybrid approach matters:
- vectors are strong for semantic similarity
- vectors alone are weak at preserving explicit evolution and traceable relationships
- graphs are strong for lineage, causality, and state transitions
- the combination is closer to real organizational memory than either layer alone
This scaling direction is aligned with the argument made in the following provenance-manifesto essays:
- From RAG to Provenance: How We Realized Vector Alone Is Not Memory argues that vector retrieval is a useful entry point, but not enough to function as real memory on its own.
- From RAG to Provenance (Part 2): How Incremental Graph Memory Actually Learns extends that idea by showing why incremental graph memory is needed to preserve decision evolution, validation, conflict, and lineage over time.
In short:
- vector retrieval helps you find relevant prior decisions
- provenance structure preserves causality, evolution, and governance
Optional scaffolding backend
If you still want a graph-shaped backend during prototyping, keep it explicitly labeled as scaffolding:
Create .github/skills/decision-provenance-neo4j/SKILL.md:
---
name: decision-provenance-neo4j
description: Graph backend scaffolding for the decision-provenance interface using a Decision node plus typed edges.
---
# Decision Provenance Graph Backend
Use this backend to prototype graph storage semantics and migration paths.
## Node
(:Decision {
decision_id: String,
agent: String,
date: String,
decision: String,
bounded_context_domain: String,
bounded_context_scope: String,
context_version: String,
confidence: String,
validation_status: String
})
## Relationships
- [:PARENT_OF] parent -> child
- [:INFORMS] prior -> current
- [:PARALLEL_TO] bidirectional
- [:SUPERSEDES] newer -> older
- [:CONFLICTS_WITH] bidirectional
- [:VALIDATED_BY] decision -> later
- [:INVALIDATED_BY] decision -> later
## Use
- keep the abstract provenance schema unchanged
- treat this backend as migration scaffolding
- plan to replace it later with a provenance MCP that combines semantic retrieval and graph provenanceStep 5. Add a decision template
Create provenance/decisions/_template.md:
---
decision_id: dec-YYYY-MM-DD-agent-slug
agent: <agent-name>
decision_owner: <person|team|agent>
owner_role: <role or accountable function>
approved_by: ""
approved_by_role: ""
date: <ISO-8601 timestamp>
decision: <what was decided>
bounded_context:
domain: <domain>
scope: <scope>
context_version: v1
invariants:
- <rule>
reasoning: <why it was decided>
considered_alternatives:
- <option A>
rejected_alternatives:
- alternative: <option>
reason: <why rejected>
assumptions:
- <assumption>
risks_accepted:
- <risk>
caveats:
- <qualifier>
evidence_gaps:
- <gap>
evidence_refs:
- <ref>
policy_refs:
- <ref>
threshold_check:
threshold_policy_ref: decision-logging-threshold/v1
impact_radius: 0
reversibility: 0
uncertainty: 0
tradeoff_intensity: 0
longevity: 0
decision_score: 0
mandatory_overrides: []
override_applied: false
usefulness_gate: true
should_log: true
rationale: <short reason>
confidence: medium
confidence_basis: <why this confidence level is justified>
decision_links:
parent: ""
informs: []
supersedes: []
conflicts_with: []
parallel_to: []
validated_by: []
invalidated_by: []
validation_plan:
signals:
- <signal>
check_window: <window>
validation_status: pending
review_by: ""
refresh:
status: active
triggers: []
last_reviewed_at: ""
superseded_by: ""
outcome: pending
incidents: []
evolution_log:
- date: <ISO-8601>
change: Initial decision
tags:
- decision
- agent/<agent-name>
- domain/<domain>
- status/pending
---Step 6. Add a sample agent
Create .github/agents/decision-advisor.agent.md:
---
name: decision-advisor
description: Decision-focused agent that retrieves priors, makes a recommendation, and logs major decisions.
tools: ['read', 'search', 'edit']
---
Use the `decision-logging-threshold` skill.
Use the `decision-provenance` skill.
Use the `decision-provenance-obsidian` skill.
You are a decision-focused agent.
## Workflow
1. Retrieve prior decisions before deciding.
2. Compare bounded context before reusing a prior.
3. Return one primary recommendation.
4. Include alternatives, rejection reasons, assumptions, accepted risks, and confidence.
5. Run the threshold check.
6. If the decision qualifies, write it through the active backend.
7. Return decision_trace_ids in notes.
8. If later evidence arrives, update the decision record.
## Output shape
status: success|failed
agent: decision-advisor
summary: one-line outcome
result:
recommendation: <primary decision>
rationale: <why>
alternatives:
- option: <alternative>
rejected_because: <reason>
assumptions:
- <assumption>
risks_accepted:
- <risk>
validation_plan:
signals:
- <signal>
check_window: <window>
notes:
- decision_trace_ids: [dec-...]
- prior decisions consulted: [dec-...]Minimal End-to-End Example
Imagine your agent is asked:
Should we launch a feature today with known medium-severity bugs, or delay one week and miss a contractual milestone?Retrieval request
domain: product
scope: launch-risk-review
keywords:
- feature launch
- medium bugs
- contractual milestoneCandidate threshold result
threshold_check:
threshold_policy_ref: decision-logging-threshold/v1
impact_radius: 2
reversibility: 1
uncertainty: 1
tradeoff_intensity: 2
longevity: 1
decision_score: 7
mandatory_overrides: []
override_applied: false
usefulness_gate: true
should_log: true
rationale: Launch trade-off has cross-team impact and is likely to matter later.Logged decision sketch
decision: "Delay the release by one week and ship only after the medium-severity bugs are addressed."
decision_owner: release-governance-group
owner_role: release-accountability
approved_by: product-delivery-lead
approved_by_role: human-approver
bounded_context:
domain: product
scope: launch-risk-review
context_version: v1
invariants:
- Contractual commitments matter, but known user harm should not be normalized.
assumptions:
- The bugs materially affect customer trust or usability.
risks_accepted:
- The organization may miss the contractual milestone.
caveats:
- If the bugs are narrowly scoped and a safe rollout ring is available, this prior may not transfer unchanged.
validation_plan:
signals:
- Post-fix defect trend
- Customer support volume after launch
check_window: 14 daysAgent return notes
notes:
- decision_trace_ids: [dec-2026-03-28-decision-advisor-launch-delay-vs-bug-risk]
- prior decisions consulted: [dec-2026-03-14-decision-advisor-rollout-risk-policy]Why This Design Works
This design works because it turns decision-making into a small, inspectable protocol:
- Retrieve priors
- Decide
- Score significance
- Persist if worthy
- Revisit later when evidence changes
That gives you five useful properties:
- reuse: agents do not start from zero every time
- selectivity: not all chatter becomes memory
- context safety: old decisions are not blindly reused
- auditability: decisions preserve why, not only what
- evolution: later evidence can change the record without erasing history
Conceptual Basis in FPF
This pattern is not a full implementation of the First Principles Framework. It is a practical adaptation of a few ideas that map very well to agent memory.
Bounded context
FPF describes U.BoundedContext as the main way to create a local closed world for reliable engineering decisions. That is why the provenance schema includes:
- domain
- scope
- context_version
- invariants
Reference: FPF bounded context discussion
Thinking through writing
FPF treats durable forms such as records as part of the reasoning process, not as after-the-fact documentation. That maps directly to the decision record and update lifecycle.
Reference: FPF on thinking through writing and durable records
No thresholds in log
FPF says numeric gates and thresholds should be owned elsewhere and cited, not embedded into the logging layer. That is why this pattern splits:
- threshold policy
- provenance record
instead of mixing them.
Reference: FPF on keeping thresholds out of the logging layer
Avoid narrative-only provenance
FPF warns against provenance that is only a prose "because story." That is why the schema includes structured fields such as:
- evidence_refs
- policy_refs
- decision_links
- validation_plan
- refresh
Reference: FPF on explicit provenance pins and narrative-only provenance anti-patterns
Preserve caveats and uncertainty
FPF warns that cleaner prose must not silently remove caveats or strengthen certainty. That is why the schema explicitly keeps:
- caveats
- evidence_gaps
- confidence
- confidence_basis
- rejected alternatives
Reference: FPF on caveats, uncertainty, and silent confidence inflation
Practical Notes
Start with the file backend
The file backend is the easiest way to begin because it works with ordinary Markdown and can be reviewed by humans without extra infrastructure.
Add the graph backend when your decision volume grows
Once you have many decisions, graph traversal becomes useful for questions like:
- which prior decisions informed this one
- what decisions were later invalidated
- what patterns repeat across agents or domains
Keep the schema stable
If you want multiple agents or multiple backends, keep the abstract record stable and only change the persistence layer.
Porting to other agent frameworks
If you are not using GitHub Copilot, keep the same logical split and just rename the implementation units:
- global instructions become your framework's shared system prompt or project policy layer
- agent profiles become role definitions, workers, or specialized assistants
- skills become reusable prompt contracts, tool policies, or callable modules
- backend skills become persistence adapters
What should stay stable is not the packaging, but the contract:
- one threshold owner
- one canonical decision record
- one retrieval/write/update lifecycle
- one or more interchangeable storage backends
Afterword: How This Split Can Evolve
This split is a good starting point, not the final state.
Over time, you can evolve it in several directions.
Better graph model
The first graph version may only model decisions and edges between them. A stronger version can add:
- Incident nodes
- Evidence nodes
- Policy nodes
- Review or refresh events
- richer edge semantics such as
DERIVED_FROM,BLOCKED_BY, orPARTIALLY_VALIDATED_BY
That makes causal analysis and decision lineage much stronger.
Stronger evidence references
Today, many teams will begin with free-form evidence_refs. A more mature version can move toward:
- typed evidence ids
- trace ids
- document ids
- policy ids
- stronger citation rules
That makes provenance more machine-usable and less dependent on prose.
Automated refresh and staleness handling
The refresh block can later support:
- reminders for overdue review dates
- stale-decision detection
- automatic invalidation prompts after incidents
- dashboards showing which priors are still trustworthy
This direction is strongly aligned with FPF's refresh and decay governance model.
Reference: FPF on refresh governance and debt-by-prose anti-patterns
Multi-backend publication
A mature system can publish the same logical decision record to:
- Markdown notes for humans
- Neo4j for graph analysis
- a search index for retrieval
- dashboards for governance reporting
Domain-specific threshold policies
Different domains may eventually need slightly different threshold tuning. If that happens, keep the same split:
- one threshold owner
- one provenance contract
- one or more backends
Do not push those threshold rules into the logging layer.
Framework-independent orchestration
As the system matures, the Copilot-specific packaging can be replaced or mirrored by:
- orchestration frameworks with explicit planner/worker roles
- agent SDKs with tool registries and memory modules
- workflow engines that separate retrieval, decision, logging, and review stages
At that point, the main value of this reference implementation is the contract and the boundary design, not the exact file layout.
Final Takeaway
If you want a practical provenance system for agents, keep the pattern simple:
- one skill decides whether a decision matters
- one skill defines what a reusable decision record looks like
- one backend stores it
- agents retrieve priors first and update records when new evidence arrives
That gives you a portable, inspectable, and evolvable decision memory system that can start with Markdown and grow into a richer graph-based architecture later.
References
- First Principles Framework (FPF) - Core Conceptual Specification
- Author line: Anatoly Levenchuk and assortment of LLMs
- FPF bounded context discussion
- FPF on thinking through writing and durable records
- FPF on caveats, uncertainty, and silent confidence inflation
- FPF on explicit provenance pins and narrative-only provenance anti-patterns
- FPF on keeping thresholds out of the logging layer
- FPF on refresh governance and debt-by-prose anti-patterns
- From RAG to Provenance: How We Realized Vector Alone Is Not Memory
- From RAG to Provenance, Part 2: How Incremental Graph Memory Actually Learns
- Architectural Decision Records (ADR) overview
- Google Cloud: Architecture decision records overview
- Microsoft Learn: Maintain an architecture decision record (ADR)
- AWS Well-Architected: Evaluate tradeoffs while managing benefits and risks
- AWS Executive Insights: one-way door and two-way door decision model
- AWS Prescriptive Guidance: reversible vs irreversible data-driven actions
- NIST: Risk-based decision making for sustainable and resilient infrastructure
- NIST: Incorporating Attribute Value Uncertainty into Decision Analysis
- GitHub Docs: About custom agents
- GitHub Docs: Creating custom agents for Copilot coding agent
- GitHub Docs: Custom agents configuration
- GitHub Docs: Your first custom instructions
- GitHub Docs: Support for different types of custom instructions
- GitHub Docs: Overview of customizing GitHub Copilot CLI
- GitHub Docs: Best practices for GitHub Copilot CLI
- GitHub Docs: Best practices for using GitHub Copilot